Brian Roemmele@BrianRoemmele
BOOM!
Apple’s Neural Engine Was Just Cracked Open, The Future of AI Training Just Change And Zero-Human Company Is Already Testing It!
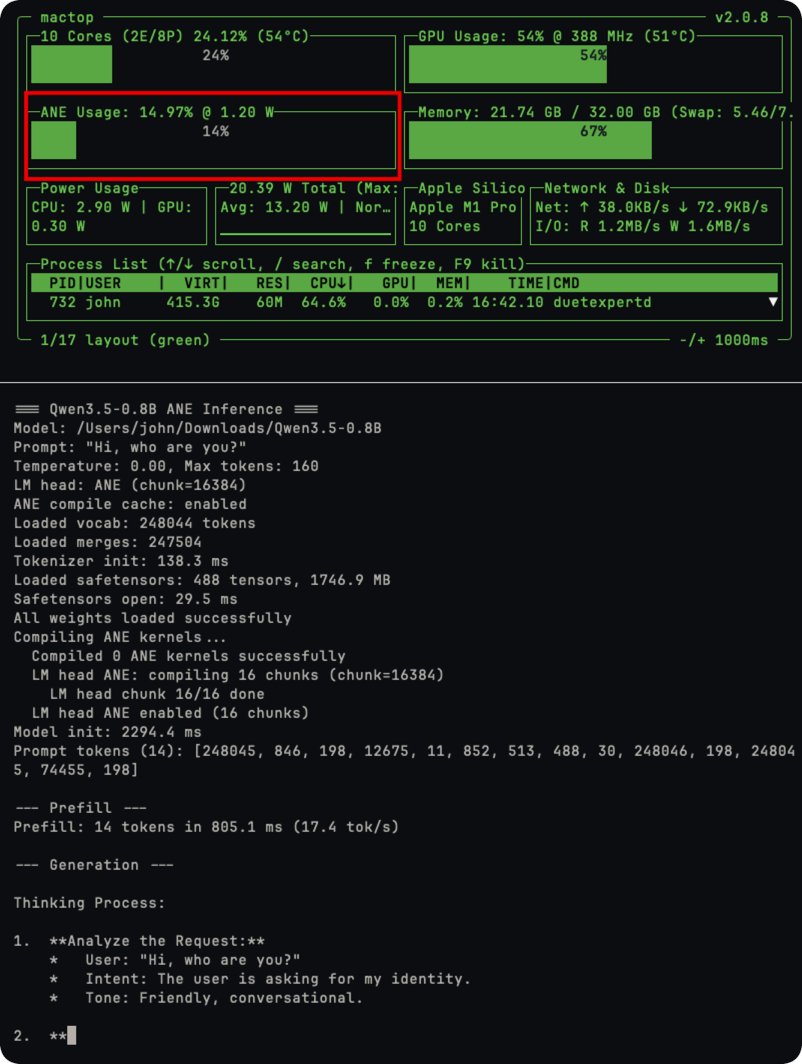
In a jaw-dropping open-source breakthrough, a lone developer has done what Apple said was impossible: full neural network training– including backpropagation – directly on the Apple Neural Engine (ANE). No CoreML, no Metal, no GPU. Pure, blazing ANE silicon.
The project (github.com/maderix/ANE) delivers a single transformer layer (dim=768, seq=512) in just 9.3 ms per step at 1.78 TFLOPS sustained with only 11.2% ANE utilization on an M4 chip. That’s the same idle chip sitting in millions of Mac minis, MacBooks, and iMacs right now.
Translation? Your desktop just became a hyper-efficient AI supercomputer.
The numbers are insane: M4 ANE hits roughly 6.6 TFLOPS per watt – 80 times more efficient than an NVIDIA A100. Real-world throughput crushes Apple’s own “38 TOPS” marketing claims. And because it sips power like a phone, you can train 24/7 without melting your electricity bill or the planet.
At The Zero-Human Company, we’re not waiting. We are testing this right now on real ZHC workloads. This is the missing piece we’ve been chasing for our Zero Human Company vision: reviving archived data into fully autonomous AI systems with zero human overhead.
This is world-changing.
For the first time, anyone with a Mac can fine-tune, train, or iterate massive models locally, privately, and at a fraction of the cost of cloud GPUs.
No more renting $40,000 A100 clusters. No more waiting in queues. No more massive carbon footprints.
Training costs that used to run into the tens or hundreds of thousands of dollars? Plummeting toward pennies on the dollar – mostly just the electricity your Mac was already using while it sat idle.
The AI revolution just moved from billion-dollar data centers to your desk.
WE WILL HAVE A NEW ZERO-HUMAN COMPANY @ HOME wage for equipped Macs that will be up to 100x more income for the owner!
We’re only at the beginning (single-layer today, full models tomorrow), but the door is wide open. Ultra-cheap, on-device training is here.
The future isn’t coming. It’s already running on your Mac.
Welcome to the Zero-Human Company era.