@E_FutureFan The new dots.ocr just dropped: x.com/ModelScope2022…
ModelScope@ModelScope2022
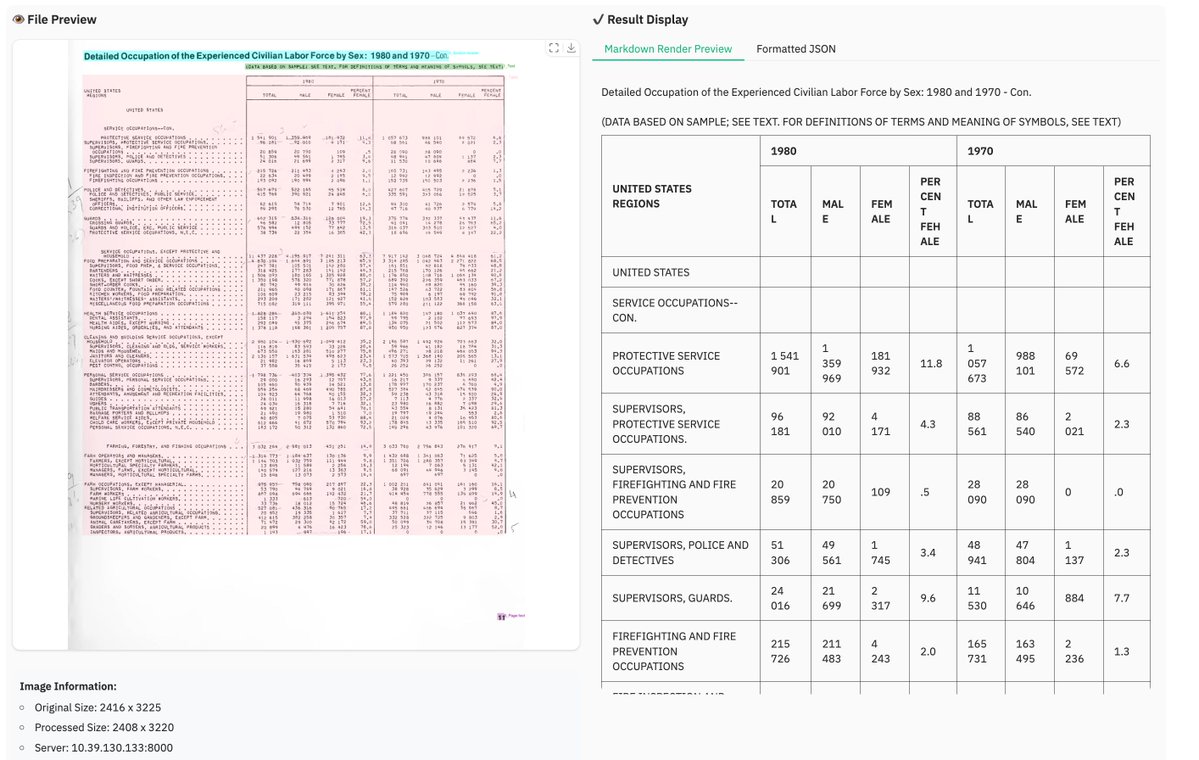
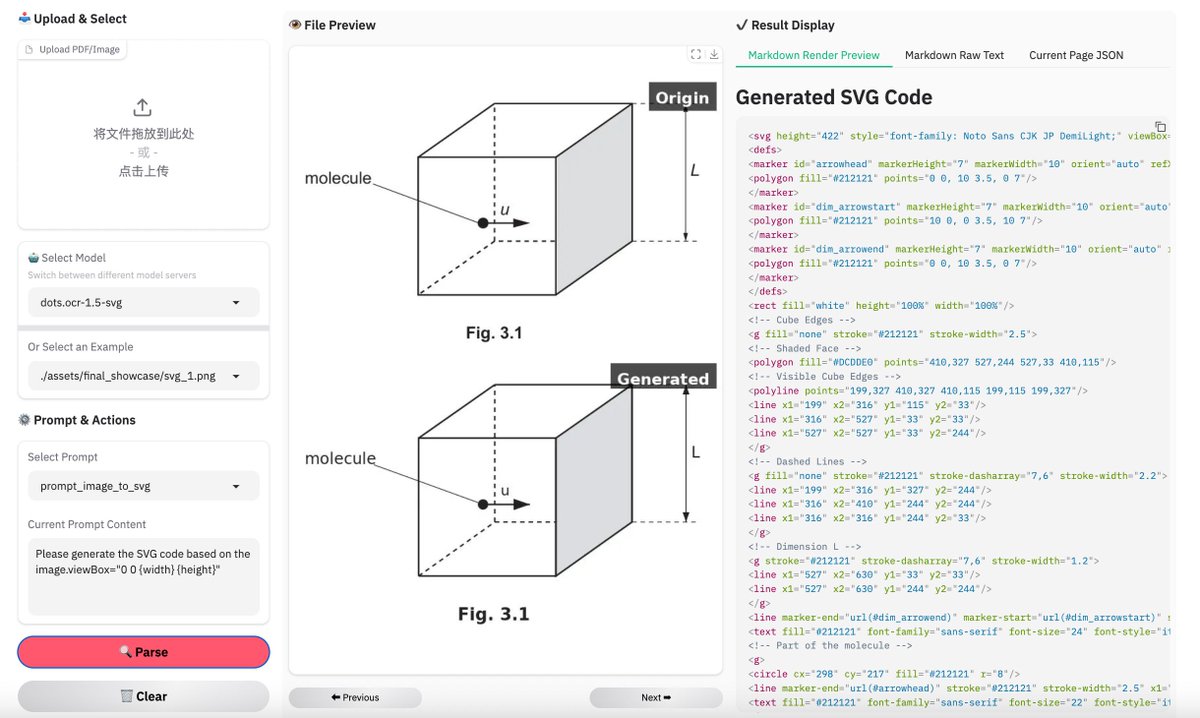
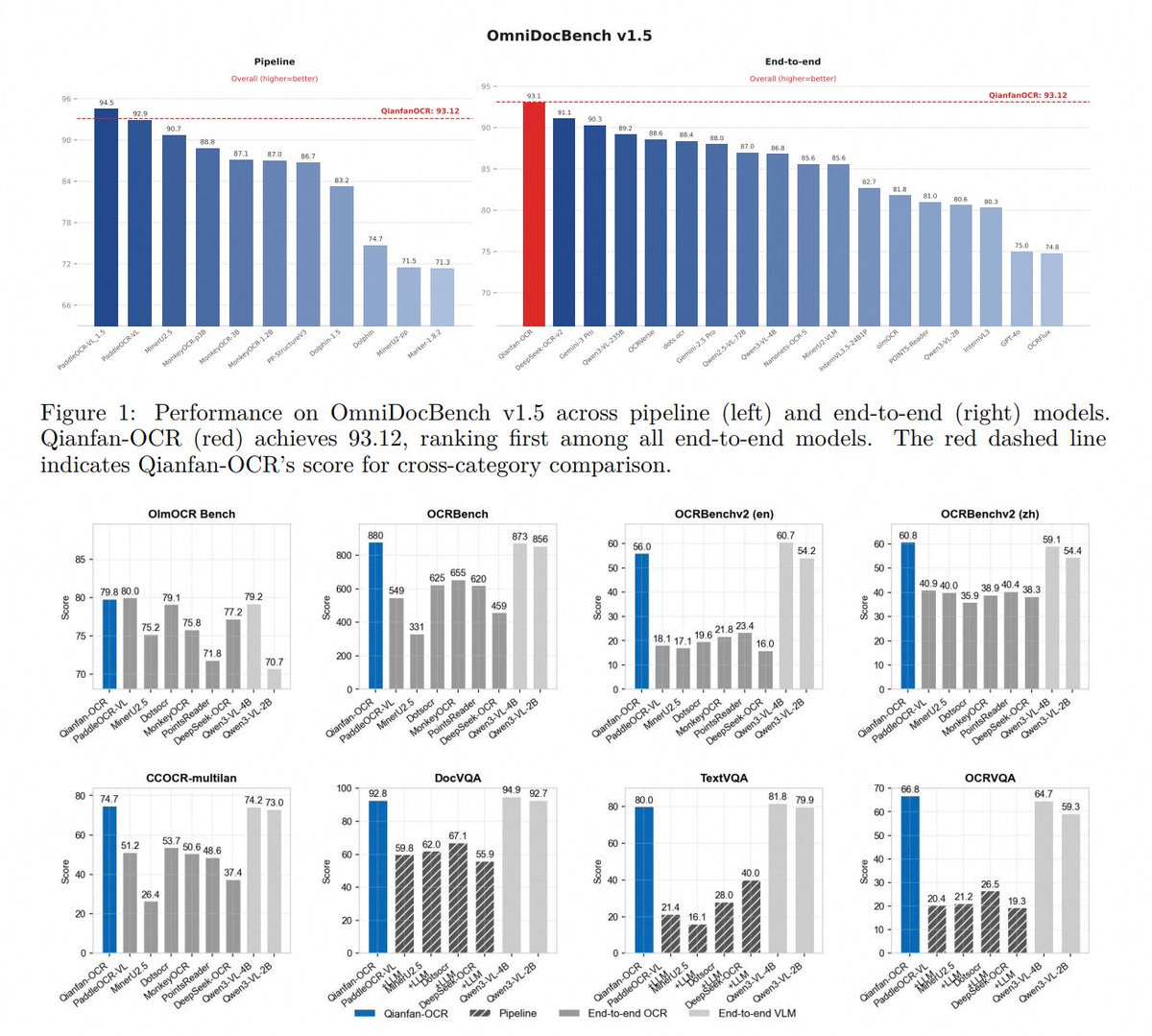
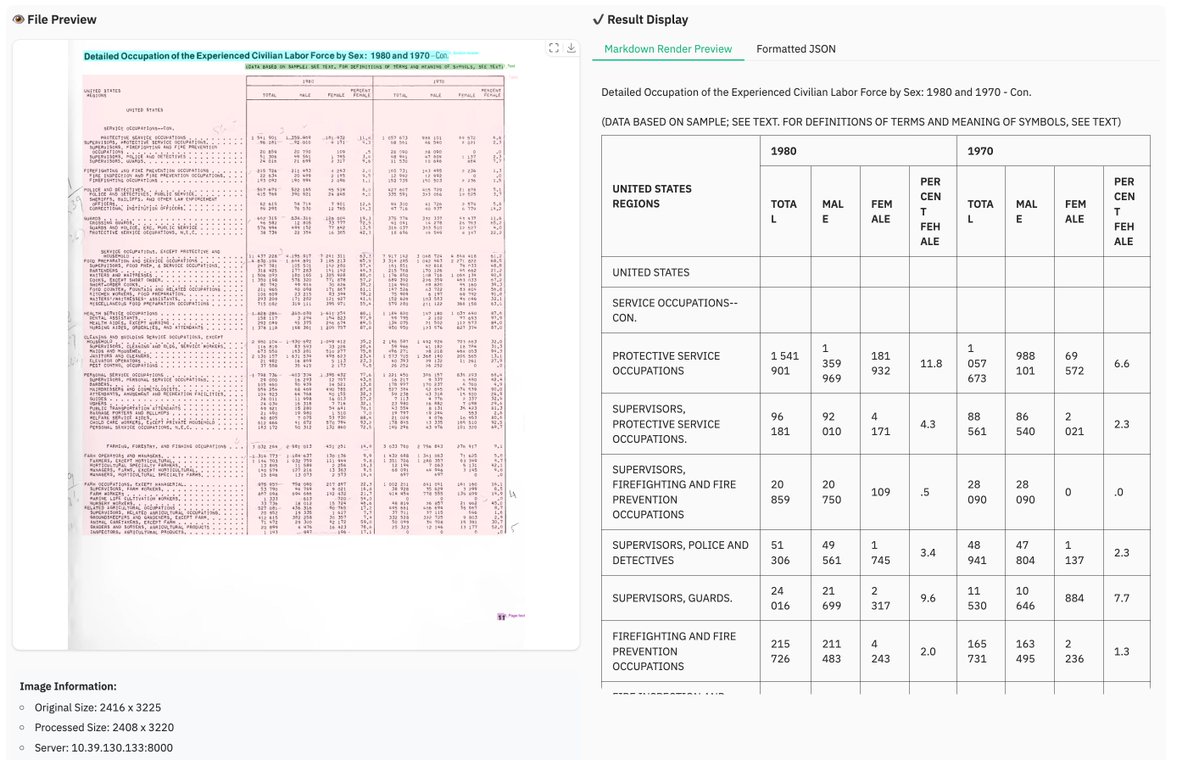
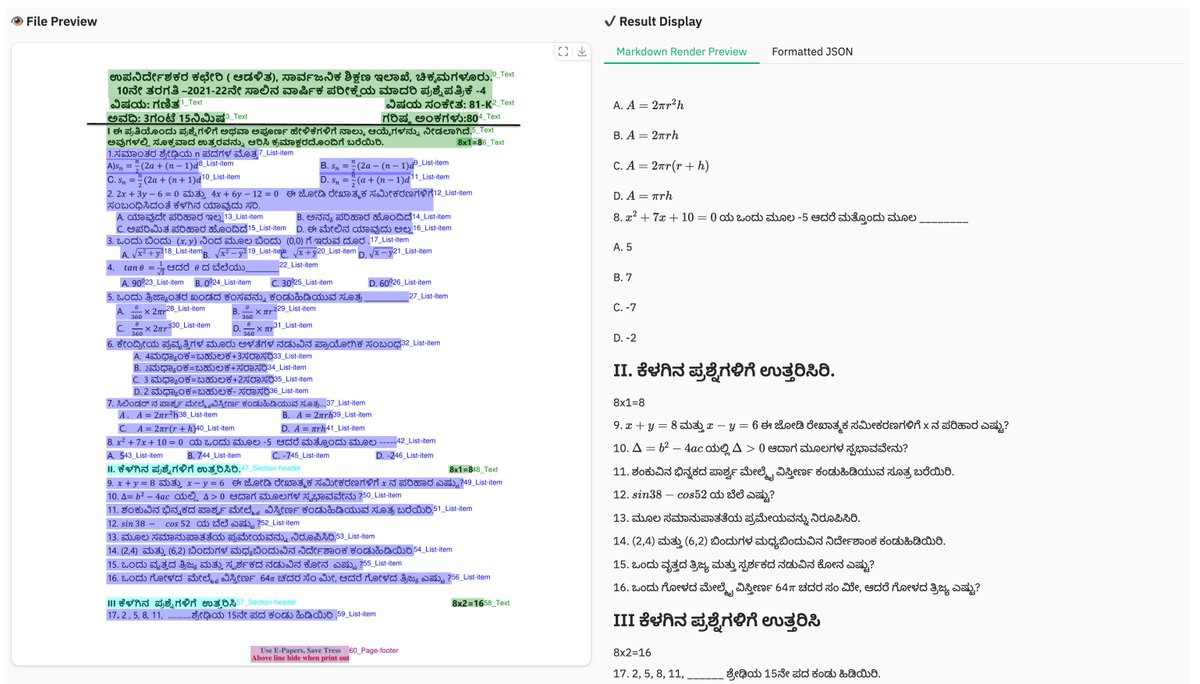
dots.mocr from Rednote, a 3B multimodal OCR building on dots.ocr with stronger benchmarks and broader task coverage. 🚀 📊 Tops HuanyuanOCR, GLM-OCR, and PaddleOCR-VL-1.5 across olmOCR-Bench, OmniDocBench v1.5, and XDocParse with Elo average 1124.7 🎨 Charts, UI layouts, scientific figures parsed directly to SVG — dots.mocr-svg variant for dedicated image-to-SVG tasks 🌐 Web parsing, scene text spotting, document QA all included ⚡ Integrated into vLLM from v0.11.0 📄 Apache 2.0. Model: modelscope.cn/models/rednote… Model 🌍: modelscope.ai/organization/r… Paper: modelscope.ai/papers/2603.13… GitHub: github.com/rednote-hilab/…
English