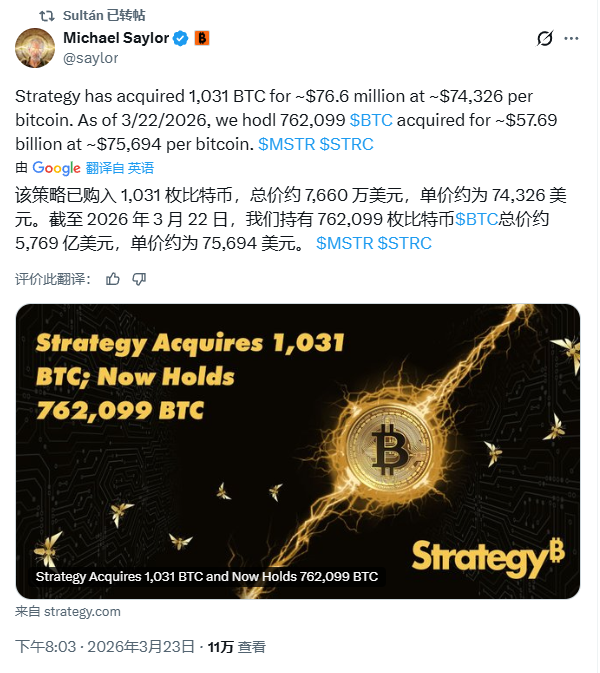
Tweet Disematkan


English
加密枫叶 BlockMaple
1.4K posts

@BlockMaple
🇨🇦Qs全球100在读 / All in Web3 / 🇨🇦永久居民 / 🇷🇺🇨🇦Factory 建设中ing/ 分享5年入圈心得 From dishwasher in 🇨🇦 at 20 → Now building decentralized futures TG:https://t.co/lBmgXjjX06







Just pushed some new docs (!) live for @gensynai's Reproducible Execution Environment (REE), their toolchain for bitwise-reproducible AI inference across any hardware. The problem it solves is deceptively simple: run the same model with the same inputs on two different machines, get the exact same output. Not approximately, not almost, but.. identically It turns out that's really difficult to do, because GPUs are non-deterministic by default, and existing solutions like PyTorch's deterministic mode can't get the job done the moment you switch hardware. REE solves this with custom GPU kernels (RepOps) that guarantee identical results everywhere. Every run produces a cryptographic receipt that anyone can independently verify. The docs cover everything from a quickstart to the internals of the MLIR compiler and RepOp kernel design. Check em out! -> docs.gensyn.ai/tech/ree

it's going to blow some people's minds when the vast majority of inference shifts on-device the consolidation of use cases and model types will move into the applications themselves, the models will get compressed, and we'll do far more locally than many people think possible
When you run the same AI model with the same inputs twice, you'd expect the same output. But modern GPU execution is optimised for speed, not fixed ordering, and existing determinism tools do not solve this across hardware. Today we're changing that. blog.gensyn.ai/ree/