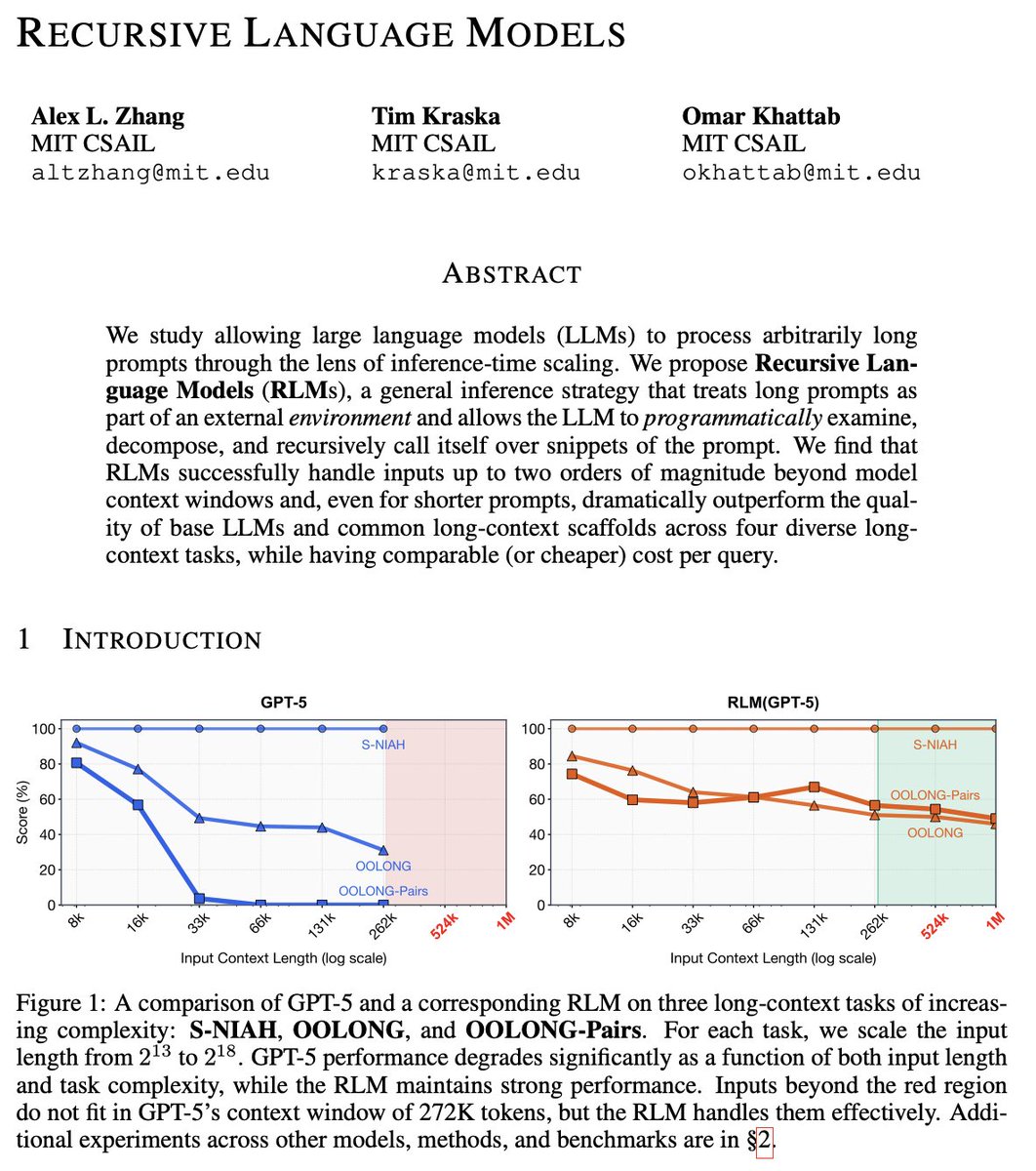
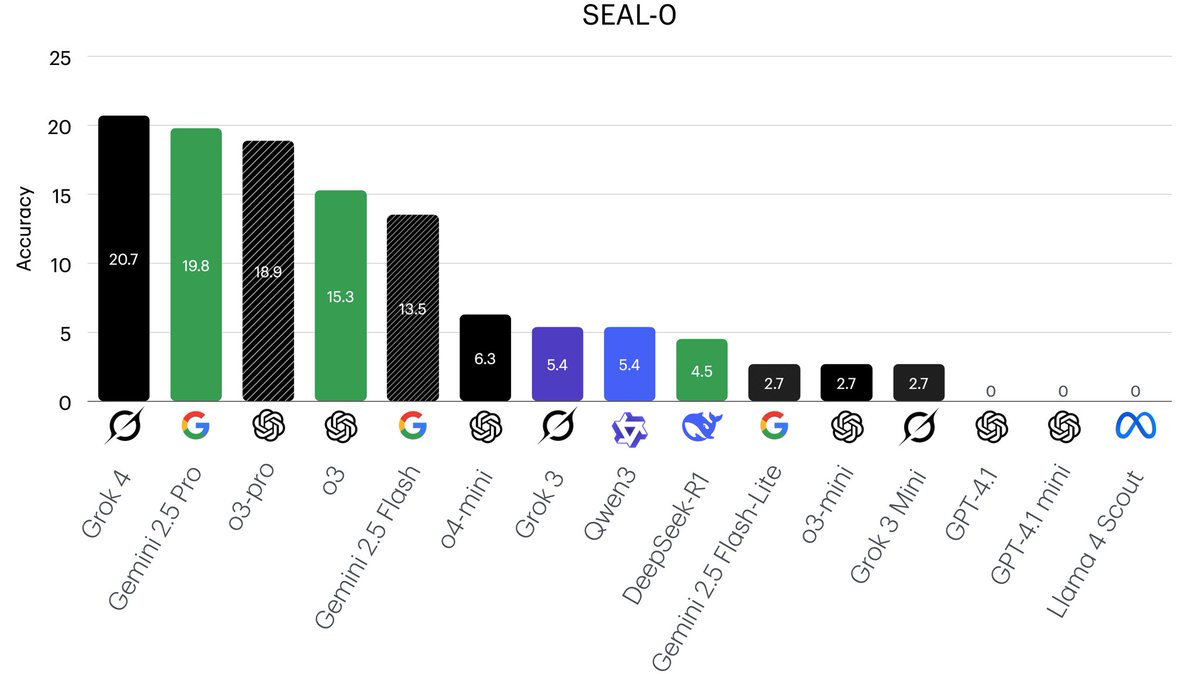
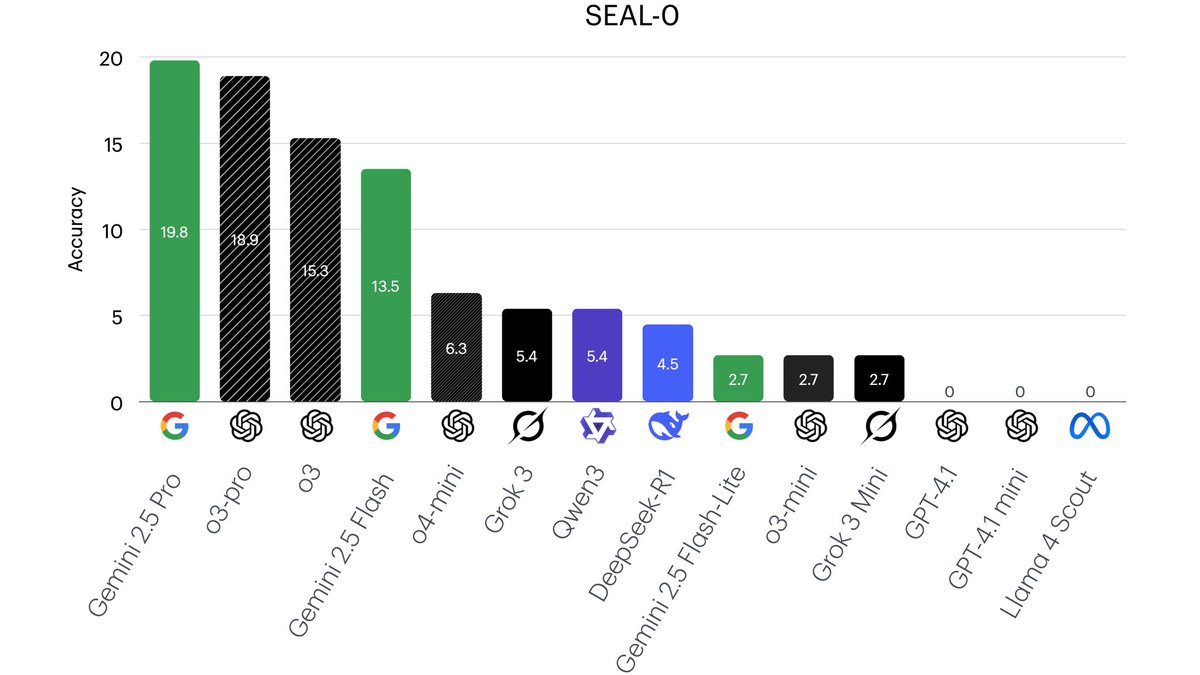
Thinh retweeté

Very impressive results from Chroma Context-1, which push the Pareto frontier of agentic search on our SealQA (Seal-0) & LongSealQA benchmarks. Check out their techical report below 👇
trychroma.com/research/conte…
Chroma@trychroma
Introducing Chroma Context-1, a 20B parameter search agent. > pushes the pareto frontier of agentic search > order of magnitude faster > order of magnitude cheaper > Apache 2.0, open-source
English