
Wingachad
43 posts



@Sheldonbishop01 @venturetwins Nah, this game is epic honestly.
Just wish to have a company operation emulate part🤓 , but it's whole another story
English
@Wingachad @venturetwins appreciate it man! Any other feedback?
English
@Sheldonbishop01 @venturetwins I mean I've palyed multiple times before the patch (maybe 10 to 20? I don't remembered), and the highest score is about 200B.🙃
So yes, maybe you should bring back the reduction, and just fix those 8B corner cases that I had.
English
@Wingachad @venturetwins It’s only a 7-8% chance. You just goated bro. But would you say I should make it harder?
English
@Sheldonbishop01 @venturetwins Bro IDK,I've only played once since that patch. and I got my 1st 1trillino company LOL. Maybe it's too easy now IDK

English
@Wingachad @venturetwins I fixed the algorithm and removed that reduction. Let me know if it feels better now - your team was killer!
English
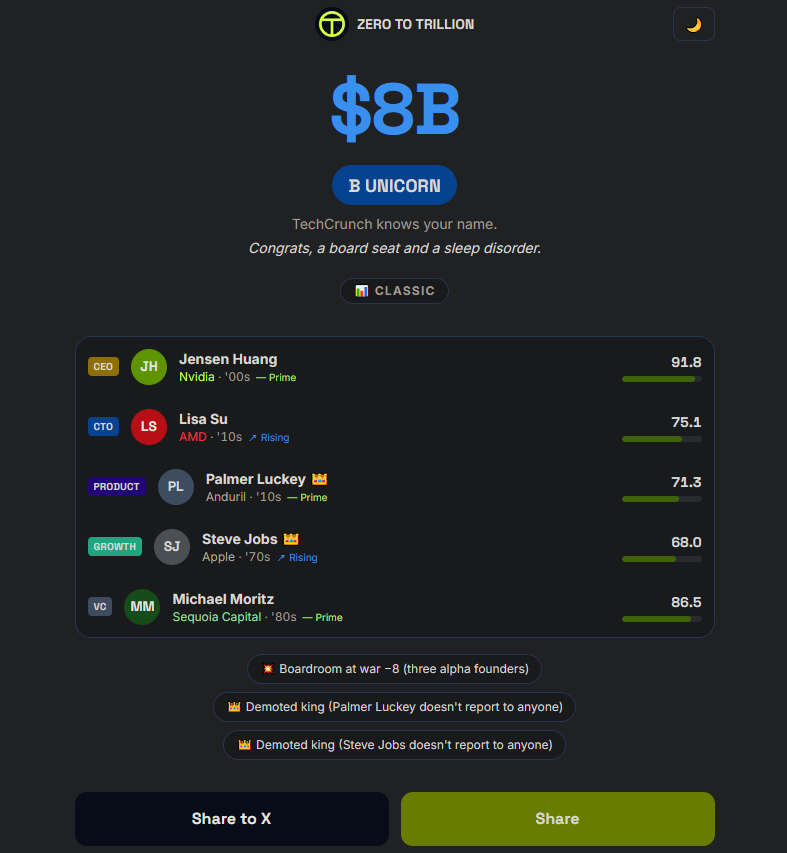
@Wingachad @venturetwins Bro the problem is that Steve Jobs and Palmer Lucky lose points when they’re not the CEO. Have to be the big bosses 🫡
English
@Sheldonbishop01 @venturetwins CAN NOBODY BUILT A BETTER ROSTER I PROMISE
English
@Sheldonbishop01 @venturetwins DUDE THIS GAME IS SOOOOOOO BROKE!!!!!!!!!!!!!!!!!!!!!
02t.app/r/v1AB0AAAIOAQ…
English

刚刚 Doubao-Seed-2.1-pro 发布啦!
给大家分享一个自我迭代 Agent 的构建技巧啊, 也是我在今天字节 seed-2.1 模型发布 demo 中用到的技巧.
这个技巧的核心就是, 干一件复杂的事情, 用两个Agent比用一个Agent要好. 简单来讲打工Agent干完活之后, 还要增加一个评审Agent, 这个Agent要给打工Agent的产出评分, 然后说明评分理由, 哪里做得好, 哪里做的不好.
然后, 一定要输出结构化的评分结果(JSON就行), 这样, 打工Agent接到评分后, 进行修改, 修改完毕再次交给评审Agent, 评审Agent再次打分, 这时候就可以跟上次的打分进行对比. 只有得分大于上次的得分, 你的框架才合并这次的修改. 这就是 Agentic 自我迭代了.
基于 AI 反馈的强化学习的雏形基本就是这样的了, 以及吴恩达提出的 Agentic Workflow 核心原则之一就是 Reflection(反思),框架让模型像人类程序员提交 PR一样:打工 Agent 提交 PR,裁判 Agent 跑测试、打分。只有 Review 通过才能 Merge 到主分支。这就是真正的“工程化迭代”了. 甚至我框架内其实就是采用的Git模式, 多个Agent进行并行评估模拟多个分支, 只有打分高的才会合并到主分支.
最终得益于 Seed-2.1 本身的自我迭代和多模态能力也很强, 在它的驱动下, 成功实现了这个【只需要上传一个城市的相册, 就能建模一整个城市】的demo. 相信在现场的同学已经看到这个 demo 了哈哈.
下一期告诉你当这个办法也失效了, 该怎么办☆.
#AIAgent #seed21 #AI自我迭代
中文




Anthropic@AnthropicAI
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees. The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance. Access to all other Claude models is not affected. We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible. Read our full statement: anthropic.com/news/fable-myt…
ZXX

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Mini…
MiniMax Sparse Attention:
huggingface.co/papers/2606.13…
MiniMax (official)@MiniMax_AI
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities - Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas - MiniMax Sparse Attention scales context to 1M - Natively Multimodal from Step Zero API: platform.minimax.io Token Plan: platform.minimax.io/subscribe/toke… 🚀New! MiniMax Code: code.minimax.io Weights & Tech Report in ~10 Days
English

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: +21.8% on Kimi Code Bench v2, +11.0% on Program Bench, and +31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


English
@akshen121 Dude what??????????????
I really wanna play this indeed!!!
English

Claude Fable 5 just crushed my amusement park benchmark!
This is awesome, The details, The aesthetics. Crazy!
Akshen@akshen121
Claude Opus 4.8🫡
English

M3 也绝对是underrated,骂得有点太猛了,其实挺好用的(日常我也在用
flyingpetals@flyingpetal472
@MikaStars39 K2.6的审美创意设计确实不错(不过工程交付稳定性还差点)。基模scaling确实最重要,minimax m2.x 太憋屈了。
中文
@StepFun_ai @ArtificialAnlys Even though not best result, at least u guys are honest😄
English

Thanks @ArtificialAnlys for the detailed independent evaluation.
Step 3.7 Flash is built with a clear focus on the intelligence-speed frontier: MTP-assisted decoding, 400+ output tokens/s, stronger agentic performance, native multimodal capabilities, and Apache 2.0 open weights.
This is the direction we believe matters for production agent workloads: capable, efficient, and deployable at scale.
Artificial Analysis@ArtificialAnlys
StepFun's Step 3.7 Flash sits on the Intelligence vs Output Speed Pareto frontier, scoring 43 on the Artificial Analysis Intelligence Index and is served at over 400 output tokens/s Step 3.7 Flash (open weights, Apache 2.0) is a significant upgrade on Step 3.5 Flash and stands out for its speed and gains in agentic performance (particularly GDPval-AA). 400 output tokens/s is more than double other models of a similar size class. Contributing to this speed is that the model has only 11B active parameters and the model ships with trained Multi-Token Prediction heads (3) that predict several tokens in a single forward pass, letting it decode multiple tokens at once using speculative decoding. Key results for Step 3.7 Flash with the high reasoning level: ➤ 4 point Intelligence Index improvement: Step 3.7 Flash scores 42.6 on the Artificial Analysis Intelligence Index, up 4 points from Step 3.5 Flash 2603 (38.5). It is equivalent to Qwen3.5 122B A10B (41.6) and trails MiniMax-M2.7 (49.6) and DeepSeek V4 Flash (Max Effort, 46.5) ➤ Speed-intelligence frontier: Step 3.7 Flash achieves ~400 output tokens/s on StepFun's first-party API, placing the model on the Intelligence vs Output Speed Pareto frontier. StepFun has released the weights for this model and we expect several third-party providers to serve this model ➤ Agentic capability improvements: Step 3.7 Flash improves over Step 3.5 Flash 2603 across our agentic evaluations, in both GDPval-AA (real-world agentic tasks) and TerminalBench Hard (agentic coding and terminal use). It achieves a GDPval-AA Elo of 1298, up from 1070 for Step 3.5 Flash 2603, and it's TerminalBench Hard score increases to 35.6% from 32.6%. AA-LCR (Long Context Reasoning) improves to 63.7% from 54.3%. Scores for other evals remain relatively flat ➤ Weaker on knowledge and hallucination than peers: While Step 3.7 Flash trails competitors overall on AA-Omniscience (-38), it improves from Step 3.5 Flash 2603 (-44). It has an AA-Omniscience accuracy of 25.4% and a hallucination rate of 84.4% ➤ Native multimodal support, new in this generation: Step 3.7 Flash introduces a 1.8B-parameter vision encoder for native image understanding, where Step 3.5 Flash was text-only. On MMMU-Pro (multimodal reasoning) it scores 75.3%, roughly matching Qwen3.5 122B A10B (75.0%). Among its same-size open weights peers, MiniMax-M2.7, DeepSeek V4 Flash, and gpt-oss-120b are text-only Key model details: ➤ Context window: 256K tokens ➤ Parameters: 198B total, 11B active (MoE). At BF16 native precision, Step 3.7 Flash requires ~400GB to store the weights. StepFun has also released FP8 (~200GB) and NVFP4 (~100GB) versions for lower-memory deployment ➤ License: Apache 2.0 ➤ Availability: Currently Step 3.7 Flash is available on @StepFun_ai 's first-party API
English

MiniMax M3 has landed in the Arena and has moved the Pareto frontier!
Their latest model ranks #7 for Code Arena: Frontend, scoring 1531, it is neck and neck with GLM-5.1. It moves the Pareto frontier in its price class at $0.60 input/$2.40 output per Mtoken.
Congrats to the @MiniMax_AI team on this achievement!

MiniMax (official)@MiniMax_AI
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities - Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas - MiniMax Sparse Attention scales context to 1M - Natively Multimodal from Step Zero API: platform.minimax.io Token Plan: platform.minimax.io/subscribe/toke… 🚀New! MiniMax Code: code.minimax.io Weights & Tech Report in ~10 Days
English


Behind the MiMo API Price Reduction:
The deepest price cut, up to 99%, is for Input (Cache Hit). The core reason is our inference framework now supports hierarchical KV cache optimization for SWA. Production inference engine tests show this optimization increases cached token capacity by 5x, equivalent to an 80% reduction in caching costs. Combined with Cache Read Overlap among multiple Full Attention modules in the Hybrid model, actual costs are further reduced.
Prices for Input (Cache Miss) and Output are also reduced by 60%-80%. This mainly benefits from the extreme 1:7 Full:SWA sparsity ratio brought by the model architecture (the prefill compute of the 70-layer MiMo-V2.5-Pro roughly equals a 10-layer GQA model). This kept our original inference costs well below the industry average, naturally leaving a 2x-3x profit margin in pricing. This price adjustment simply reflects our decision to pass these structural cost efficiencies directly to developers.
Operating at these newly reduced API prices, our production inference engine is running at near full capacity, and we can still essentially break even. We previously advised LLM companies not to "blindly cut prices" precisely because very few model architectures and inference optimizations can keep API costs from running at a loss. If more architectures that save compute and KV cache emerge, along with better inference Infra to drive down API costs, this will form an excellent virtuous cycle in the industry.
More crucially, affordable, high-performance model APIs will drive real, sustained, and at-scale inference demand. This upstream demand pulls forward the development of the entire AI infrastructure chain—including chips, servers, optical transceivers, PCBs, liquid cooling, power, energy storage, and data centers—serving as a strategic fulcrum for a systemic revaluation of AI hardware. In the long run, this injects more affordable and accessible compute into both training and inference pipelines, accelerating the parallel evolution of global AGI across multiple regions and technical routes.
For more technical details, we will release a detailed Blog post later.
English
@TencentHunyuan I'm using HY-MT1 7b right now, and since the day it lauched i've been using it, love this model so much. Happy to have a newer one❤️
English

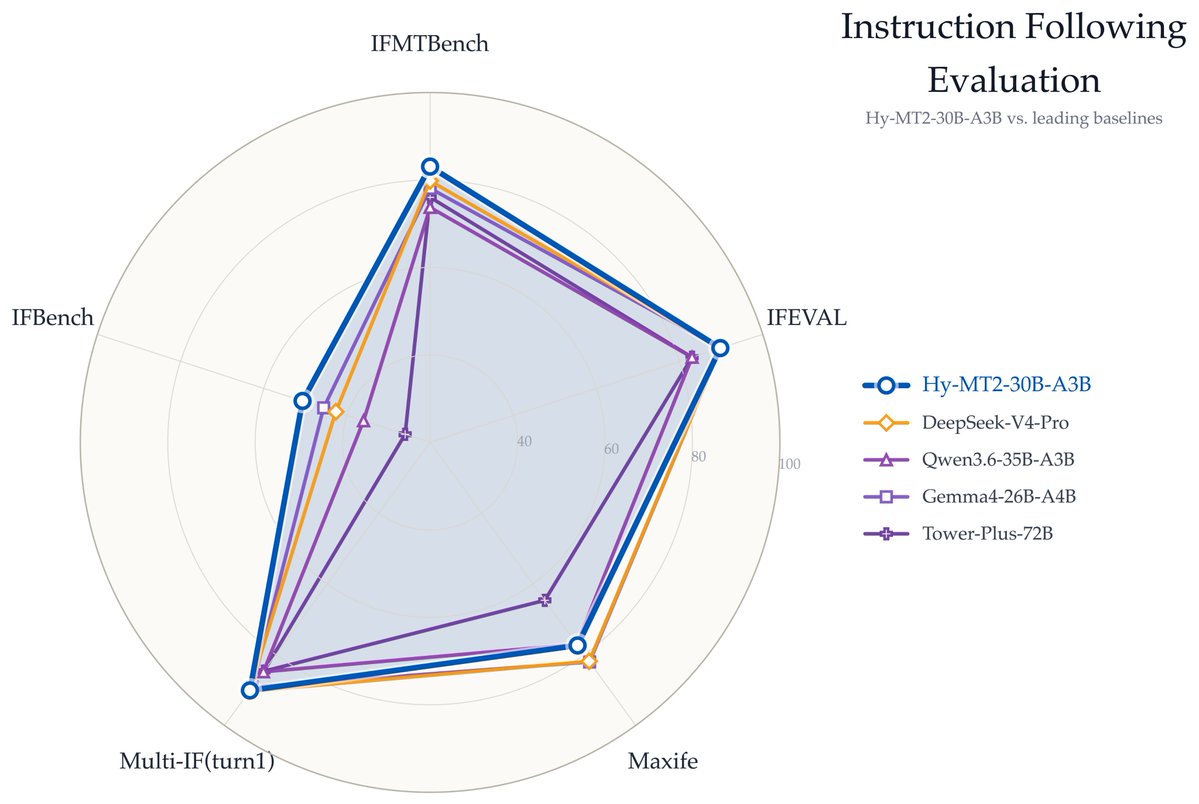
🚀 Introduce Hy-MT2: New Open-Source Multilingual Translation Model
We proudly launch our new Hy-MT2 translation model and the Tencent Hy Translation mini-program!
Hy-MT2 is a powerful multilingual model supporting seamless translation across 33 languages — and it's fully open-source!
It's 7B and 30B-A3B models achieve state-of-the-art performance among all open-source models on various translation tasks, surpassing models with dozens of times more parameters.
The lightweight 1.8B model even outperforms mainstream commercial APIs like Microsoft and so on. Powered by Tencent AngelSlim 1.25-bit extreme quantization, it needs just 440MB storage and enables effortless local inference on mainstream mobile chips — with 1.5x faster speed vs. Hy-MT1.5.
Open-source AI translation just got way smarter, faster, and more accessible! 🌏
Project Page: aistudio.tencent.com/llm/zh?tabInde…
Hugging Face: huggingface.co/collections/te…
Modelscope: modelscope.cn/collections/Te…
Github: github.com/Tencent-Hunyua…


English
@ChujieZheng How could u guys maxxing RL but in the meanwhile achieved lowest Hallucination Rate in AA omniscience?
Is that data related?😳
English

For Qwen3.7-Max, we have invested far more compute into RL training than ever before. Its top-tier AA score confirms the resulting general and agentic capabilities.
This is just the start. We will firmly push forward RL scaling to build more powerful Qwen models. Stay tuned!
Artificial Analysis@ArtificialAnlys
Alibaba’s new Qwen3.7 Max model scores 56.6 on the Artificial Analysis Intelligence Index, 4.8 points higher than Qwen3.6 Max Preview (51.8). While Alibaba still trails models from OpenAI, Anthropic and Google, Qwen3.7 Max is the closest they have been to the frontier Qwen3.7 Max is @Alibaba_Qwen's latest proprietary flagship, scoring 56.6 on the Intelligence Index, a 4.8 point gain over Qwen3.6 Max Preview (51.8) released in April. Qwen3.7 Max continues Alibaba's pattern, in place since Qwen2.5 Max (January 2025), of releasing Max and Plus models as closed weights while the rest of the Qwen line remains open weights. The leading open weights Qwen on the Intelligence Index is Qwen3.6 27B (Reasoning, 45.8) released in April 2026, and the leading open weights MoE Qwen is Qwen3.5 397B A17B (Reasoning, 45.0) released in February 2026 Key takeaways for the reasoning variant: ➤ The Intelligence Index gains over Qwen3.6 Max Preview are concentrated in scientific reasoning, agentic capability and coding. CritPt +9.7 p.p (3.7% to 13.4%), HLE +9.2 p.p (28.9% to 38.1%), TerminalBench Hard +6.9 p.p (43.9% to 50.8%) and GDPval-AA +42 Elo (1504 to 1546). Scores on other benchmarks in the Intelligence Index are flat compared to Qwen3.6 Max Preview ➤ A significant share of the Intelligence Index gain is driven by higher abstention on AA-Omniscience, not higher accuracy. Qwen3.7 Max's accuracy on AA-Omniscience dropped 7.6 p.p (37.7% to 30.1%), while its hallucination rate dropped 21.3 p.p (44.2% to 22.9%). The model is choosing not to answer more questions rather than recalling more facts. Because hallucination rate and accuracy both feed into the Intelligence Index, the hallucination reduction is one of the larger single contributors to the +4.8 point gain on the Intelligence Index ➤ Qwen3.7 Max used 96.7M output tokens to run the Intelligence Index, ~31% more than Qwen3.6 Max Preview (73.9M). It sits mid-pack on frontier token usage: above GPT-5.5 (high, 44.5M) and Gemini 3.1 Pro Preview (57.3M), below Claude Opus 4.7 (Adaptive Reasoning, Max Effort, 112M), Kimi K2.6 (166M) and DeepSeek V4 Pro (Reasoning, Max Effort, 187M) Key model details: ➤ Context window: 1M tokens (up from 256K on Qwen3.6 Max Preview) ➤ Multimodality: Text input and output only ➤ Pricing: Yet to be announced (Qwen3.6 Max Preview is priced at $1.30/$7.80 per 1M input/output tokens on the @alibaba_cloud first-party API) ➤ Licensing: Proprietary, closed weights
English
@AnthropicAI yes dude, if u dont want to opensource ur llm, opensource ur safety approaches
English

New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
English