Version control manages code. CI/CD manages deployment. Observability manages production.
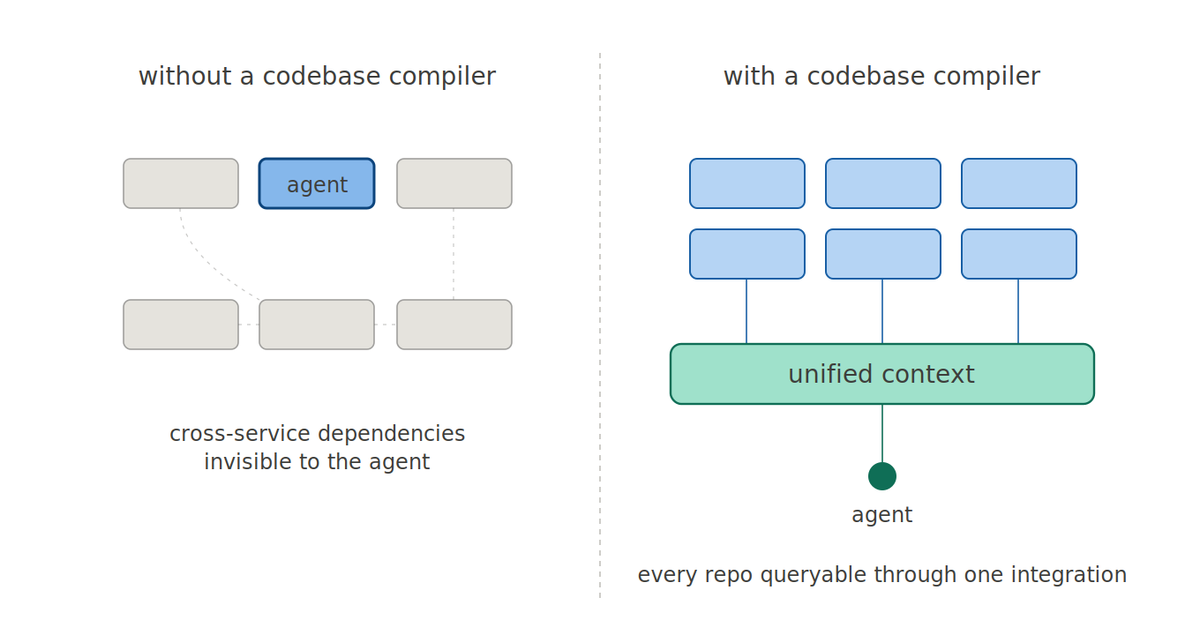
But, nothing manages context.
That is the framing Adam laid out back in January in our most foundational piece on the category we are building. Context is the missing infrastructure layer of modern software development. Without it, development suffers from context collapse.
The shorthand: Driver is to context what Git is to code.
The post explains why context belongs in the same conversation as the other layers of the software stack, why retrieval at runtime is the wrong shape for it, and what compilation makes possible across the full software development lifecycle, not just coding.
This piece is the strategic foundation under both of the conversations Driver is part of over the next few weeks. It describes how to cross the context chasm.
Daniel is giving a talk at Boston Tech Week, co-hosted with Liberty Ventures, on the compiler-based architecture that makes context infrastructure real.
For AI infra founders, investors, and engineering leaders.
Tuesday, May 26 | 6:00 to 8:00 PM | Boston, MA
RSVP: lnkd.in/dFDU29KG
Adam is hosting a roundtable at NY Tech Week with engineering leaders from Optiver, ShipBob, and Lucanet on what is working and what is not when teams adopt agentic tools at production scale.
Shipping Faster with AI: What's Working and What's Not
Thursday, June 4, 4:00 to 7:00 PM | New York, NY
RSVP: partiful.com/e/5K5c4eODrGPK…
The post: driver.ai/blog/context-i…
#AI #SoftwareDevelopment

English