Laura Wang me-retweet

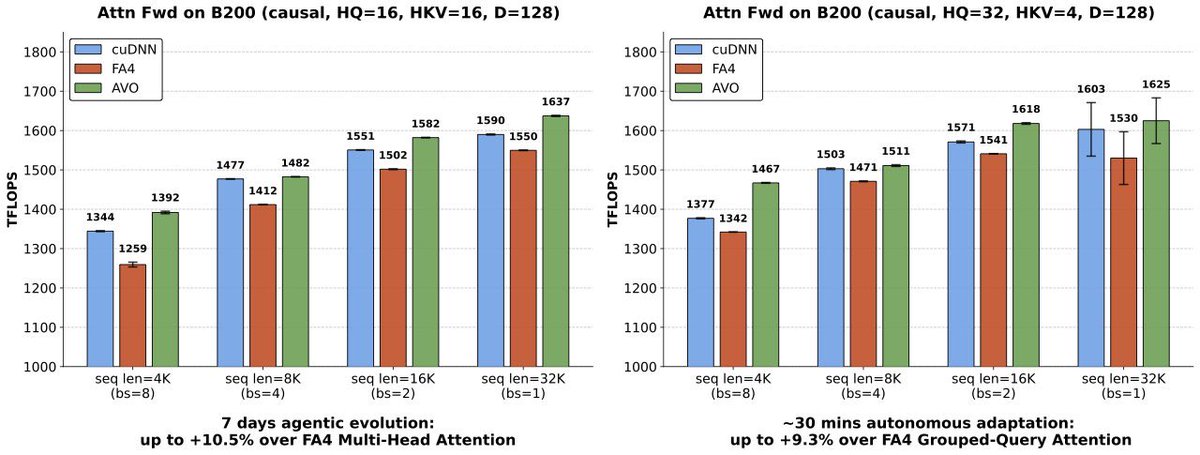
This may be one of the first real signs of superhuman intelligence in software. On some of the most optimized attention workloads, agents can now outperform almost all human GPU experts by searching continuously for 7 days with no human intervention inside the optimization loop.
Terry and I started agentic coding efforts at NVIDIA 1.5 years ago. Neither of us knew GPU programming, so from day one we pushed toward fully automated, human-out-of-the-loop systems. We call it blind coding.
Over those 1.5 years, the two of us generated 4 generations across 2 agent systems. Since the 2nd generation, the stacks have been self-evolving. Each agent is now around 100k non-empty LOC.
When we released the blind-coding framework VibeTensor in January, the implication was easy to miss. AVO makes the signal clearer.
My bet is: blind coding is the future of software engineering. Human cognition is the bottleneck.

English