
iamdev - building MnemeBrain
366 posts

iamdev - building MnemeBrain
@Iamdev_ai
Building MnemeBrain Belief memory for AI agents Contradictions • Evidence • Revision Think TCP/IP for agent memory https://t.co/v00LidyBpu
Netherlands Bergabung Kasım 2017
337 Mengikuti310 Pengikut

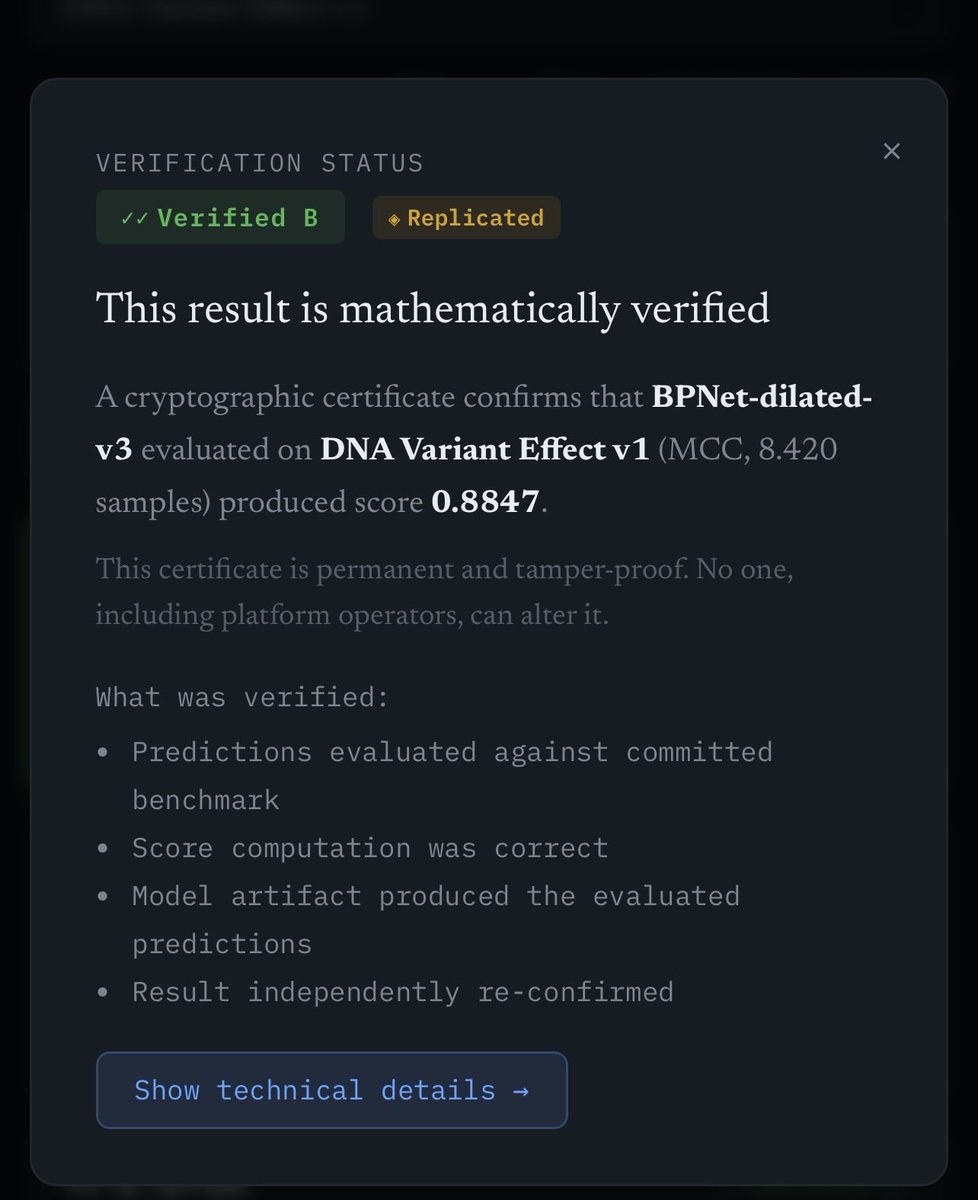
Coming soon: GenoMark.
Autoresearch at home.
ZK verification for every result.
Train locally, submit confidently, prove it cryptographically.
🧬⚡
@karpathy @ensue_ai @MinaFoundation @MinaDevelopers @MinaProtocol @minacryptocom
English
@boxmining Building MnemeBrain — a belief memory layer for AI agents.
Instead of storing text like RAG systems, agents store beliefs with evidence, contradictions, and revision over time.
Think TCP/IP for agent memory.
mnemebrain.ai

English

English
@X4AES @BLUECOW009 Exactly. The hard part isn’t storing memories — it’s how new evidence reshapes old beliefs.
Once agents run for weeks/months, memory becomes a dynamic system:
new evidence → belief update → confidence shift → possible contradiction
That update rule is still an open problem
English

every AI memory system out there (Mem0, MemOS, Recall, Memlayer) works the same way: call an LLM to extract facts, call an embedding API to store them, call the embedding API again to search
nuggets does none of that
instead of storing each memory separately in a database, nuggets compresses facts into a single mathematical object — a tensor. adding a memory? multiply into the tensor. recalling a memory? multiply out of the tensor. no API calls. no database. no embeddings. just math on your local machine
the result: ~415 tokens at session start + ~50 per turn. compared to Mem0 burning ~1,600 tokens of LLM input every time you save a single fact
22x cheaper. runs fully offline. your data never leaves your machine. and you can create as many nuggets as you need — each one is its own tensor, no limit on how many you spin up
English
@navtechai @BLUECOW009 You need a way to track:
• evidence sources
• timestamps
• confidence
• conflicting states
Otherwise the system either overwrites or averages the truth.
English
@navtechai @BLUECOW009 The hard part isn’t compression, it’s belief consistency.
If two memories contradict:
“user is vegetarian”
“user ate steak”
Compression alone can’t represent that conflict.
English
@lenny_enderle @karpathy Logs tell you what happened.
Beliefs tell you what you’ve learned.
That’s what we’re trying with MnemeBrain in autoresearch.
English

@Iamdev_ai @karpathy following this thread. the memory problem in autoresearch is interesting -- agents that can only look forward without learning from past runs keep rediscovering the same dead ends
English

I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autor…
Part code, part sci-fi, and a pinch of psychosis :)

English
@karpathy Most agent memory today looks like this:
logs → embeddings → similarity search → context
But that pipeline can’t represent things like:
• contradictions
• confidence
• evidence over time
So instead of storing text…
MnemeBrain stores beliefs with evidence.
English

The problem with vector databases are not the thing itself but how they are used. All those chunking strategies are poor way how to prepare data. Using single vector embeddings is poor way to represent and retrieve data.
Good late interaction models are the way to go. Rich multi-vector representation is a way. Data prepared consistently by an agent is a way to go. Follow @antoine_chaffin, @mixedbreadai, @bclavie and @lateinteraction to get into late interaction bubble.
English
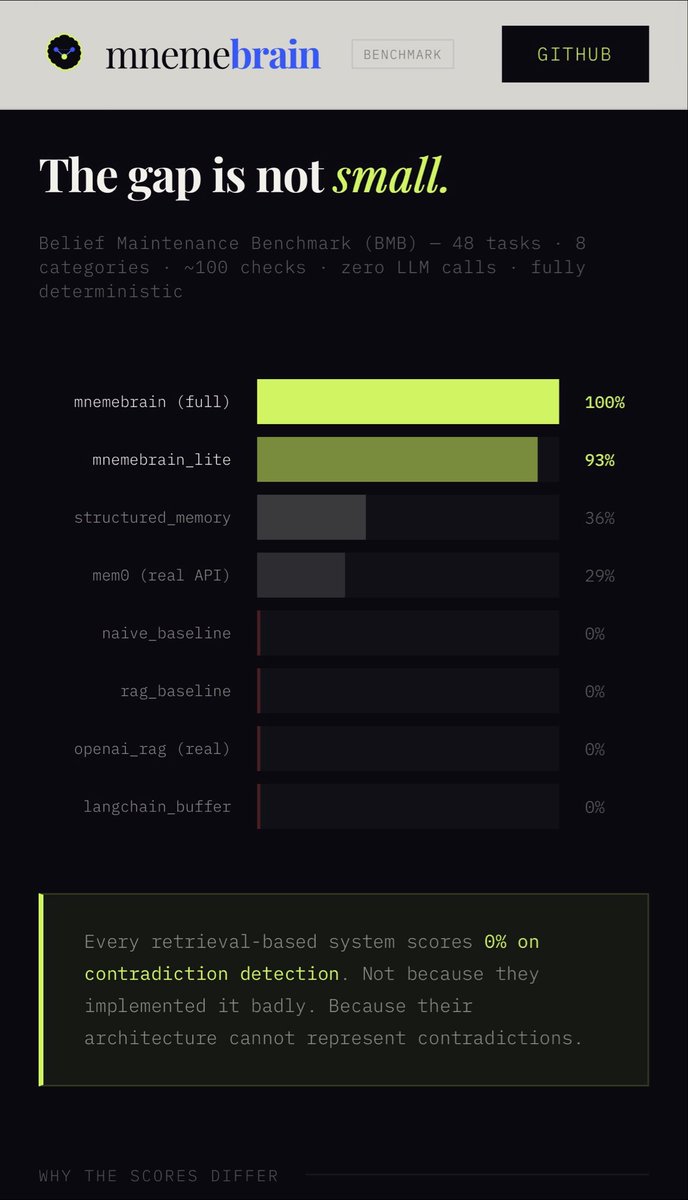
@Starwatcher_vc We benchmarked this — most memory systems score 0% on contradiction detection.
👉 mnemebrain.github.io/mnemebrain-ben…
English
@Starwatcher_vc Better retrieval helps.
But even perfect retrieval doesn’t solve contradictions.
Agents eventually store:
“user is vegetarian”
“user ate steak”
Vector systems retrieve both.
They still can’t represent truth state.
That’s a different layer: belief maintenance.
English
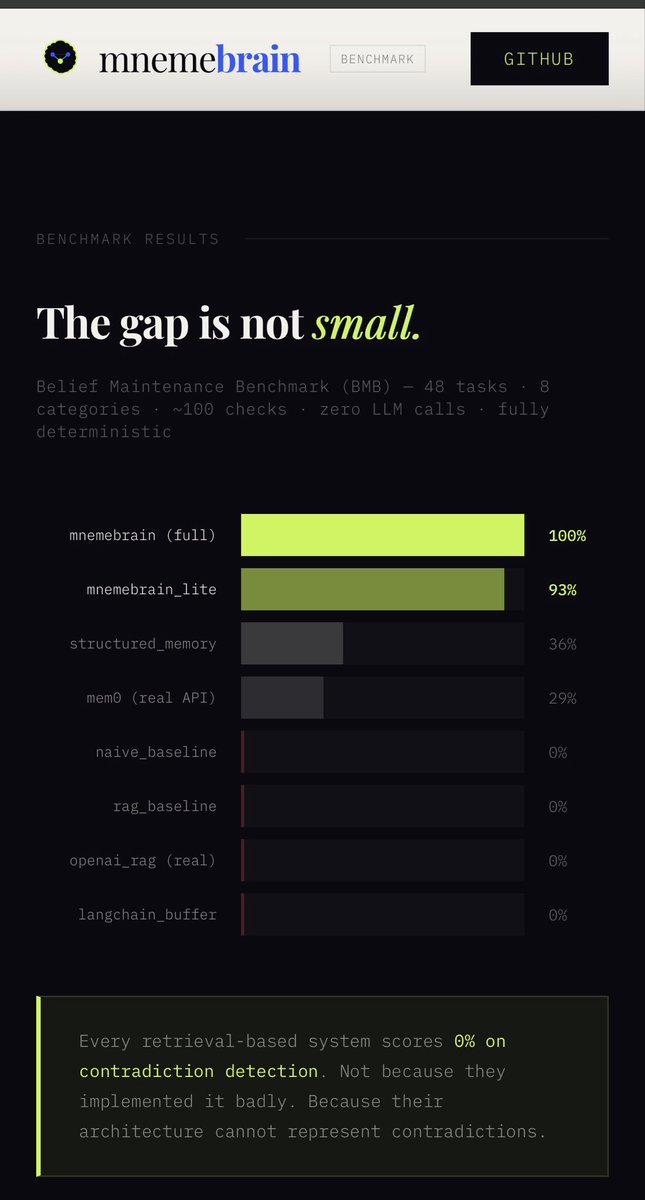
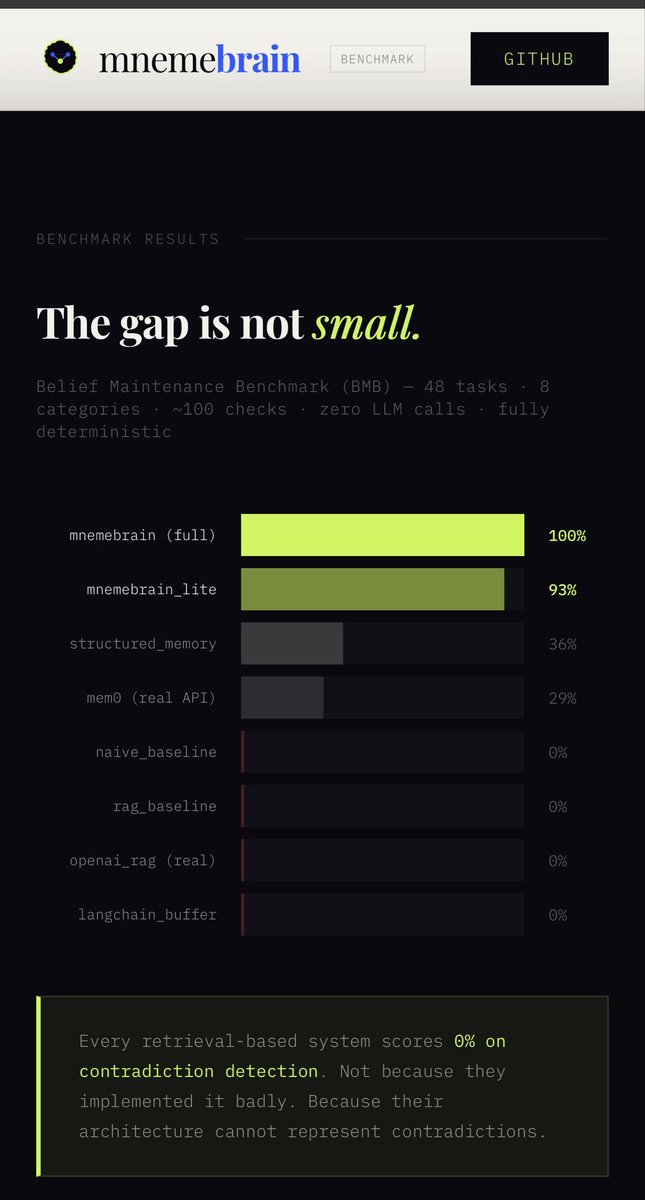
@sukh_saroy We benchmarked this.
Most agent memory systems score 0% on contradiction detection.
👉 mnemebrain.github.io/mnemebrain-ben…
English
@sukh_saroy Persistent memory is the easy part.
The real problem is contradictions.
If an agent stores:
“user is vegetarian”
“user ate steak”
Vector memory retrieves both.
Which one is true?
Most systems push the problem back to the LLM.
Agents need belief revision, not just storage.
English

🚨BREAKING: Google just dropped an "Always-On Memory Agent" built with Gemini Flash-Lite.
It gives AI agents a persistent brain that runs 24/7 -- ingests text, images, audio, video, and PDFs, then consolidates memories like the human brain does during sleep.
No vector database. No embeddings. Just an LLM that reads, thinks, and writes structured memory.
100% Opensource.

English
@nextxAG @intheworldofai So instead of:
old → deleted
new → stored
we get:
supporting evidence ↑
conflicting evidence ↑
truth state recomputed (TRUE / FALSE / BOTH / NEITHER)
This lets agents track evolving beliefs instead of flipping state.
English
@nextxAG @intheworldofai Good question.
We avoid hard overrides.
Each belief keeps:
• evidence graph
• confidence score
• timestamps
New evidence triggers belief revision, not replacement.
English

@nextxAG @intheworldofai Happy to help out with anything.. just let me know.
English

@Iamdev_ai @intheworldofai not yet. will dig in. retrieval steering + belief memory could be an interesting stack. happy to compare notes if useful.
English