Tweet Disematkan

Generate PROMPTS like a PRO 😹 👇
#stablediffusion #aipromptgenerator
🔖Bookmark (save) for future reference....
🩷 Like if you loved it....
🖊️Comment/Suggestions if you are getting any error....
English
Stable Diffusion Tutorials
2.1K posts

@SD_Tutorial
👉 Ai models local installation 👉 Comfy Workflows 👉 Tutorials (Image Gen, Video gen) FOLLOW WEBSITE 👇👇

daVinci-MagiHuman 🎬 Human Centric Audio-Video Generative Model by GAIR Model: huggingface.co/GAIR/daVinci-M… Paper: huggingface.co/GAIR/daVinci-M… ✨ 15B – Fully open source! ✨ 5-sec 1080p video in 38s on one H100 ✨ Supports 6 languages ✨ Unified model with text + video + audio








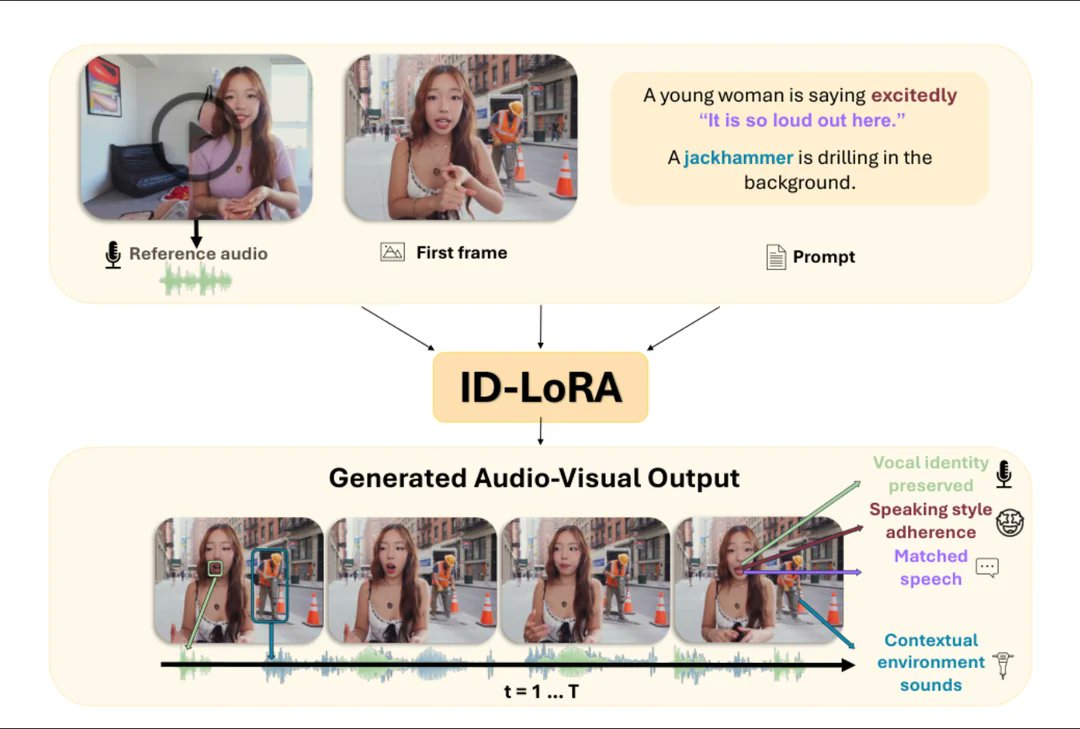
ID-Lora: Identity-Driven Audio-Video Personalization with In-Context LoRA 😃😄 Generate video and audio of a specific person from a single text prompt, a reference image, and a short audio clip — all in one model. Now supporting LTX 2.3. Paper:👇 id-lora.github.io