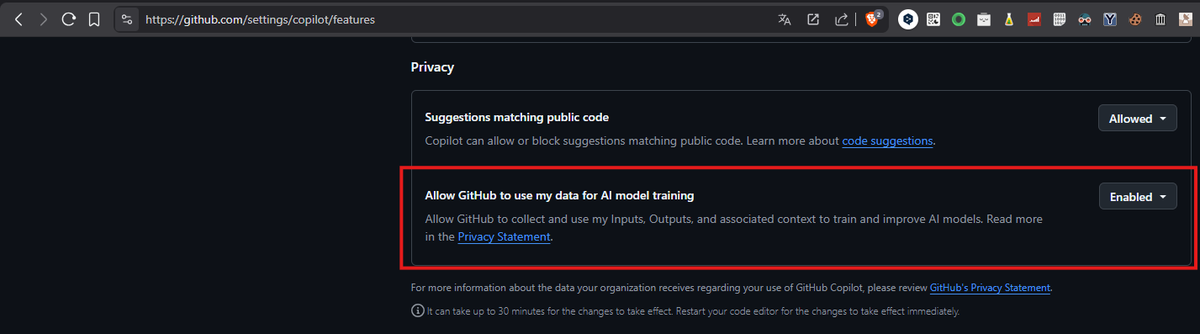
@VincentVentalon Je lui ai quand même posé la question dans le doute 😅
question: Non, Claude Code n'utilise pas axios. C'est un outil CLI qui tourne en Node.js et communique avec l'API Anthropic via son propre SDK (@anthropic-ai/sdk), pas via axios.
Français