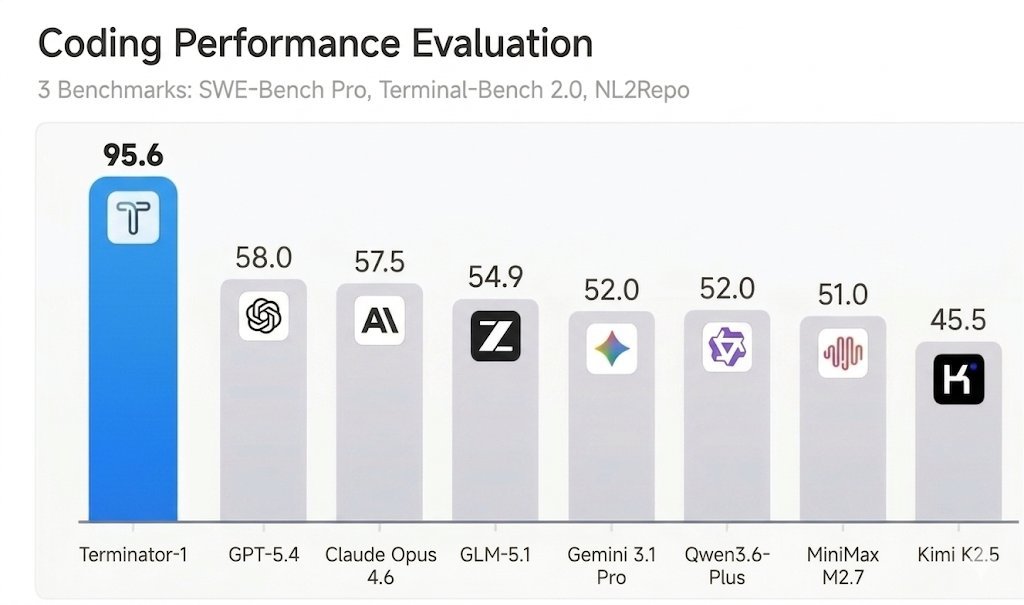
why preview
DeepSeek@deepseek_ai
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n
English