To evaluate your Claw agent's evolutionary capabilities, you can utilize EvoAgentBench, the second benchmark dedicated to agent evaluation on Hugging Face.
EverMind@evermind
~200 downloads in under a week. Blown away. Thank you.
English
邓亚峰
32 posts
@LongTermMemoryE
CEO @EverMind https://t.co/02ngJwJLve
~200 downloads in under a week. Blown away. Thank you.




The Memory Genesis Competition 2026 Final Event kicked off today in Mountain View, CA. Hosted by @shanda_group and @evermind, and supported by OpenAI and AWS, the Memory Genesis Competition 2026 brought together innovators, researchers, investors, and builders to explore how next-generation memory technologies will define the future of AI. A landmark day for the memory industry. Here is what went down. (Stay until the end. You will want to see how this room looked.) 🧵


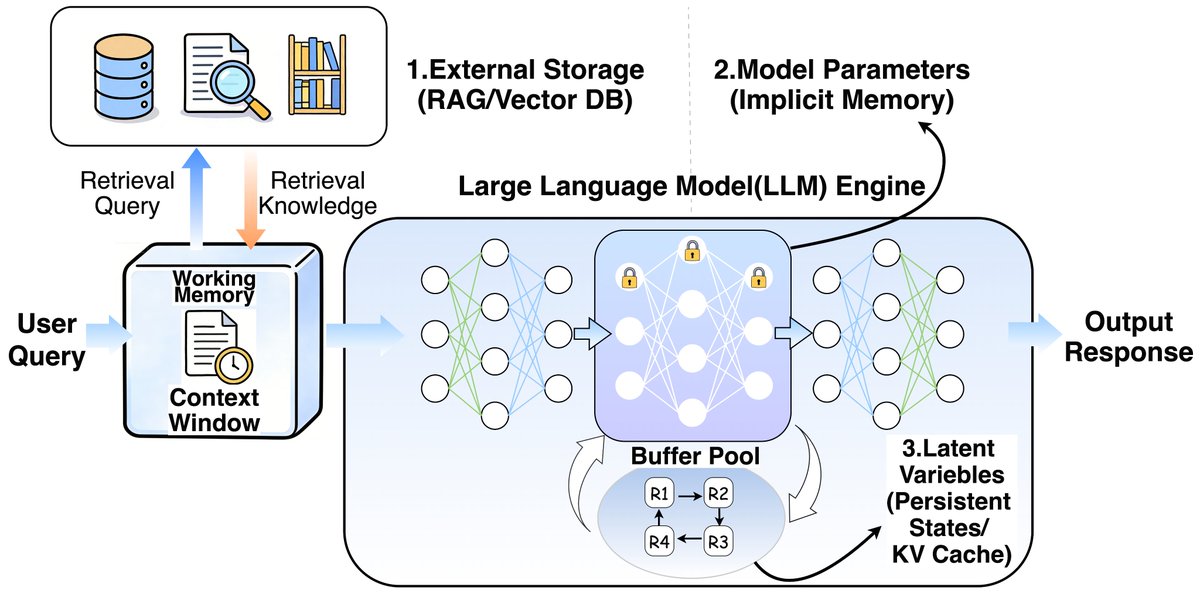
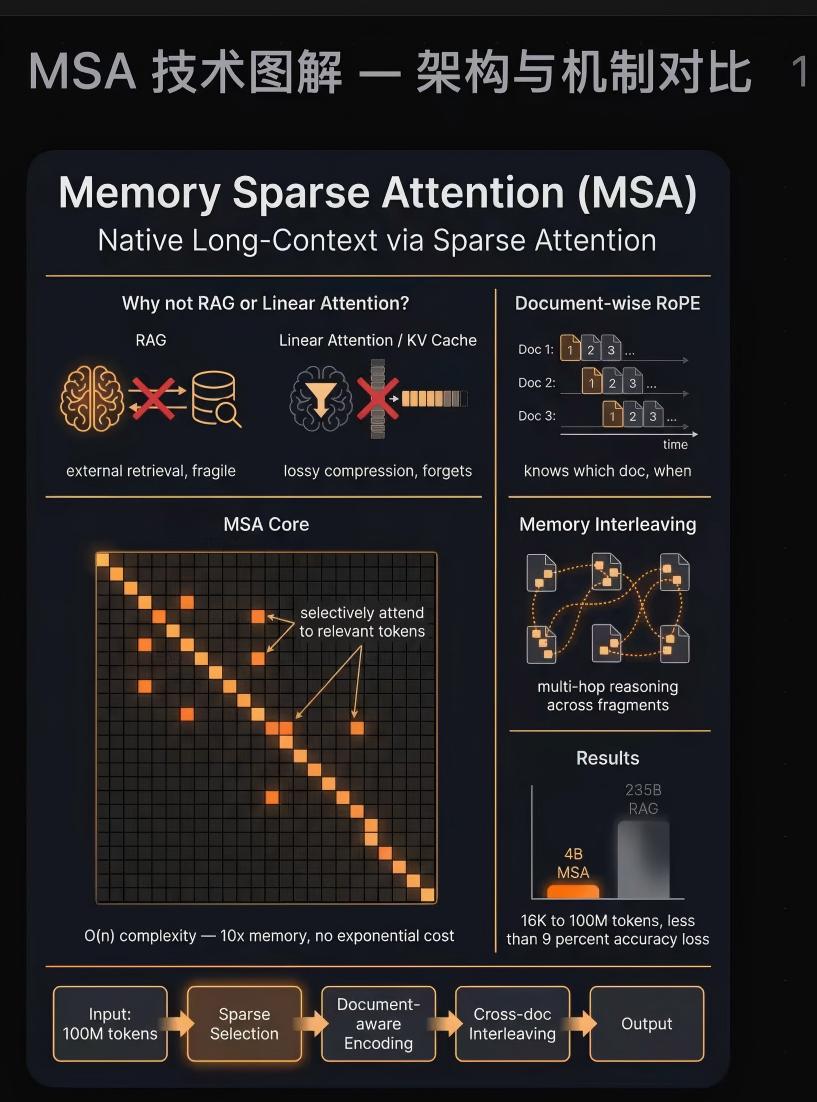
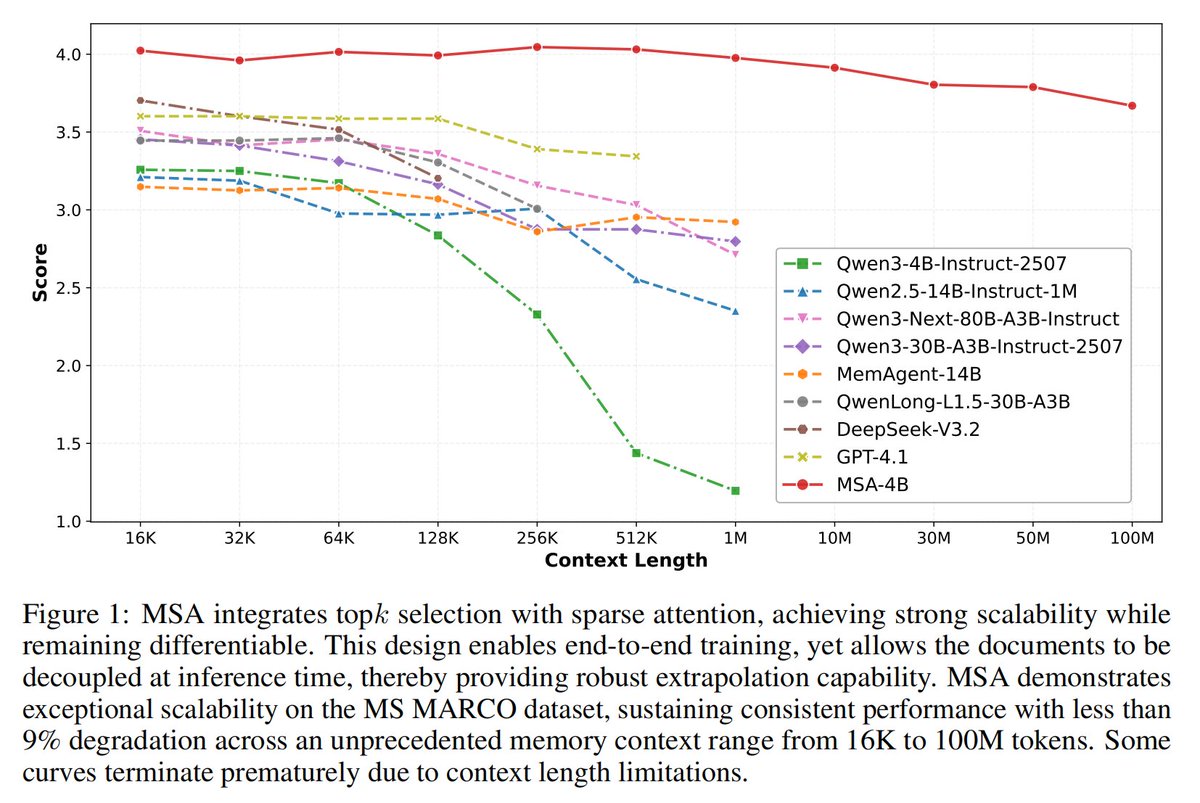
Scaling Attention to 100M context!? Memory Sparse Attention introduces an idea where instead of rereading an entire 100M-token entry, it learns to jump straight into the relevant memories and reason from them end-to-end. More specifically, it first encodes documents into compressed memory slots, then for each question it uses a learned router to score which chunks are actually relevant, pulls only the top few, and runs normal attention over that tiny assembled context. So the model’s compute grows with “how much it needs to look at” not “how much memory exists”. This retrieval step is trained jointly with answer generation, so memory lookup is part of the model itself, and can decouple memory capacity from reasoning cost.
我们昨天在 arXiv 上发了一篇新论文,填补了一个一直没人做的空白:多人、多群组场景下的记忆测试。 简单科普一下为什么这件事重要 之前测 AI 记忆能力的 benchmark,基本都是"两个人聊天"的场景: LoCoMo(2024):最早系统测试多轮对话记忆,但本质上就是两个人对话,上下文约 16K tokens,规模偏小 LongMemEval(2024,ICLR 2025):把规模推到了 115K–1.5M tokens,定义了五个核心记忆能力,但仍然是一对一对话 问题是,现实世界不是这样的。你同时在多个群聊里,跟不同的人聊不同的事,AI 能记住谁在哪个群说了什么吗? 这就是 EverMemBench 要回答的问题。 下图是我用 @claudeai 最新功能生成的,你还别说,挺好看。
In 2024 the question was: which LLM do we use? In 2025 the question is: how do we make agents actually work in production? In 2026 the question will be: which context layer are we building on? Here is why that shift is already underway: