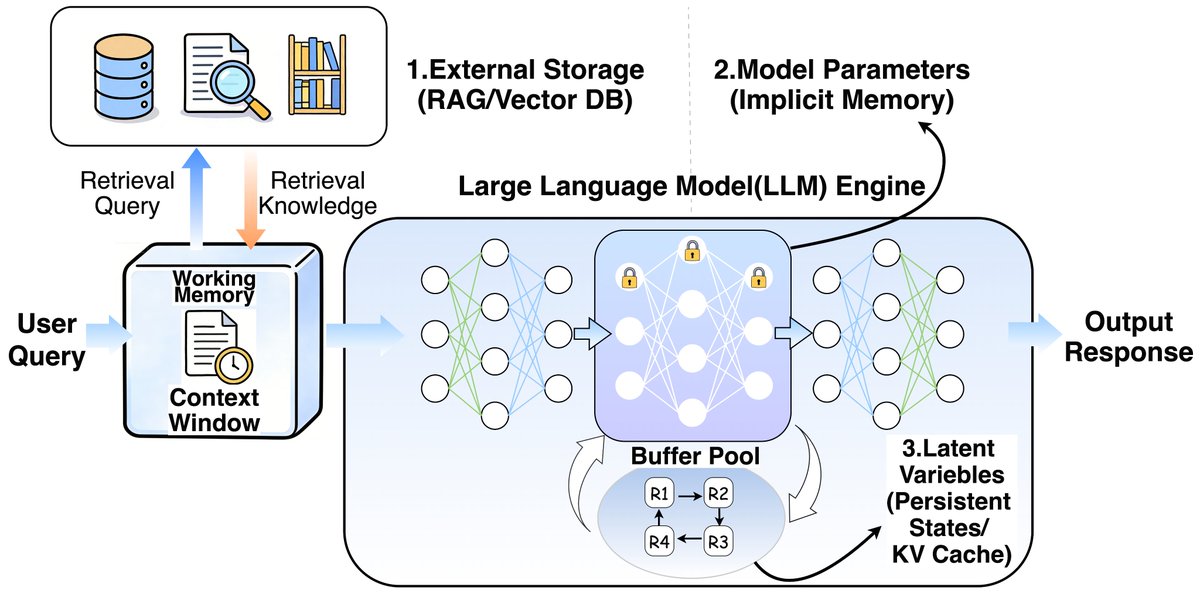
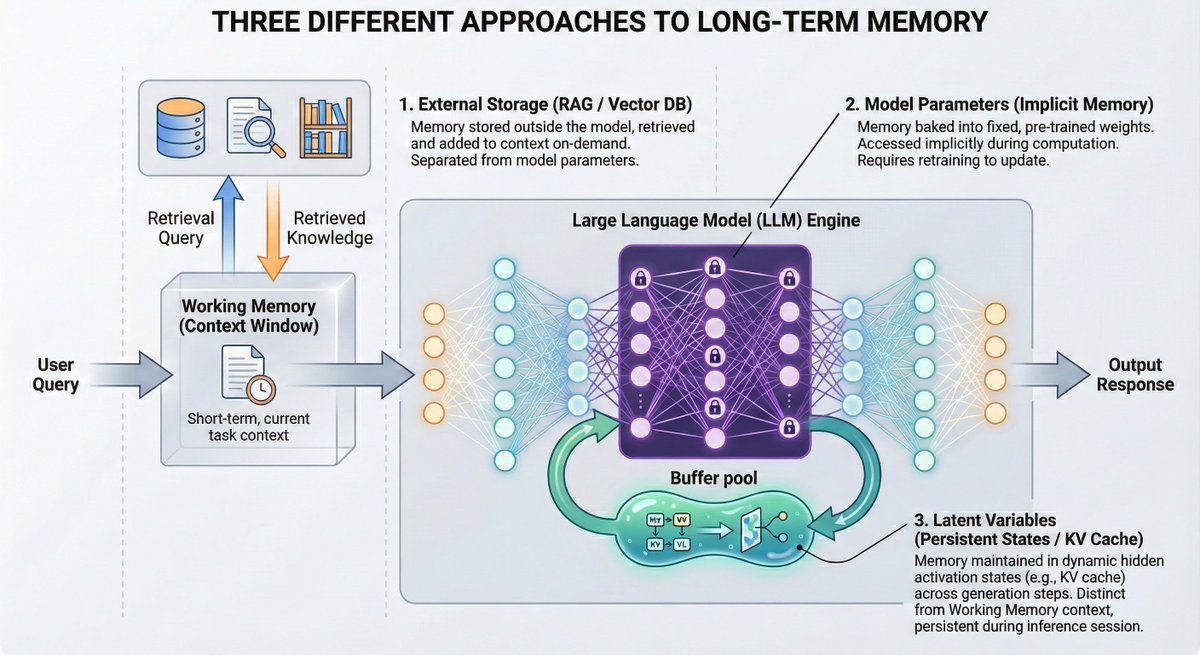
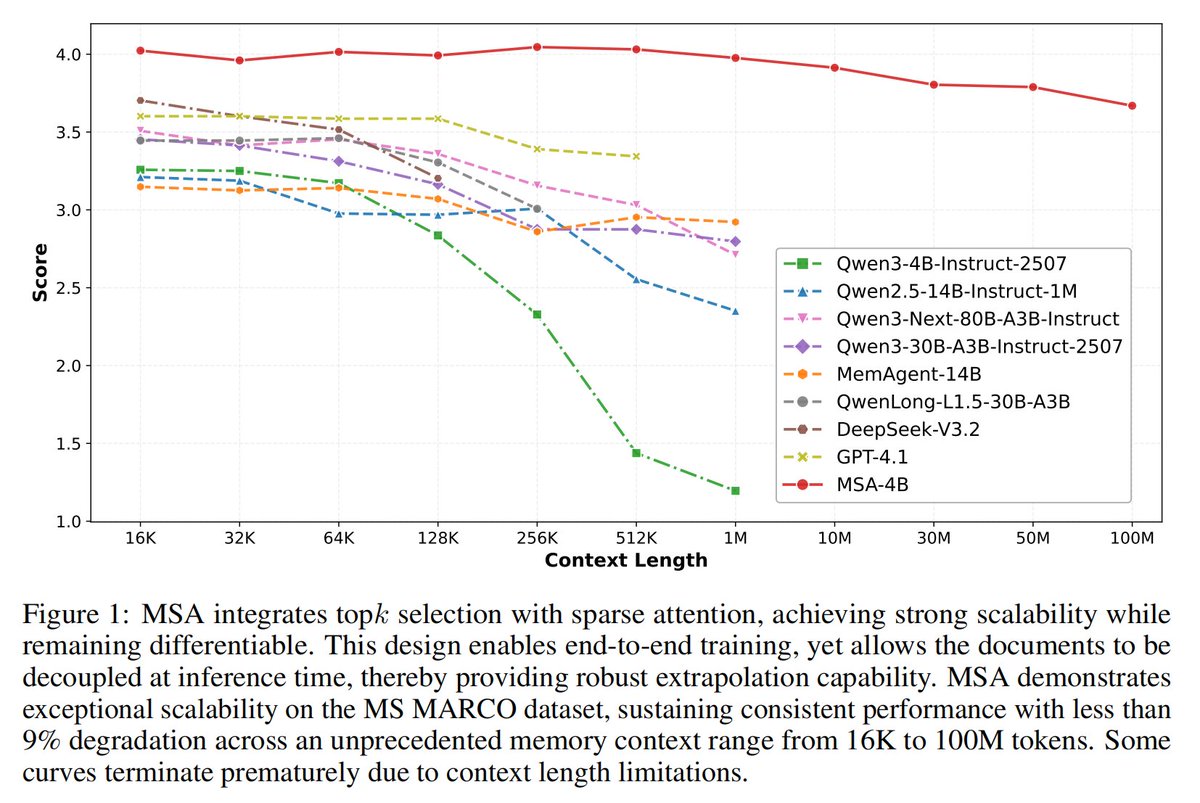
MSA (Memory Sparse Attention) represents our significant exploration in the field of long-term memory. It stands as the first end-to-end long-term memory framework for large models to genuinely achieve a 100M context length. Interestingly, as the memory length scales from 16K to 100M, the model's performance score decreases by a mere 9%, demonstrating highly robust scalability.
Main contribution:
1,We propose MSA, an end-to-end trainable, scalable sparse attention architecture with a
document-wise RoPE that extends intrinsic LLM memory while preserving representational
alignment. It achieves near-linear inference cost and exhibits < 9% degradation even when
scaling from 16K to 100M tokens.
2,We introduce KV cache compression to reduce memory footprint and latency while maintaining retrieval fidelity at scale. Paired with Memory Parallel, it enables high-throughput
processing for 100M tokens under practical deployment constraints, such as a single 2×A800
GPU node.
3,We present Memory Interleave, an adaptive mechanism that facilitates complex multi-hop
reasoning. By iteratively synchronizing and integrating KV cache across scattered context
segments, MSA preserves cross-document dependencies and enables robust long-range
evidence integration.
4,Comprehensive evaluations on long-context QA and Needle-In-A-Haystack benchmarks
demonstrate that MSA significantly outperforms frontier LLMs, state-of-the-art RAG systems and leading memory agents.
Welcome to feedback:
github.com/EverMind-AI/MSA
zenodo.org/records/191036…
We are looking for passionate talents to join our team! If you are interested in our work and vision, please don't hesitate to send us an email at evermind@shanda.com.
English