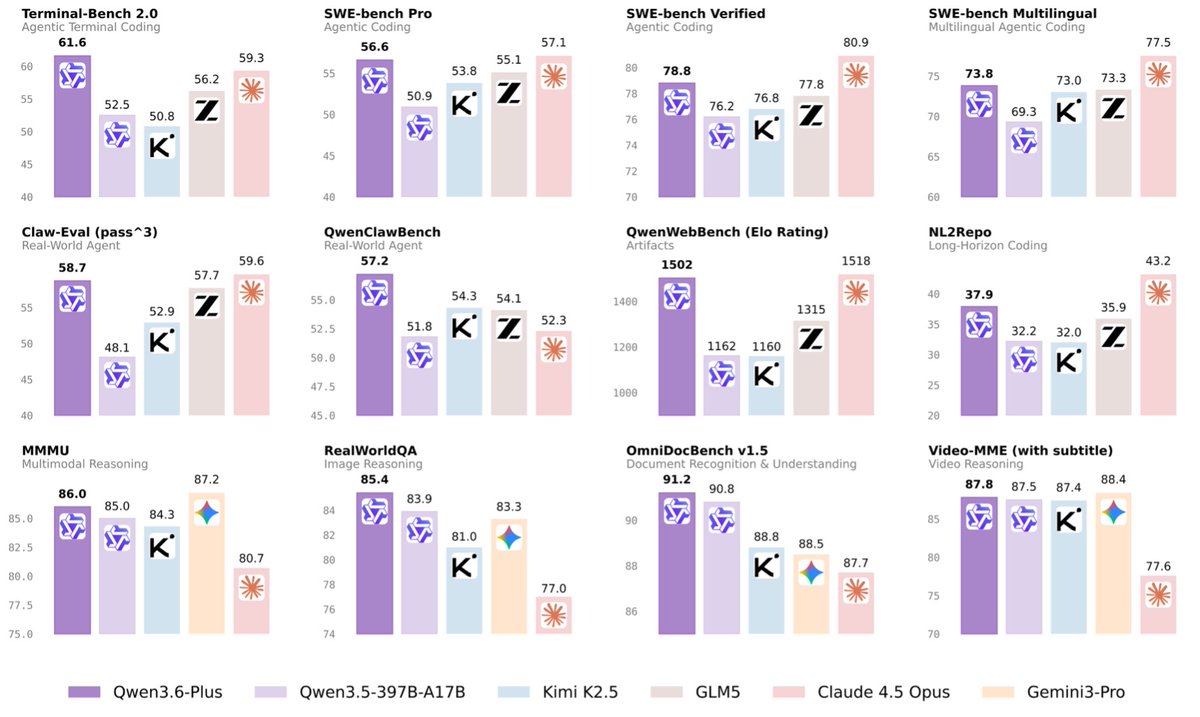
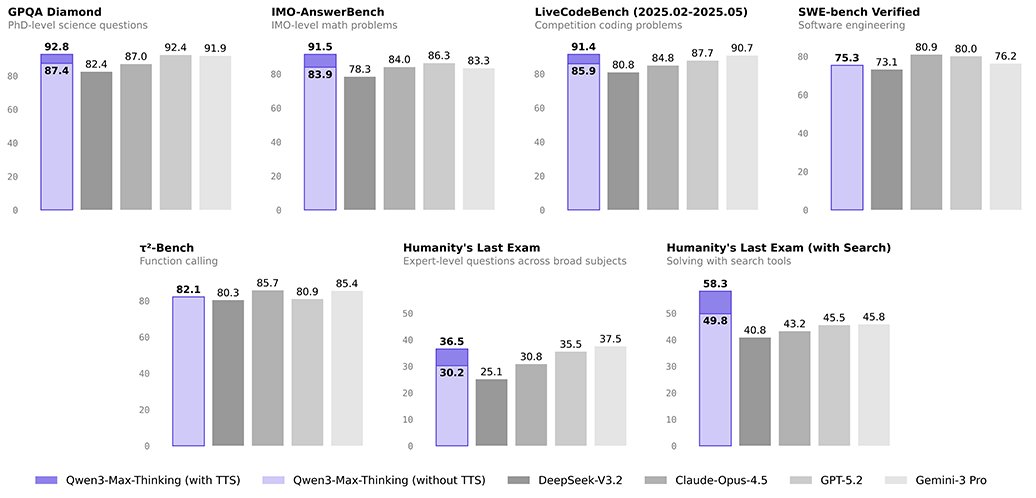
We are excited to release Qwen3.7, featuring an extended version of our environment scaling approach. To maximize generalization across diverse downstream agentic tasks, we deliberately restricted ourselves from prior knowledge of many of the evaluations, which were not selected until pre-release, making them fully blind tests on out-of-domain environments.
The resulting scaling behavior is notably predictable: performance gains across any subset of benchmarks reliably correlate with gains on the rest, consistent with genuine capability generalization. Details in the upcoming technical report.
#qwen
Qwen@Alibaba_Qwen
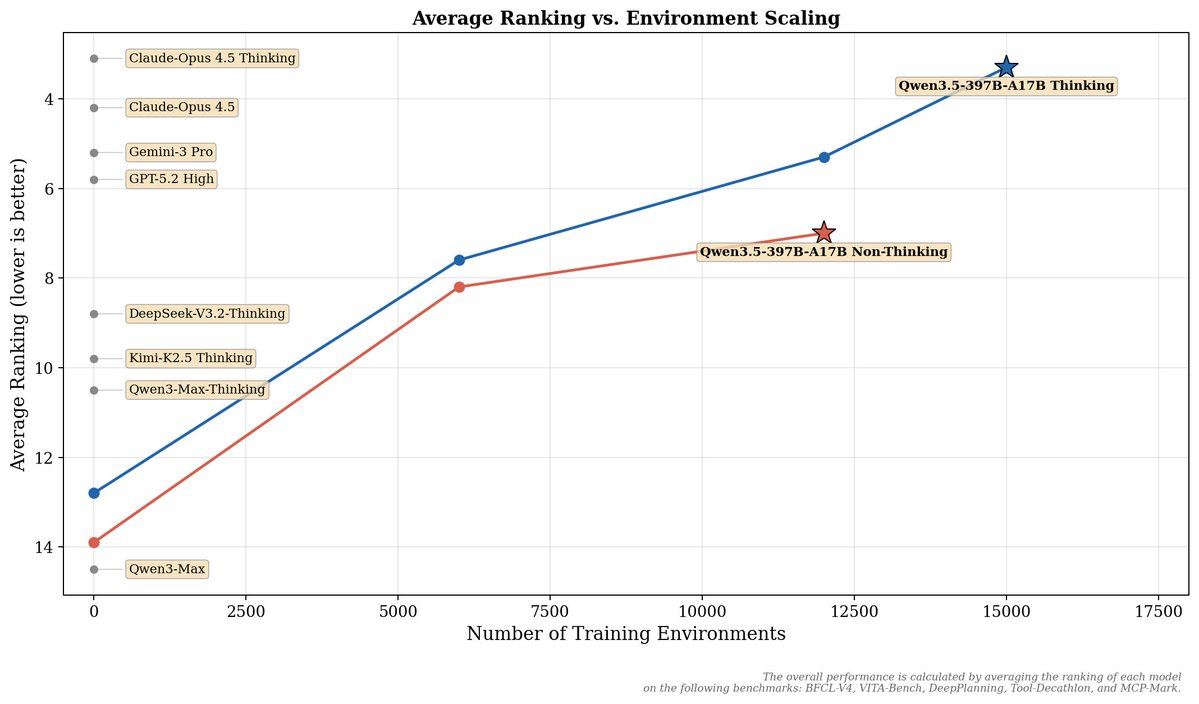
Agent Scaling:Building on Qwen3.5's environment scaling approach, we've aggressively expanded the quality and diversity of agentic training environments in Qwen3.7 — agentic capabilities generalize from diverse environments, just as language models do from diverse text. The figure below shows a clear and consistent improvement trajectory, with Qwen3.7-Max achieving a top-3 average ranking that approaches Claude-4.6-Opus-Max.
English