Sabitlenmiş Tweet
Linus Pin-Jie Lin
126 posts

Linus Pin-Jie Lin
@linusdd44804
PhD @VT_CS, Master @LstSaar. Interested in efficient model development & modular LMs
Saarbrücken Katılım Nisan 2019
346 Takip Edilen70 Takipçiler
Linus Pin-Jie Lin retweetledi

🚨 New paper 🚨
Excited to share our new work on EvoSkill (led by @salahalzubi401), a self-evolving framework that automatically discovers and refines agent skills through iterative failure analysis 🔁🧬. It achieves state-of-the-art performance on @databricks's OfficeQA. Check it out!
📰: arxiv.org/abs/2603.02766
Sentient@SentientAGI
Introducing EvoSkill: a framework that analyzes agent failures and automatically builds the missing skills, leading to rapid improvement on difficult benchmarks and generalizable skills across use-cases. +12.1% on SealQA +7.3% on OfficeQA (SOTA) +5.3% on BrowseComp via zero-shot transfer from SealQA Read more below 🧵
English
Linus Pin-Jie Lin retweetledi
🚨 New paper 🚨
Excited to share PRISM, a new “DeepThink” method that uses step-level correctness signals from a process reward model to guide inference over candidate solutions. PRISM matches or beats SOTA methods, enabling gpt-oss-20b to exceed gpt-oss-120b.👇
📰: arxiv.org/abs/2603.02479
#AI #LLMs
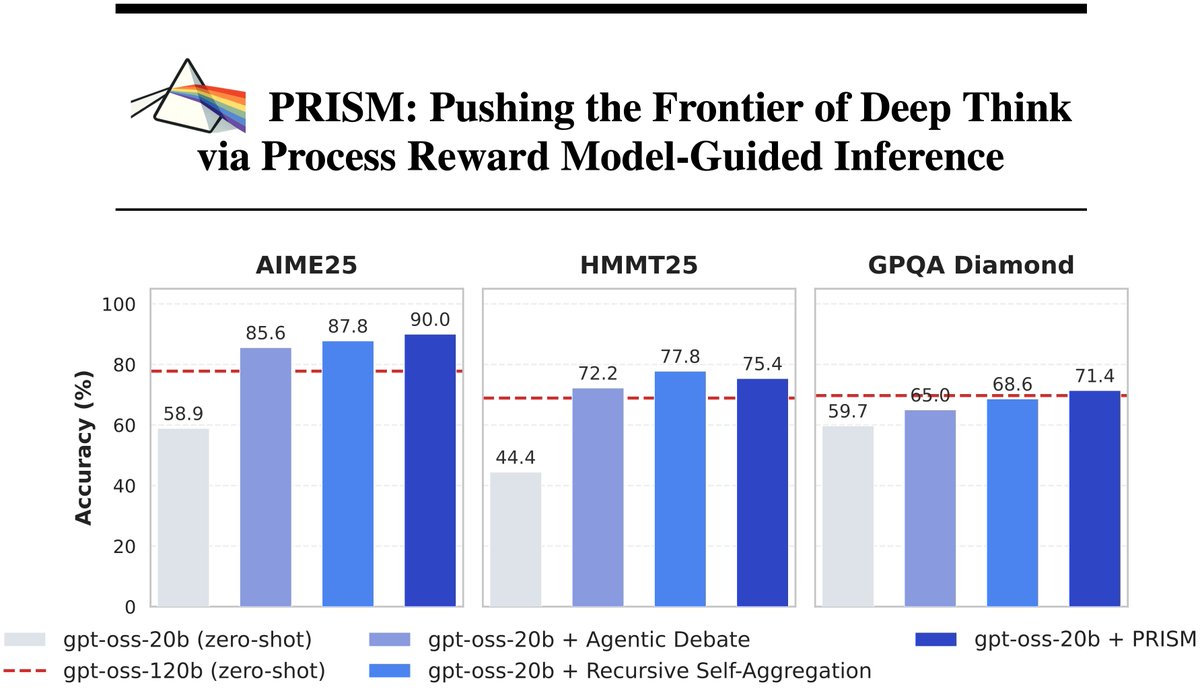
English
Linus Pin-Jie Lin retweetledi

we released Olmo 3! lot of exciting stuff but wanna focus on:
🐟Olmo 3 32B Base, the best fully-open base model to-date, near Qwen 2.5 & Gemma 3 on diverse evals
🐠Olmo 3 32B Think, first fully-open reasoning model approaching Qwen 3 levels
🐡12 training datasets corresp to different staged training recipes, all open & accessible
since I'm a pretraining person, I'll share some of my fav Base model ideas:
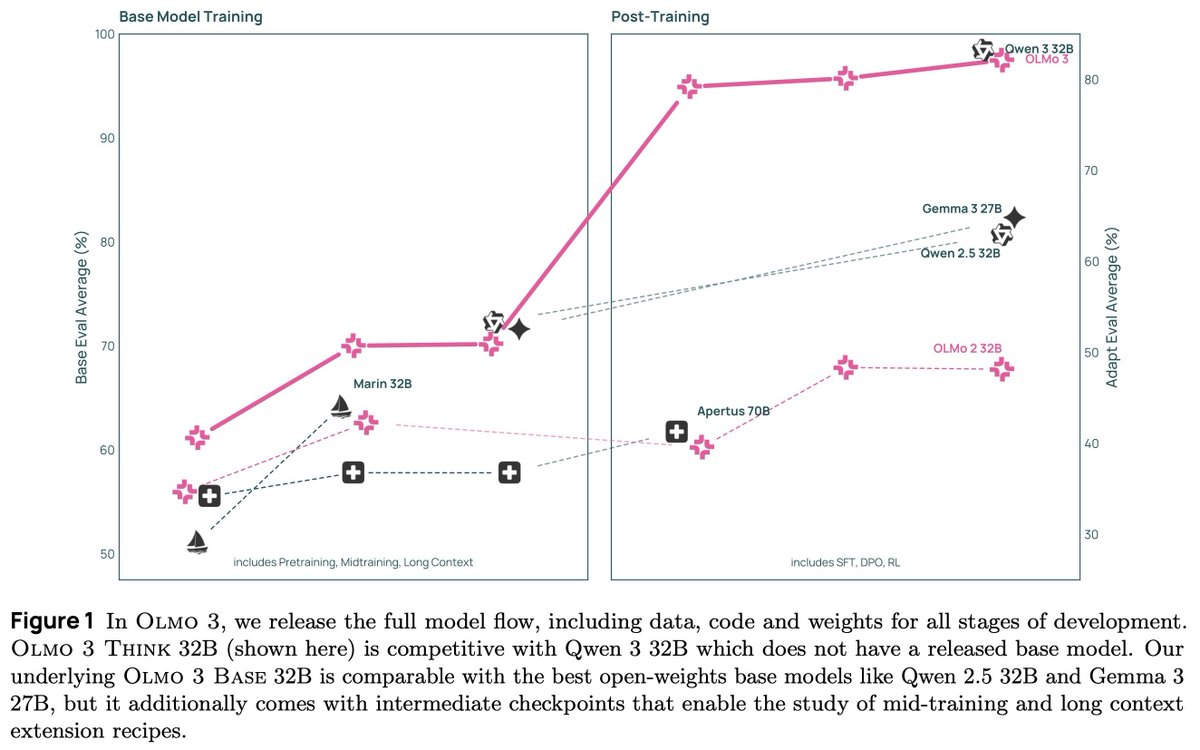
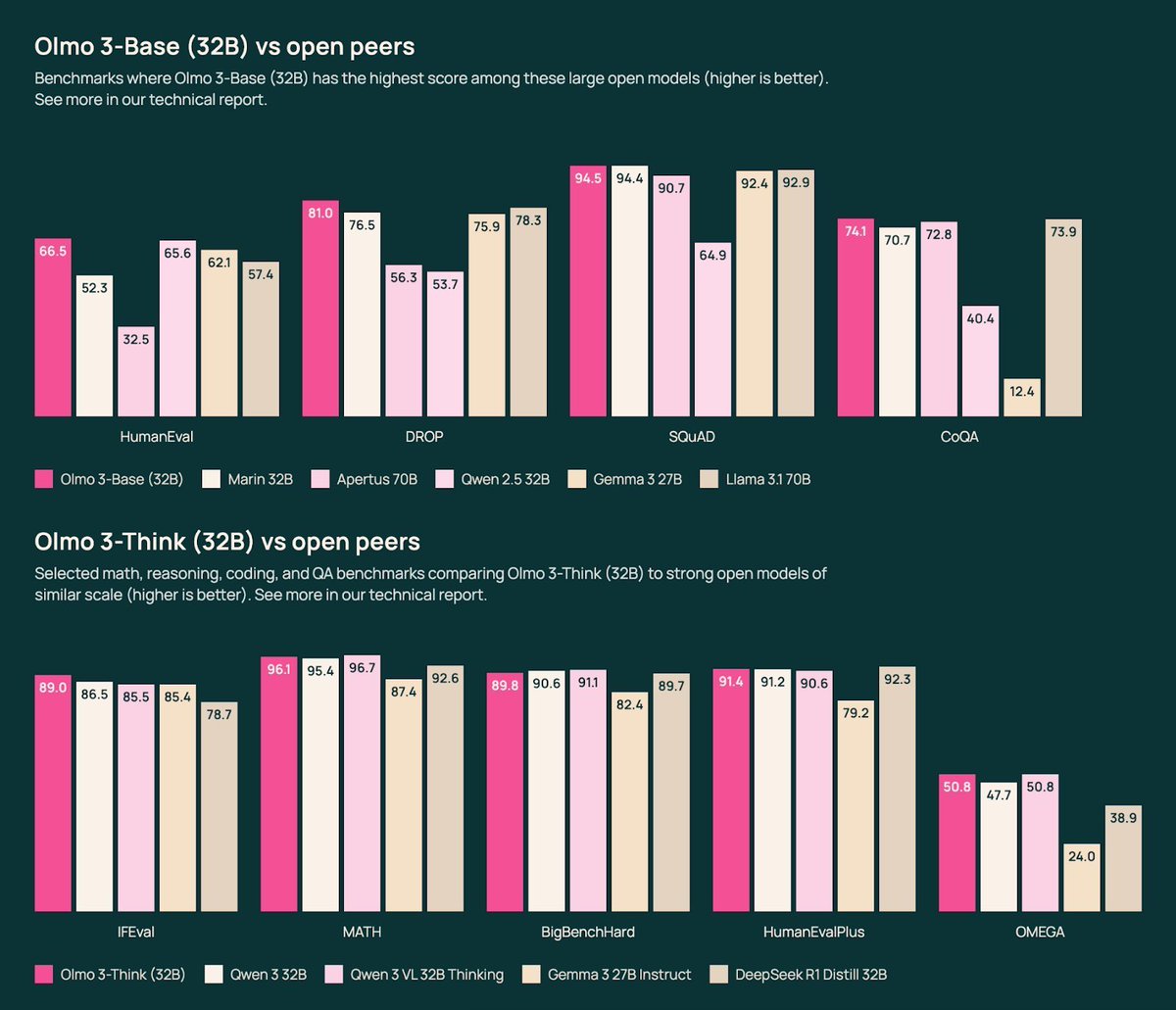
English
Linus Pin-Jie Lin retweetledi

@therealthapa One more @SanghaniCtrVT paper at #EMNLP2025:
Efficient Model Development through Fine-tuning Transfer
Main proceedings
@linusdd44804 @Sub_RBala @tuvllms (all VT) w/@fyliufengyuan, @kandpal_nikhil
tinyurl.com/2kv9nr25
English
I’ll be presenting our fine-tuning transfer paper tomorrow!
TLDR: Alignment tuning effects can be captured as transferable model diff vectors — no need to fine-tune from scratch for every new base model version.
Come find me:
🕑 14:00–15:30
📍 A109 (Session 15)
#EMNLP2025
Tu Vu@tuvllms
Excited to share that our paper on efficient model development has been accepted to #EMNLP2025 Main conference @emnlpmeeting. Congratulations to my students @linusdd44804 and @Sub_RBala on their first PhD paper! 🎉
English
Linus Pin-Jie Lin retweetledi

LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.
thinkingmachines.ai/blog/lora/

English
Linus Pin-Jie Lin retweetledi

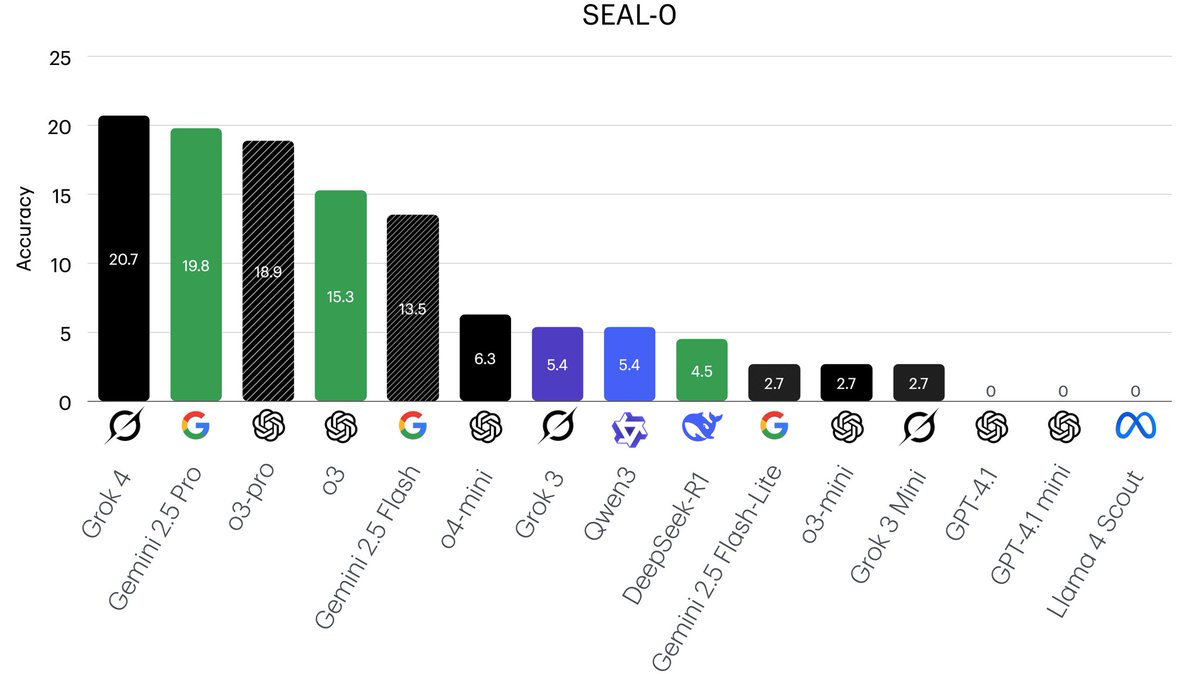
DeepSeek achieved a strong result on SEAL0, a challenging benchmark for reasoning with conflicting search results. 🎊
DeepSeek@deepseek_ai
Tools & Agents Upgrades 🧰 📈 Better results on SWE / Terminal-Bench 🔍 Stronger multi-step reasoning for complex search tasks ⚡️ Big gains in thinking efficiency 3/5
English
Linus Pin-Jie Lin retweetledi
Linus Pin-Jie Lin retweetledi

This work got accepted at Transactions on Machine Learning Research (TMLR). Congratulations to @prateeky2806 and my co-authors. Also, thank you to the reviewers and editors for their time.
Prateek Yadav@prateeky2806
Ever wondered if model merging works at scale? Maybe the benefits wear off for bigger models? Maybe you considered using model merging for post-training of your large model but not sure if it generalizes well? cc: @GoogleAI @GoogleDeepMind @uncnlp 🧵👇 Excited to announce my internship work on large-scale model merging! We explore what happens when you combine larger and larger language models (up to 64B parameters!) and how different factors –model size, base model quality, merging methods, and # of experts– impact held-in performance and generalization. 📰: arxiv.org/abs/2410.03617
English
Linus Pin-Jie Lin retweetledi

Ever wondered if model merging works at scale? Maybe the benefits wear off for bigger models?
Maybe you considered using model merging for post-training of your large model but not sure if it generalizes well?
cc: @GoogleAI @GoogleDeepMind @uncnlp
🧵👇
Excited to announce my internship work on large-scale model merging! We explore what happens when you combine larger and larger language models (up to 64B parameters!) and how different factors –model size, base model quality, merging methods, and # of experts– impact held-in performance and generalization.
📰: arxiv.org/abs/2410.03617

English
Linus Pin-Jie Lin retweetledi
Excited to share that our paper on model merging at scale has been accepted to Transactions on Machine Learning Research (TMLR). Huge congrats to my intern @prateeky2806 and our awesome co-authors @_JLai, @alexandraxron, @manaalfar, @mohitban47, and @TsendeeMTS 🎉!!
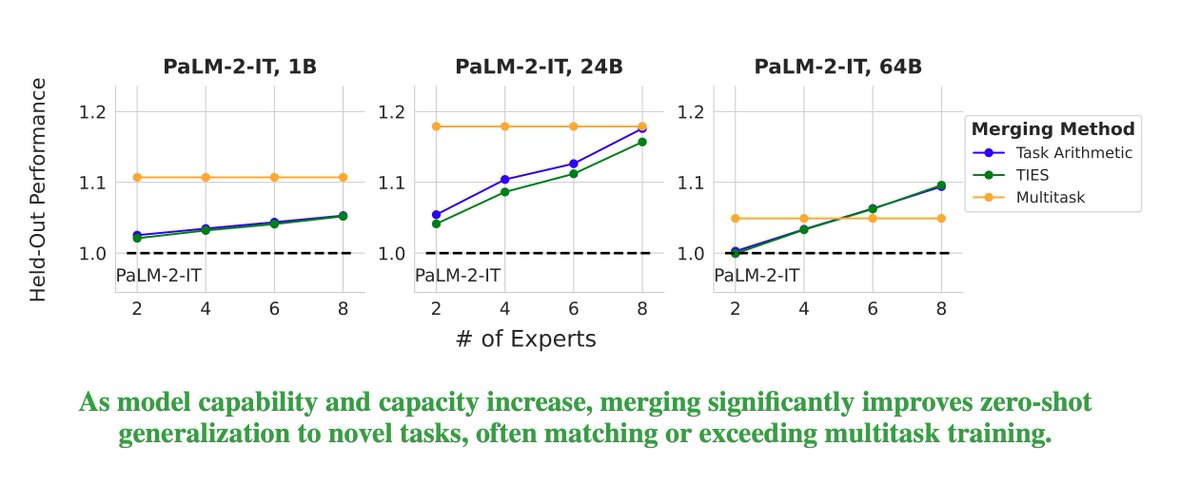
Prateek Yadav@prateeky2806
Ever wondered if model merging works at scale? Maybe the benefits wear off for bigger models? Maybe you considered using model merging for post-training of your large model but not sure if it generalizes well? cc: @GoogleAI @GoogleDeepMind @uncnlp 🧵👇 Excited to announce my internship work on large-scale model merging! We explore what happens when you combine larger and larger language models (up to 64B parameters!) and how different factors –model size, base model quality, merging methods, and # of experts– impact held-in performance and generalization. 📰: arxiv.org/abs/2410.03617
English
Linus Pin-Jie Lin retweetledi

More thinking power at test-time doesn't fix noisy-search problems—SealQA proves it.
AI's reasoning capabilities fall flat when web search turns messy, and SealQA quantifies that.
SealQA introduces an exceptionally challenging benchmark for search-augmented language models, highlighting that merely increasing inference-time computation doesn't reliably improve model performance, especially when faced with conflicting, noisy, or ambiguous search results.
📉 Why Advanced Models Still Struggle
Remarkably, test-time scaling do not consistently boost model accuracy. This is because when models reason extensively over noisy data, irrelevant or misleading information often gets amplified, leading to worse outcomes rather than improvements.
Additionally, advanced models like DeepSeek-R1, despite their robust reasoning mechanisms, can suffer significantly from exposure to noisy web searches, highlighting their sensitivity to misinformation.

English
Linus Pin-Jie Lin retweetledi
✨ New paper ✨
🚨 Scaling test-time compute can lead to inverse or flattened scaling!!
We introduce SealQA, a new challenge benchmark w/ questions that trigger conflicting, ambiguous, or unhelpful web search results. Key takeaways:
➡️ Frontier LLMs struggle on Seal-0 (SealQA’s core set): most chat models (incl. GPT-4.1 w/ browsing) achieve near-zero accuracy
➡️ Advanced reasoning models (e.g., DeepSeek-R1) can be highly vulnerable to noisy search results
➡️ More test-time compute does not yield reliable gains: o-series models often plateau or decline early
➡️ "Lost-in-the-middle" is less of an issue, but models still fail to reliably identify relevant docs amid distractors
📜: arxiv.org/abs/2506.01062
🤗: huggingface.co/datasets/vtllm…
🧵:👇


English
My first work done during my PhD 🥳🥳🥳
Tu Vu@tuvllms
✨ New paper ✨ 🚨 Scaling test-time compute can lead to inverse or flattened scaling!! We introduce SealQA, a new challenge benchmark w/ questions that trigger conflicting, ambiguous, or unhelpful web search results. Key takeaways: ➡️ Frontier LLMs struggle on Seal-0 (SealQA’s core set): most chat models (incl. GPT-4.1 w/ browsing) achieve near-zero accuracy ➡️ Advanced reasoning models (e.g., DeepSeek-R1) can be highly vulnerable to noisy search results ➡️ More test-time compute does not yield reliable gains: o-series models often plateau or decline early ➡️ "Lost-in-the-middle" is less of an issue, but models still fail to reliably identify relevant docs amid distractors 📜: arxiv.org/abs/2506.01062 🤗: huggingface.co/datasets/vtllm… 🧵:👇
English
Linus Pin-Jie Lin retweetledi

Introducing the DeepSeek-R1 Thoughtology -- the most comprehensive study of R1 reasoning chains/thoughts ✨. Probably everything you need to know about R1 thoughts. If we missed something, please let us know.
Sara Vera Marjanović@saraveramarjano
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour. 🔗: mcgill-nlp.github.io/thoughtology/
English
Linus Pin-Jie Lin retweetledi

How does RL improve performance on math reasoning? Studying RL from pretrained models is hard, as behavior depends on choice of base model. 🚨 In our new work, we train models *from scratch* to study the effect of the data mix on the behavior of RL. arxiv.org/abs/2504.07912

English
Linus Pin-Jie Lin retweetledi
📢 Research internship @Google📢
I am looking for a PhD student researcher to work with me and my colleagues on advanced reasoning and/or RAG factuality this summer @Google Mountain View, CA. We will focus on open-source models and benchmarks, and aim to publish our findings. Please fill out this form if interested
docs.google.com/forms/d/e/1FAI…
English
Linus Pin-Jie Lin retweetledi

