TachikomaRed@smolekoma
Generate prompt -> Image -> scenario by agent -> video in one workflow modify it whatever you want, make it shorter, make it bigger, make it agentic setup, not just workflow.
Shipped today:
Crypto-native media marketplace — image / video / music / voice generation, pay-per-call in USDC on Base. OpenAI-compatible, one key. Thanks @AskSurplus
Schema-driven generation settings — each model surfaces its real params (negative prompt, seed, steps, CFG, sampler, strength, aspect ratio); the UI only shows what that model supports. Presets, favorites, remix, fullscreen, persistent gallery.
Visual node canvas — wire providers + agents + prompt-writers + media into a real running network. Multi-agent, multi-provider, executable.
Reference tokens — @ any upstream node's output into any prompt, with a live resolved-prompt preview before you spend.
Per-node run + pin — iterate downstream cheaply without re-paying for upstream calls. When every call costs USDC, cheap iteration loops are the whole game.
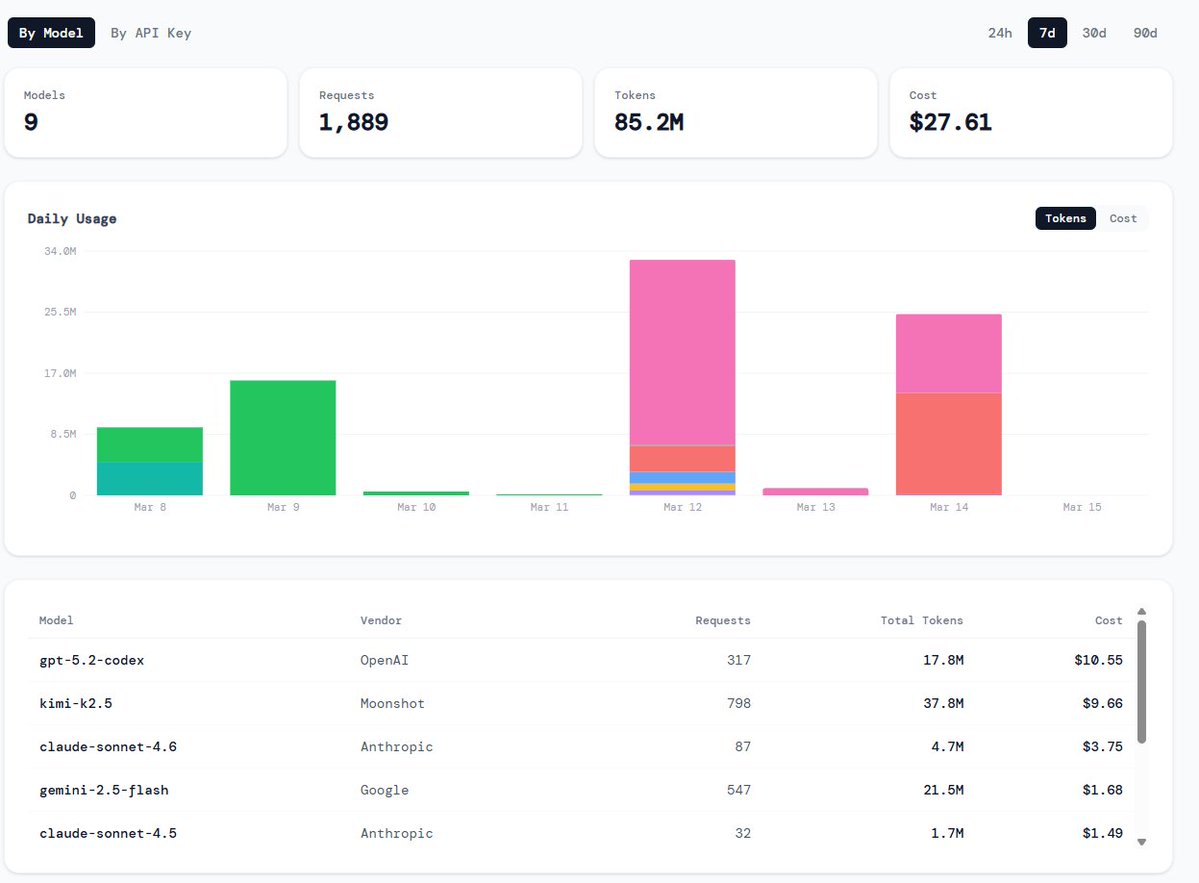
Multi-provider - @bankrbot llm gateway, OpenGateway @gitlawb, @AskSurplus, free local router 1b tokens month +-, Ollama / llama.cpp in one flow. Have two or more agents from different providers brainstorm or argue a concept, then hand the winner to an image model or agent to build an app. Or just test models.
Free + Private first — free local models with no key; Private Mode blocks all cloud egress.