
10T…. Ya I can run that locally 😎
Elon Musk@elonmusk
SpaceXAI Colossus 2 now has 7 models in training: - Imagine V2 - 2 variants of 1T - 2 variants of 1.5T - 6T - 10T Some catching up to do.
English
Sander Blue
8.7K posts

@SanderBlue
AI Software Engineer building private AI. Stock Market Algos w/ @TradersPostInc Obsessed with snow ❄ and mountains 🏔 ⏻ https://t.co/slZMz9KT3k
SpaceXAI Colossus 2 now has 7 models in training: - Imagine V2 - 2 variants of 1T - 2 variants of 1.5T - 6T - 10T Some catching up to do.





SOMEONE MADE A DIGITAL WHIP TO MAKE CLAUDE WORK FASTER 💀
The highest quality video of the moon was just released… this is so beautiful.
@NASAAdmin @NASA What the first photos of the dark side of the moon will show






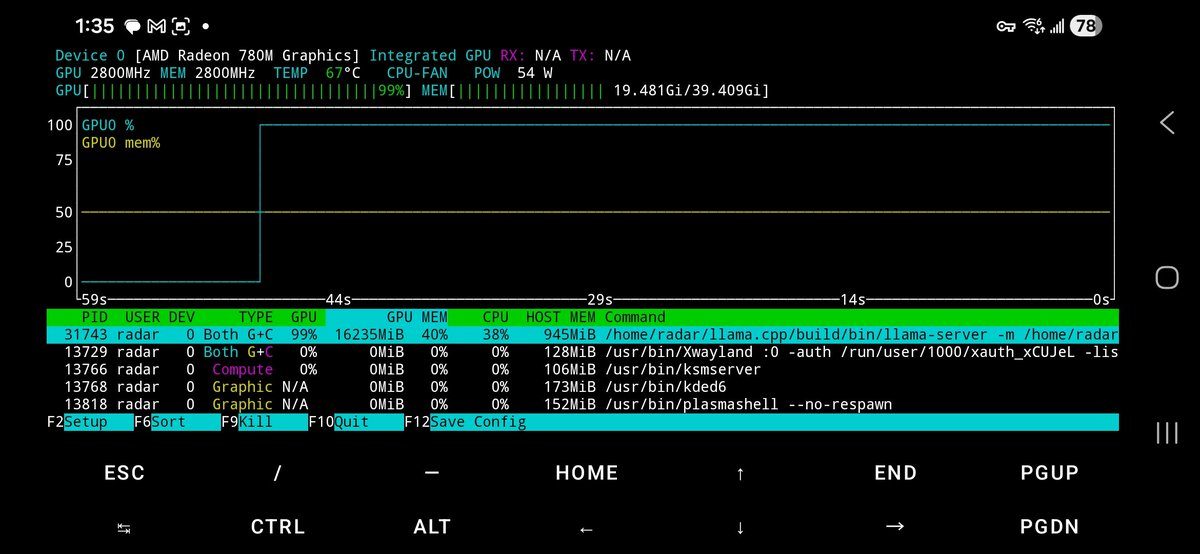


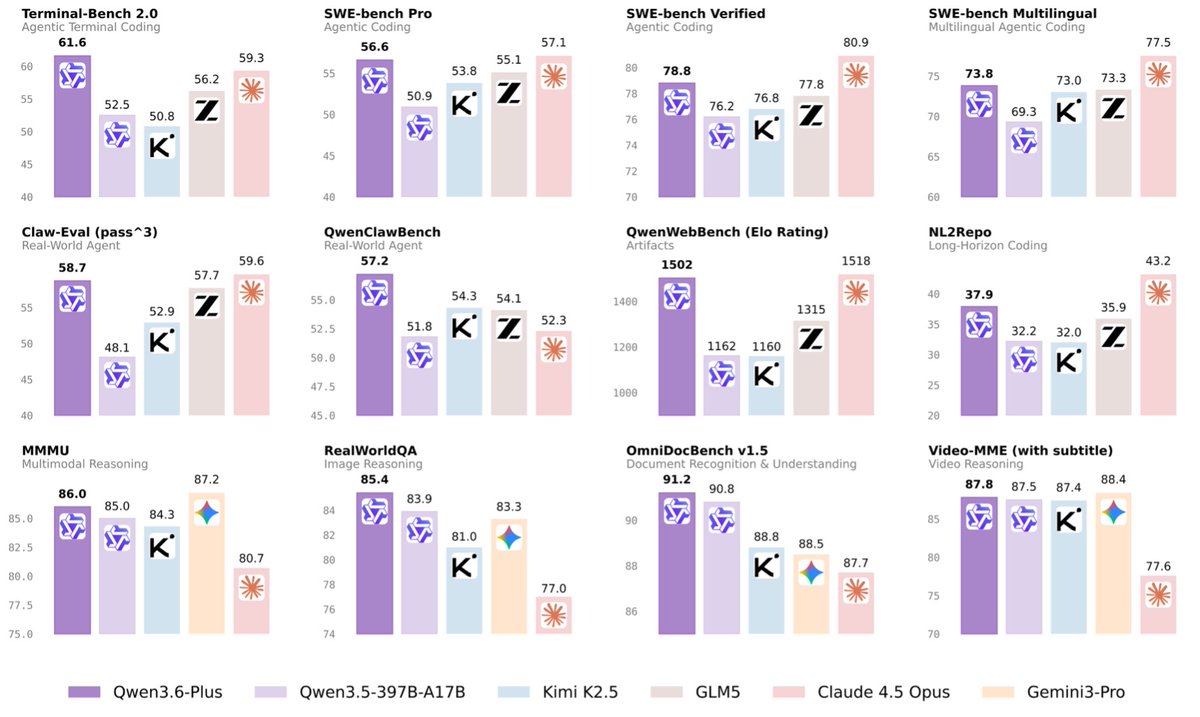


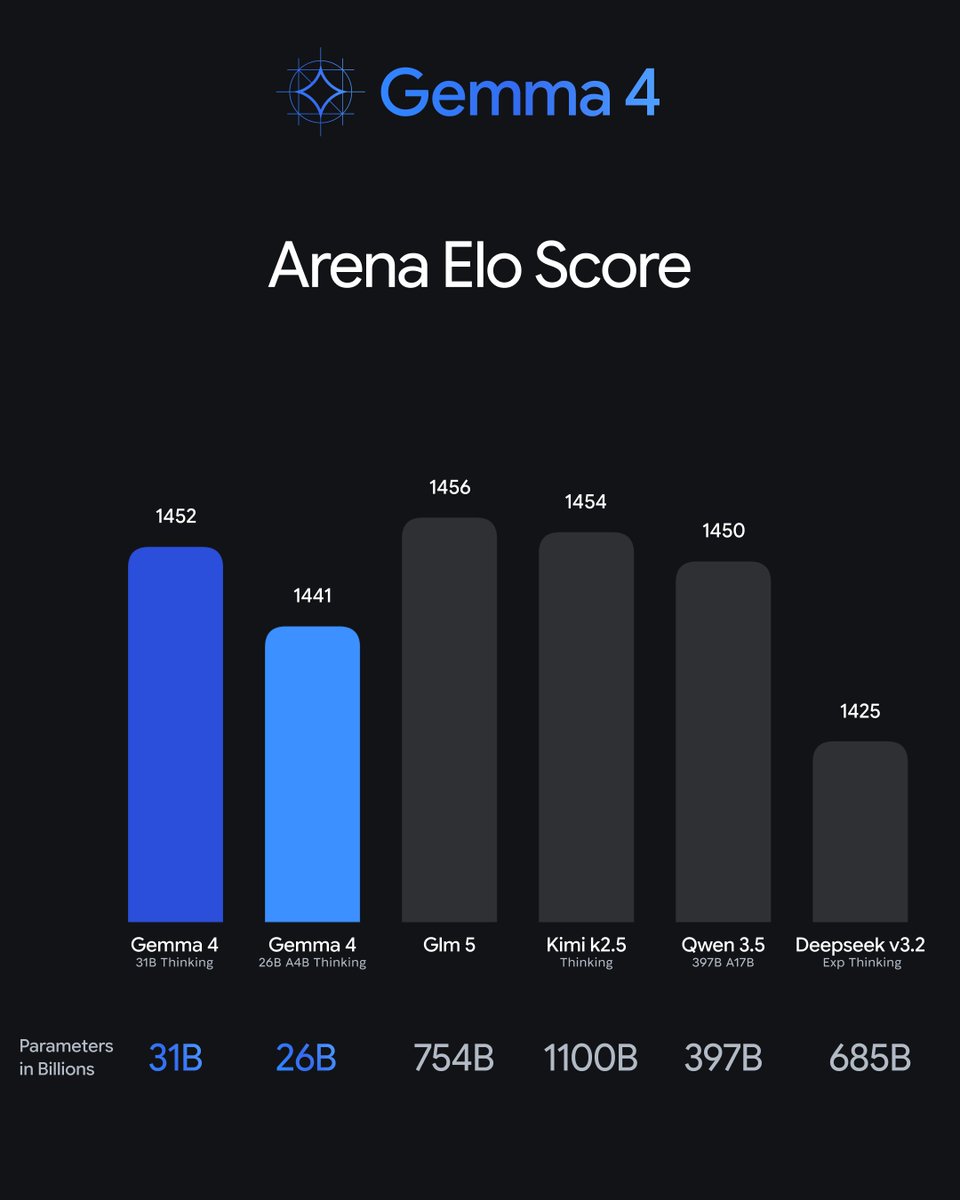
Meet Gemma 4: our new family of open models you can run on your own hardware. Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵