Sabitlenmiş Tweet

Inference Optimizations Behind the MiMo-V2.5 Series API Price Reductions
Read the full technical blog: mimo.xiaomi.com/blog/mimo-v2-5…
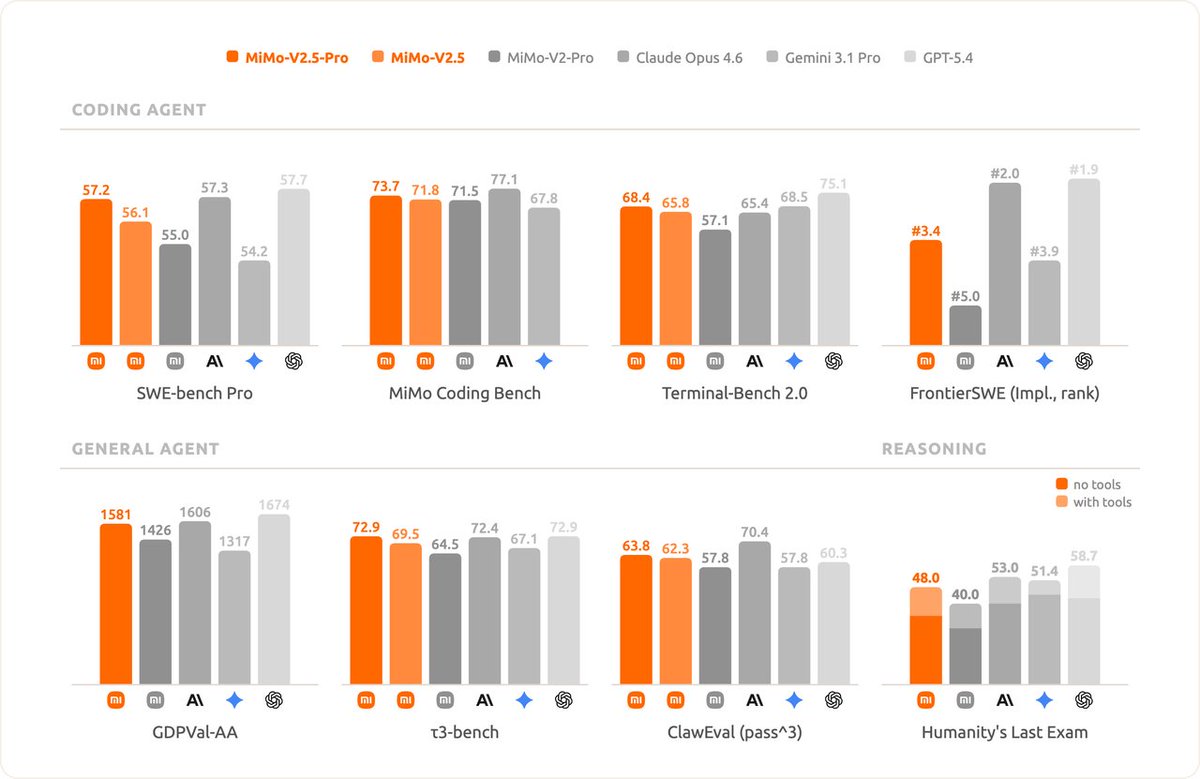
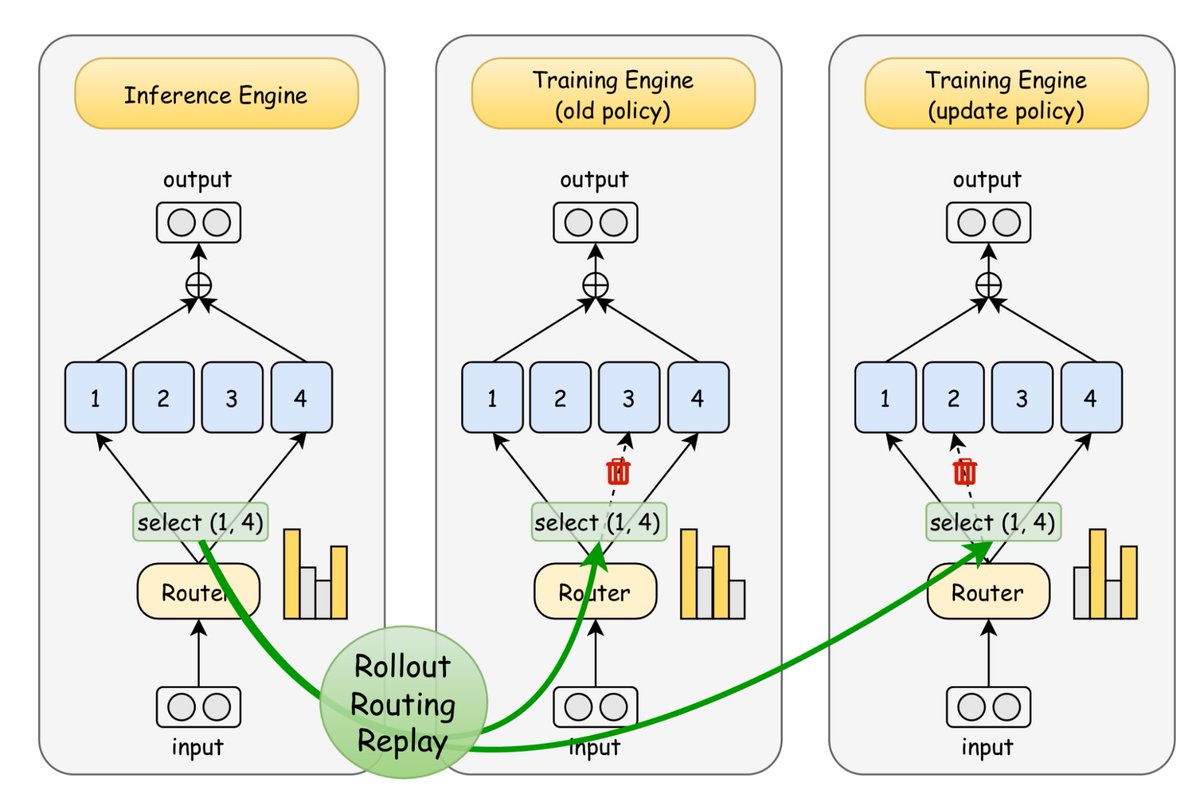
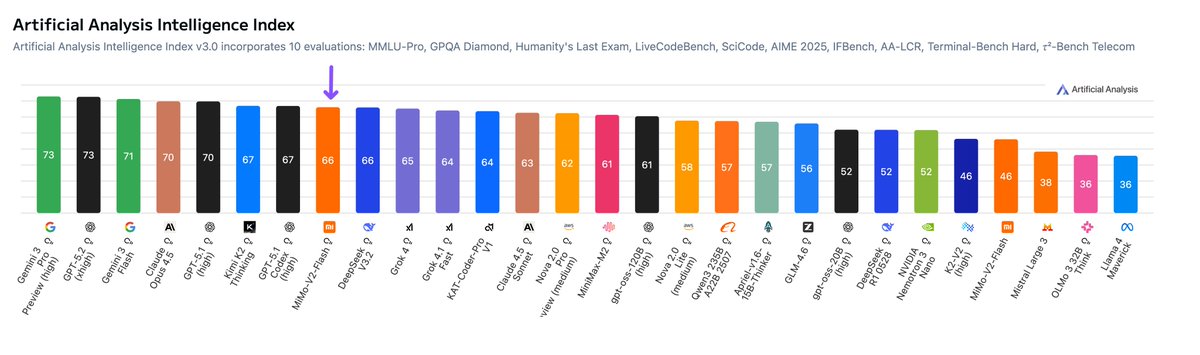
The V2.5 model family, including MiMo-V2.5 and MiMo-V2.5-Pro, is built on a Hybrid Sliding Window Attention (Hybrid SWA) architecture, which compresses KVCache storage to roughly 1/7 that of Full Attention. However, architectural advantages rarely translate directly into measurable gains in production serving. To realize these gains, we redesigned KVCache management, tiered caching, and the prefix-cache tree; addressed key challenges in SWA KVCache handling; and optimized scheduling as well as the Prefill/Decode pipeline.
Validated on real production traffic, these optimizations have increased effective KVCache capacity by nearly 5x, with server-side cache hit rates averaging 93%–95% across mainstream harness frameworks. Together with MoE configuration tuning and multimodal inference optimizations, they enable more efficient long-context inference and form part of what makes the recent API price cuts possible.
English