पिन किया गया ट्वीट

Sometime dreaming is a thinking game,
openreview.net/forum?id=HHsD9…
English
Xiaoliu.x
231 posts

@xiaolGo
ex-algo engineer → architect → founder → researcher → ? My reading list: https://t.co/raW6A7xfMS https://t.co/b0JOLNr4bE

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees. The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance. Access to all other Claude models is not affected. We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible. Read our full statement: anthropic.com/news/fable-myt…






RWKV-7 G1g is here: the world's best pure RNN LLM, and a competitive LLM in general. Try huggingface.co/spaces/BlinkDL… for bsz16 7B inference. G1h in June 🙂 p.s. const 15000+tps decoding on single 5090: github.com/BlinkDL/Albatr…


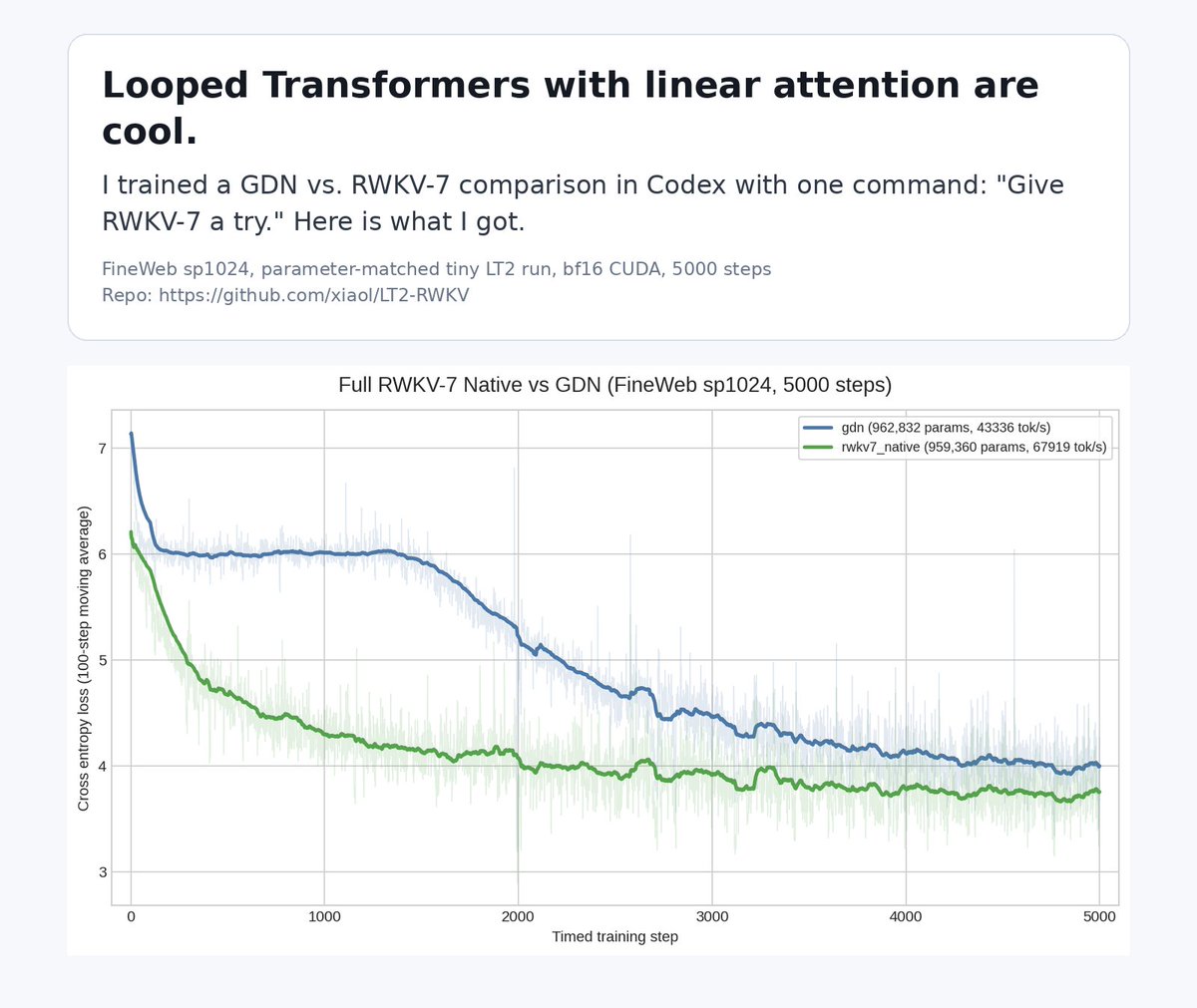
Gated DeltaNet-2 is almost exactly RWKV-7's DPLR recurrence, not acknowledging the elephant in the room 🙂
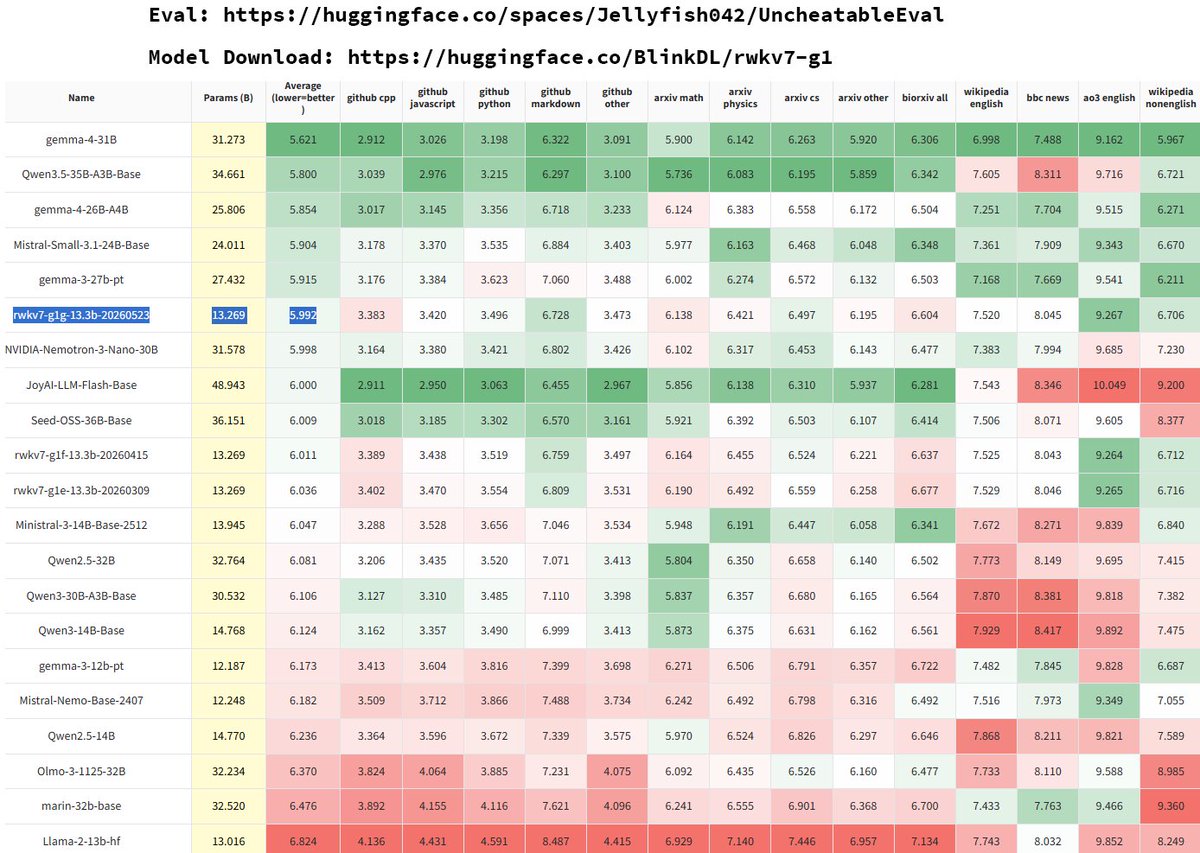
RWKV-7 G1f is here (13B/7B/3B/1B) and G1g in May. p.s. Gemma 4 is great at "uncheatable eval" confirming its effectiveness 🙂 pity there's no Qwen3.5 27B base