"Driver is to context what Git is to code."
Adam wrote that line in January in a piece that I think is the most important framing argument we have made as a company. The full argument is that context is the missing infrastructure layer for the AI-augmented software development lifecycle.
In this case, the phrasing matters. Infrastructure is not a feature. Infrastructure is the thing you stop thinking about because it just works as core part of technology stack. Version control is infrastructure. CI/CD is infrastructure. Observability is infrastructure. Each one was once a manual process before someone built the right substrate underneath it.
Context today is where version control was 25 years ago. Tribal knowledge, stale documentation, repeated discovery are all issues that needed to be addressed by core infrastructure technology. Otherwise, every new engineer relearns what others already know, and similarly, every agent re-gathers the same information. Things go sideways when the senior engineer who actually understands the system as a whole leaves because the architecture leaves with them.
My work on the technical side has been about making these ideas real:
Compilation as the architectural pattern
Pre-compilation as the answer to runtime discovery
MCP as the integration layer to runtime agents
The substrate is the thing that turns Adam's strategic claim into something a customer can actually deploy.
This is the foundation under the talk I am giving at Boston Tech Week next week. The post lays out the why. The talk goes deep on the how.
The post: driver.ai/blog/context-i…
The talk is co-hosted with Liberty Ventures. For AI founders, investors, and engineering leaders.
Tuesday, May 26 | 6:00 to 8:00 PM | Boston, MA
RSVP: lnkd.in/dFDU29KG?utm_s…#AI#SoftwareDevelopment
I posted about multi-branch support when we shipped it a few weeks back. Bringing it up again because it connects to one of the threads in my #BosTechWeek talk later this month.
A compiler that only sees one branch is not compiling the codebase. It is compiling a snapshot.
The talk covers this and a few other parts of the same argument: why a compiler-based architecture is the right answer to the context chasm AI coding agents face at scale. If your team has hit this wall, it is worth catching live.
The post: driver.ai/blog/from-one-…
RSVP for Boston, co-hosted with Liberty Ventures: partiful.com/e/CqAXMakyIu2A…
There's a class of agent failures that's worse than hallucinations: errors of omission.
The agent gives you an answer, and it looks right. So, you ship it. Weeks later you find out it ignored a critical dependency in a service nobody thought to mention.
The model wasn't wrong about what it saw. The context was wrong about what it showed.
This is what happens when context gets assembled at inference time. The engineer pastes some files, and the agent reads a few more. You both convince yourselves you've covered the ground. Unfortunately, you haven't, and the agent can't flag what's missing simply because the missing information isn't there.
You don't fix this with better prompts. You fix it by pre-compiling context so that it's exhaustive, high signal-to-noise in nature, and available to every engineer on every task.
You have to cross the context chasm to avoid context collapse.
Adam's full argument below: driver.ai/blog/claude-an…
"Search returns relevance. Compilation returns truth."
This is the architectural bet we made at Driver.
Daniel walks through exactly why in his latest piece: how a compiler frontend, atomic guiding documents, and a focused runtime step jointly solve the exhaustiveness vs. signal-to-noise problem that no RAG system can.
If you've been curious about why Driver is built the way it is, this is the post: driver.ai/blog/compiling…
Most AI coding tools treat context as a search problem, and that is why they hallucinate at the wrong moments. Search is probabilistic by design while compilation isn't. When you compile a codebase the difference is that
-every symbol is resolved,
-every reference is traced,
-every dependency is captured.
And, this is all done exhaustively and deterministically.
Search returns relevance, which is fine for product recommendations and bad for code, but compilation returns truth.
We have build around this distinction. The compiler runs once, and the index is structurally complete...and the agent queries against grounded truth instead of best-guesses.
Full architectural argument here: driver.ai/blog/compiling…
𝗛𝗼𝘄 𝗗𝗿𝗶𝘃𝗲𝗿 𝗕𝗲𝗰𝗮𝗺𝗲 𝗜𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗳𝗼𝗿 𝗖𝗼𝗱𝗲 𝗘𝘃𝗼𝗹𝘂𝘁𝗶𝗼𝗻
Building the infrastructure to compile context over arbitrarily sized and shaped codebases and deliver it at enterprise scale has involved a lot of foundation laying. Up to this point, Driver has had a one-branch view of the world: one blessed (default) branch per codebase, and that's it.
We've now expanded to the full, multi-dimensional truth of a living codebase by putting in place a final keystone to our original vision: multi-branch support. In this post, I'll discuss our motivations, how we built it, and interesting challenges along the way.
𝗪𝗵𝘆 𝗧𝗵𝗶𝘀 𝗠𝗮𝘁𝘁𝗲𝗿𝘀 𝗡𝗼𝘄
𝗧𝗵𝗲 𝗕𝗿𝗮𝗻𝗰𝗵 𝗚𝗮𝗽: 𝗠𝘆 𝗘𝘅𝗽𝗲𝗿𝗶𝗲𝗻𝗰𝗲
I'll motivate by sharing my experience as a daily user of Driver. I haven't written a line of code by hand since December 2025, but I've shipped more substantial code in Q1 2026 than ever before. This story is being told a lot today and my version is for another day (although we're very excited to share more about our agentic SDLC at Driver).
For me, and many others, what made this possible isn't just how flagship models and agent rigs came together at the end of 2025, but also using disciplined, structured AI SDLC processes on top. Driver the product has been a crucial part for all of us developing this way at Driver. To paint with broad strokes, our SDLC process includes major pillars with concrete transition points between them and effective orchestration.
The first two pillars are research and planning, and Driver is particularly critical in these stages. They're dominated by fact-finding, bringing threads together, concerted design, and making informed decisions. Missing critical context early poisons the whole process. You want to capture all of the critical context so you can make the right design decisions and guarantee smooth downstream implementation.
I've gotten very comfortable and confident with this Driver-infused process. But as I move into later stages, I've had to stop using Driver because its state is only up-to-date with the default develop branches in our codebases.
Fast-forward past planning and validation: we're deep into implementation with Claude. Something breaks, an unexpected integration problem surfaces, or you realize you need to revise even the best initial plan. What I really need is to evaluate in the context of both the codebase's pre-feature state and the partial implementation I'm deep into. Because Driver lacks the latter, I must forge ahead without it — losing that warm trust that comes from Driver's exhaustive guidance for Claude.
I ran into more and more of these scenarios where I wanted to reach for Driver but couldn't because the delta between the relevant state and Driver's single-branch knowledge would be a problem:
- 𝗛𝗮𝗻𝗱𝗼𝗳𝗳 𝘁𝗼 𝗿𝗲𝘃𝗶𝗲𝘄𝗲𝗿𝘀: We're not just using AI to write code, but to help us review and assess. Ideally a reviewer uses Driver to ask questions about the feature, validate architectural concerns, and be a critical advisor in review. But the feature branch isn't tracked.
- 𝗣𝗿𝗲-𝗺𝗲𝗿𝗴𝗲 𝗱𝗲𝗯𝘂𝗴𝗴𝗶𝗻𝗴: Driver is an excellent tool for investigating bugs and issues. But when testing surfaces bugs prior to merge, Driver is at maximum delta with respect to its knowledge of the code under test.
- 𝗖𝗿𝗼𝘀𝘀-𝗯𝗿𝗮𝗻𝗰𝗵 𝗮𝘄𝗮𝗿𝗲𝗻𝗲𝘀𝘀: We're building fast and in parallel at Driver. Sometimes I want to pull in information from a colleague's parallel feature branch that I know will need to work together with mine.
𝗠𝘂𝗹𝘁𝗶-𝗕𝗿𝗮𝗻𝗰𝗵 𝗶𝘀 𝗮 𝗠𝘂𝘀𝘁 𝗳𝗼𝗿 𝗘𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗦𝗰𝗮𝗹𝗲
For larger enterprises, there are further high-value scenarios that depend on multi-branch support: long-term debugging and support for release branches, very long-lived branches beyond individual feature scope, and broad ticket analysis and project management efforts. Multi-branch is table stakes for large-scale enterprise adoption.
We have strong conviction about how emerging AI SDLCs and orchestrators will mature and become the dominant way software is developed. It's an exciting new world with a lot of active experimentation. But however you slice it, the AI is systematically operating in a structured loop. The value of a structured SDLC is similar to our compiler architecture — structure and constraints provide guarantees, repeatability, and scaling. This is a sweet spot for Driver, but only if it closes over all branches of software in the SDLC.
𝗛𝗼𝘄 𝗪𝗲 𝗕𝘂𝗶𝗹𝘁 𝗜𝘁
𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲
Supporting multi-branch required changes to our core data model and represents a major scale-up for our transpiler. Previously, we needed to consume and process hundreds or thousands of codebases, each with hundreds of thousands or millions of lines of code. Now we want to multiply that by processing many or all of the remote branches per codebase. That's a big jump. A lot of our focus was on designing this to be simple, stable, and scalable.
𝗚𝗶𝘁-𝗜𝗻𝘀𝗽𝗶𝗿𝗲𝗱 𝗖𝗼𝗻𝘁𝗲𝗻𝘁 𝗗𝗲𝗱𝘂𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻
At the onset, we were drawn to Git's snapshot model as directly relevant to what we're trying to do. We make significant use of the file structure of a codebase. We deviate into other graph structures — language syntax trees and symbol tables at lower levels, conceptual and functional ontologies at higher levels — but the file tree forms a directed acyclic graph (DAG) at an excellent medium granularity for representing and traversing a codebase. A Git-like snapshot model is attractive in this context for efficiency and scalability.
Properties of a multi-branch world for us:
- A considerable fraction of nodes (files and folders) in the file tree will be redundant across branches.
- From an infrastructure perspective, a branch is just another snapshot to process — our existing single-branch update flows extend naturally.
Properties of a Git-like snapshot model that make sense for us:
- Branches are cheap to create and destroy, effectively lightweight pointers on a core snapshot model.
Properties that are different or unique to us:
- Folders are first-class citizens in a way they are not for Git.
- The Driver model includes one additional level: a 1:many relationship between a node (file or folder) and many pieces of Driver-derived content on top of the raw source.
- Deduplication applies not just to source content (as in Git) but also to expensive LLM content generation. Git deduplicates storage; Driver deduplicates computation. Same content hash means not just the same stored bytes, but the same generated documentation.
𝗕𝗿𝗮𝗻𝗰𝗵𝗲𝘀 𝗮𝘀 𝗙𝗶𝗿𝘀𝘁-𝗖𝗹𝗮𝘀𝘀 𝗘𝗻𝘁𝗶𝘁𝗶𝗲𝘀
With the deduplication discussion and Git snapshot analogy established, we can talk about how branches fit into our core data model:
PrimaryAsset → Branch → Version → VersionNode ↔ Node → DerivedContent
PrimaryAssets (codebases) have many branches, which have many versions (effectively commits), which have many graph nodes (files and folders), each of which can have many kinds of Driver-derived content.
The key developments for multi-branch are the insertion of Branch into this chain and the VersionNode ↔ Node break from what is otherwise a cascade of 1:many relationships.
Two things to call out:
- The chain of 1:many relationships (PrimaryAsset → Branch → Version) gives us a clean tree structure that keeps things simple to reason about, query, and enforce constraints on.
- We intentionally break this at the Node level to gain the massive efficiency benefits of deduplication analogous to Git's snapshot model. The same Node — identified by content hash — can appear in multiple Versions across branches via VersionNode. This is the one place we introduce relational complexity, and it's precisely the mechanism that makes multi-branch economical. Below this, Node → DerivedContent is 1:many again.
𝗟𝗲𝗮𝗻𝗶𝗻𝗴 𝗼𝗻 𝘁𝗵𝗲 𝗗𝗶𝗳𝗳 𝗨𝗽𝗱𝗮𝘁𝗲 𝗙𝗹𝗼𝘄
We've long built and developed an update flow so that new commits and PR merges are handled economically and precisely. Our systematic structure and file tree model — which closely mirrors VCS systems like Git — mean that when an update comes in, we can shrink-wrap generative updates to precisely the parts of our trees affected by the change.
If you squint, branches don't fundamentally change this picture. There are devils in the details (and unlike Git, we have derived content, not just source content, to deal with), but this meant we could leverage and extend the existing update flow to handle multiple branches.
The most important consideration has been content at levels of abstraction above individual files. We generate intermediate representations (IRs) at many levels, all the way up to documents coupled to the codebase as a whole — our "deep context documents" like architecture and onboarding guides. These don't line up neatly with file-delineated diffs. We've been building and strengthening an update flow for these higher-level components for single-branch commits for some time, and have now extended these algorithms for onboarding branches from a previous state (e.g., the direct parent branch). This is important because greenfield generation of deep context documents can be very expensive in tokens — and completely unnecessary given the extensive overlap with "nearby" branches.
𝗜𝗻𝘁𝗲𝗿𝗲𝘀𝘁𝗶𝗻𝗴 𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲𝘀
I've alluded to challenges of scale and efficiency. Here I'll highlight specific challenges the team overcame during implementation.
𝗕𝗿𝗮𝗻𝗰𝗵 𝗣𝗿𝗼𝘃𝗲𝗻𝗮𝗻𝗰𝗲
You might think branch provenance is trivial. From a full-integrity Git perspective, that's generally true. But we are not 1:1 with every commit that has ever been pushed, for a host of reasons. These include not wastefully generating content for commits in the remote past relative to the onboarding date (though we do compile a changelog for this purpose) and the choice to treat PR merges as a single content-generating event rather than walking the incoming branch's commits individually.
We must avoid greenfield onboarding for new branches at all costs — it's prohibitively expensive in tokens and time at scale, and it's assuredly unnecessary since some other branch state will be a good starting point.
Consider: a new branch appears with no immediately obvious provenance — say a commit to a branch that hadn't been touched in two years. We also encounter cases specific to Driver onboarding (discussed in the next section). For these cases, the team built a "find best previous version" algorithm that walks parent commits and computes smallest diffs from other branches, including those with no direct relationship from Driver's perspective, to settle on the best-fit starting point for onboarding based on the diff update flow described earlier.
𝗢𝗻𝗯𝗼𝗮𝗿𝗱𝗶𝗻𝗴 𝗮𝘁 𝗦𝗰𝗮𝗹𝗲
Before multi-branch, onboarding events could already be large relative to continuous operation. Think of greenfield processing hundreds of codebases, each with hundreds of thousands or millions of lines of code. This is routine for large enterprise customers.
Now add that each codebase may have hundreds of branches. We delineate between connecting a codebase (pulling in the source, running Git-based analytics, and populating base metadata) and generating all of our transpiler content. These are separate steps. For the multi-branch world, our solution is to discover and upsert all branches at first connection. Then for content generation:
- Smart-filter the branches committed for generation to those last updated in the last N days (default 14).
- The default branch is always onboarded in full first.
- Remaining branches are processed sequentially, ordered by most recent activity.
- After initial onboarding, every new or previously unprocessed branch that receives an update is onboarded automatically.
This relatively simple heuristic serves us well. Because of the default-first, most-recently-updated ordering and strict sequential processing, subsequent branch onboarding events are likely to have ideal jump-off points: actual parent branches or very near-state branches. We only do a single heavy greenfield onboarding for the default branch. Existing feature branches, for example, will be significantly identical to the default branch and benefit from extensive deduplication. This algorithm can lead to scenarios where a child branch serves as the base to create state for a parent, but our diff update algorithm handles time inversion gracefully!
𝗠𝗖𝗣 𝗧𝗼𝗼𝗹 𝗦𝘂𝗿𝗳𝗮𝗰𝗲 𝗔𝗿𝗲𝗮 𝗮𝗻𝗱 𝗖𝗼𝗺𝗽𝗹𝗲𝘅𝗶𝘁𝘆
The MCP tool set — and more broadly the API endpoints that back it — is a critical surface area and the primary product experience for many of our users. We care a lot about keeping this API surface stable and carefully vet any changes. We want to avoid both tool sprawl and excessive input complexity.
Multi-branch introduces a real tension here. Agentic systems must be able to target specific branches, but this adds another dimension to every tool call. Agents already need to index into specific codebases; now they must index into codebase and branch. The challenge is compounded by the diversity of usage contexts: in a local IDE, the codebase name and branch are trivially discoverable via Git metadata. But in chat agents, background agents, and other contexts divorced from an IDE-like experience, even codebase discovery is a much more dynamic problem. Adding branch specificity makes this more onerous.
Our approach: add an optional branch_name parameter to each tool. Omit it and the default branch is assumed — the right fallback for agents that don't have branch context or don't need it. Specify it and you get full branch-level targeting. We also added a get_branches discovery tool so branch-aware agents can enumerate available branches before querying.
𝗧𝗼𝘄𝗮𝗿𝗱 𝗡𝗲𝘄 𝗖𝗼𝗱𝗲 𝗘𝘃𝗼𝗹𝘂𝘁𝗶𝗼𝗻 𝗜𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲
Multi-branch elevates Driver to a ubiquitous context layer at the largest scales. Developers, product managers, and executives can all work with AI tools with high trust because Driver is now up-to-date with whatever part of the living, branching software system their current needs relate to.
The remaining gap is uncommitted local changes, a dramatically smaller surface area than the branch-wide blind spot we started with. We'll monitor whether we need to close this gap further as we move forward.
This has been a long-anticipated step in our vision. Building the foundational infrastructure — the content pipeline, the deduplication model, the inspector system, deep context generation — took time and care. Multi-branch is a keystone. With it, we can aggressively pursue the full context layer vision: deeper automatic tracking and context generation for code evolution across branches, and deeper integration with emerging AI SDLCs.
Every branch is a line of development. Every line of development deserves comprehensive context. We're excited about what comes next.
Matt Nassr at Optiver described a pattern we keep hearing from engineering leaders.
His researchers and traders got dramatically more productive once AI entered the workflow. They consumed pipelines faster, asked sharper questions, ran more experiments. Nobody planned for who would answer all those questions.
The questions were reasonable. Does a feed exist for this instrument? What fields does this market dataset expose? Can this pipeline support intraday resolution? Context questions, not research problems. The kind a well-indexed system should answer on its own.
The system couldn't. So the questions routed to the engineers who built it. Senior people who should have been designing next-gen infrastructure were burning real chunks of their week on lookups.
The AI agents were supposed to handle this. They didn't have reliable context, so they punted humans back into the loop.
Context infrastructure isn't a dev tools problem. It's an org design problem. When your best engineers are the indexing layer for your codebase, the company doesn't scale. It just gets more expensive.
Once Driver gave Optiver's agents a deterministic view of the codebase, the questions stopped routing through people.
driver.ai/blog/optiver-c…
Most engineering teams putting AI coding agents in production walk the same path:
Agents lose context as the codebase moves. A homegrown RAG layer hits a wall. Chunking source code for retrieval breaks the call graph.
That's the path @OptiverGlobal walked before they got agentic coding working.
@DriverAI CEO Adam Tilton sits down with Matt Nassr (VP Data Eng / AI, @OptiverGlobal) at @techweek_ on June 4 for "Shipping Faster with AI: What's Working and What's Not."
Matt spent months on a RAG-based context layer before concluding the architecture was wrong.
The fix: a compiler-based approach that pre-computes the codebase so context arrives complete.
90% less manual context burden. 5x more effective agents.
Case study: driver.ai/blog/optiver-c…
June 4, 4-7 PM, NYC
RSVP: partiful.com/e/5K5c4eODrGPK…#NYTechWeek
Most agentic coding failures aren't model failures. They're context failures.
An agent starts a task and reasons about the code it can see. But the context it actually needs (cross-service dependencies, shared state, the real call graph) isn't visible from where it's sitting.
The output looks right. It isn't.
@DriverAI CTO Daniel Hensley (@dw_hensley) is giving a technical talk on the fix at @techweek_ Boston: a compiler-based approach that pre-computes exhaustive, dependency-aware context ahead of time, so it arrives complete instead of being retrieved on demand.
@OptiverGlobal cut manual context burden 90%, made AI coding agents 5x more effective, and deployed in under two weeks.
Case study: driver.ai/blog/optiver-c…
Tuesday, May 26 | 6-8 PM | Boston
Co-hosted with Liberty Ventures.
RSVP: partiful.com/e/CqAXMakyIu2A…
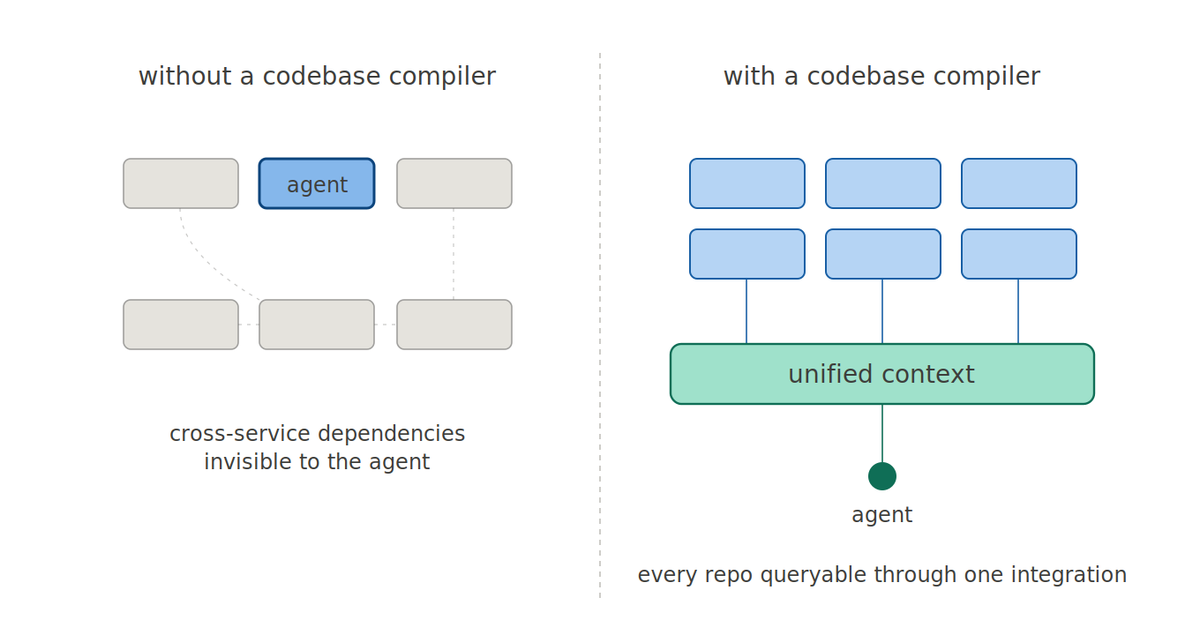
Highly distributed, multi-codebase systems have structural properties that current AI coding tools can't navigate. What we've found is that the multi-codebase problem is a context problem, and context problems are solvable if you treat them as compilation rather than search.
𝗧𝗵𝗲 𝗣𝗿𝗼𝗯𝗹𝗲𝗺
We've been working with engineering teams that have many codebases totaling from 3 million to 40 million+ lines of code. A number of them run microservices architectures with hundreds of repos. A pattern we keep seeing: AI coding agents fall down significantly when a task crosses a service boundary. And when you're developing against a large microservices architecture, this is constant.
Three challenges drive this.
𝗖𝗼-𝗹𝗼𝗰𝗮𝗹𝗶𝘁𝘆. In a microservices architecture, no developer has every relevant repo cloned and open, and often doesn't start a task knowing which repos are relevant. An agent inherits this limitation. It can only reason about what it can see, and in a distributed architecture, most of the relevant context is somewhere else.
𝗜𝗺𝗽𝗹𝗶𝗰𝗶𝘁 𝗱𝗲𝗽𝗲𝗻𝗱𝗲𝗻𝗰𝗶𝗲𝘀. In a monolith, dependencies are explicit via imports, function calls, class hierarchies, etc. and an agent can trace them. In a microservices architecture, the connection is often a URL string in a config file, or two services reading from the same database table without either one knowing about the other. These relationships are real and load-bearing, but invisible to tools that reason at the code level.
𝗡𝗼𝗻𝗹𝗶𝗻𝗲𝗮𝗿 𝗰𝗼𝗺𝗽𝗹𝗲𝘅𝗶𝘁𝘆. A codebase with N symbols has N-squared potential relationships. Teams try to solve this by introducing context about the service layer into their repos, but it doesn't scale: documentation rapidly goes stale and RAG-based approaches chunk code into text fragments, destroying the structural relationships that matter most in distributed systems. Furthermore, identifying the structural connectedness through interfaces of isolated services requires its own derivative analysis.
𝗔 𝗖𝗼𝗱𝗲𝗯𝗮𝘀𝗲 𝗖𝗼𝗺𝗽𝗶𝗹𝗲𝗿 𝗶𝘀 𝗖𝗿𝗶𝘁𝗶𝗰𝗮𝗹
Our approach at Driver starts with what Adam and I call our transpiler: a compiler-like architecture we built that begins by parsing code via static analysis and emits structured context instead of executable code. A core feature here is exhaustiveness. Symbol tables, dependency graphs, and syntax trees are all computed deterministically for every file and symbol in each codebase. This is the foundation, and it matters. It means every codebase we process is understood exhaustively, not sampled.
For microservice architectures, and other intensively multi-codebase systems, we have observed that this exhaustive understanding of each individual codebase is absolutely necessary but not sufficient.
The reason is that the connections between services don't live at the level of syntax analysis or even analysis of any kind of any one codebase. In a monolith, you can follow imports and function calls to trace a dependency. In a microservices architecture, the dependency might be an HTTP endpoint defined in one service and called via a string constant in another (a more difficult version of the "stringly-typed" problem). It might be a shared database table, a message queue topic, or an event schema that two services conform to independently. These relationships are invisible to any tool reasoning within a single repo, no matter how thoroughly it parses the code.
To capture these, we needed to go further: later stages of the transpiler that synthesize across the parsed structure of individual codebases, and a runtime layer that can reason across all of them simultaneously.
𝗔 𝗨𝗻𝗶𝗳𝗶𝗲𝗱 𝗔𝗽𝗽𝗿𝗼𝗮𝗰𝗵 𝘁𝗵𝗮𝘁 𝗨𝗻𝗹𝗼𝗰𝗸𝘀 𝗠𝘂𝗹𝘁𝗶-𝗖𝗼𝗱𝗲𝗯𝗮𝘀𝗲
Two developments have unlocked multi-codebase context.
𝗛𝗶𝗴𝗵𝗲𝗿-𝗹𝗲𝘃𝗲𝗹 𝘀𝘆𝗻𝘁𝗵𝗲𝘀𝗶𝘀. Beyond symbol-level static analysis, later stages of our transpiler produce intermediate representations (IRs) at many different levels of abstraction. These culminate with what we call Deep Context Documents: atomic, codebase-wide documents that describe architecture, major components, how they interact, and (crucially) where to go for more detail. These are synthesized by exhaustive review of all the structured content from earlier transpiler stages. They capture the conceptual and architectural relationships that exist above the code level, including cross-cutting concerns, integration patterns, and service boundaries. For an agent, this solves the "don't know what you don't know" circular problem that is so challenging without exhaustive context.
𝗠𝘂𝗹𝘁𝗶-𝗰𝗼𝗱𝗲𝗯𝗮𝘀𝗲 𝗿𝘂𝗻𝘁𝗶𝗺𝗲 𝗽𝗿𝗶𝗺𝗶𝘁𝗶𝘃𝗲𝘀. We built a runtime layer where an agent connects to Driver via a single MCP integration and can query context across every codebase in an organization. Via the primitive tools, all pre-computed artifacts are queryable per-codebase: architecture overviews, file-level documentation, code maps, changelogs, source files. We also provide a single deep context sub-agent tool. Under the hood, this runs a dedicated context agent with access to all pre-computed artifacts. When a task spans multiple services, the agent queries context from different codebases exactly the way it queries within one. It synthesizes everything into a single, high-signal response tailored to the task at hand and returned to the caller.
The combination is what matters. The transpiler's static analysis gives you exhaustive per-codebase understanding. The higher-level synthesis captures cross-cutting relationships that don't live at the code level. The runtime makes all of it queryable across every codebase simultaneously, so the agent sees the full system, not just whatever repo it happens to be sitting in.
No co-locality requirement, manual assembly, or re-deriving what was already known.
𝗪𝗵𝗮𝘁 𝗪𝗲'𝘃𝗲 𝗦𝗲𝗲𝗻
A customer had a bug where bookings were completing despite no payment records. The investigation spanned 4-5 services across order orchestration, admin, and payments. This bug had been investigated multiple times before and missed. One engineer used Driver to trace the issue iteratively: broad exploration first, then narrowing hypotheses, then precise constraints. Driver pinpointed the exact method where validation logic silently passed orders with zero payment records. Total hands-on time: about 30 minutes. As the engineer described it, instead of needing three people with intensive knowledge of different services, one person got 80% of the way there, then brought in specialists to confirm.
Another team with 200+ microservices built a workflow on top of Driver that takes a single Jira ticket, identifies which repos are impacted, gathers context across all of them in parallel, and generates per-service subtasks with specific file paths, class names, and implementation patterns. The constraint before, as one of their engineers put it: "you've got to know which repos." With all repos accessible through a single integration, that constraint disappeared.
Beyond debugging and ticket analysis, teams report that Driver changes the baseline for development in multi-codebase environments. Concerns that historically slowed work (unknown blast radius, missing context from adjacent services) are addressed by the same cross-codebase context layer. One large microservices team reported 2x average PR velocity team-wide after introducing Driver.
𝗧𝗵𝗲 𝗕𝗿𝗼𝗮𝗱𝗲𝗿 𝗣𝗼𝗶𝗻𝘁
A fundamental tradeoff of microservices has always been autonomy in exchange for complexity. Small, independent services are easy to deploy individually but hard to reason about collectively. AI coding tools struggle with this in the same ways developers do. This is a genuinely complex problem and the fact that tools today (for agents and humans) are often single- or few-codebase centric exacerbates this issue. This tension has significantly held us all back.
What we've found is that this is a solvable problem if you approach it at the right level. Per-codebase exhaustive context compilation is the foundation, but the microservices unlock is at a higher layer: synthesized understanding that captures cross-service relationships, and a runtime that makes it all accessible through one integration. The agent sees the whole system and understands the connections relevant to a particular task.
The more codebases you have, the more immediately this compounds. If your team is running a distributed architecture and your agents are struggling with cross-service work, the issue is probably not the agent. It's what the agent can see.
As a dev community, we keep making the same mistake. We chase better models to fix our AI coding agents. It never works.
Why? Agents don't fail because of the model. They fail because of missing context.
Missing context = AI agents confidently failing.
@OptiverGlobal had 120+ commits/day and millions of lines of code. RAG couldn't keep up.
Driver gave their agents compiler-level context automatically, on every commit.
When you focus on the right problems, the results are dramatic.
90% less manual context work. 5x more effective agents. <2 weeks to deploy.
Read the case study: driver.ai/blog/optiver-c…
In fast-moving codebases, small changes can quickly throw #AI coding agents off. With @driver_ai_ , we introduced a compiler-driven context layer that keeps agents accurate without the manual overhead.
Read the case study:
driver.ai/blog/optiver-c…
Beyond your specific point about dependencies and to the broader pre-computed information in-the-loop for agents point here: This is exactly the thesis we have.
We pre-compute context for codebases to make it impossible for agents to “not know what they don’t know” when working with a codebase. We strive to solve the exhaustiveness limitations of ad hoc or search-only methods. And we build off the raw source code (the source of truth as you say) plus stay up-to-date with each commit.
We heavily use it to research + plan for some time with Claude using our MCP before moving to implementation.
The specific flow of data, what we “pre-compute” with our “compiler,” and how it is exposed via MCP has also been a fun problem to work on:
- Symbol-level documentation with static analysis in the loop.
- Hierarchical code map with pre-computed terse descriptions for each file and folder.
- Higher-level documentation (we call these “deep context docs”) such as codebase-wide architecture docs and an LLM Onboarding Guides that are computed by exhaustive review of the codebase ahead of time and provided as an atomic reference.
The flow we find really effective: an agent (or sub-agent) first consults the codebase-wide content which, in addition to providing directly useful context, makes it aware of all of the places to go look in subsequent iterations (the benefit of exhaustiveness) for the particular task at hand. The symbol/file and navigational tools like the code map are then helpful in these subsequent iterations.
On DeepWiki and increasing malleability of software.
This starts as partially a post on appreciation to DeepWiki, which I routinely find very useful and I think more people would find useful to know about. I went through a few iterations of use:
Their first feature was that it auto-builds wiki pages for github repos (e.g. nanochat here) with quick Q&A:
deepwiki.com/karpathy/nanoc…
Just swap "github" to "deepwiki" in the URL for any repo and you can instantly Q&A against it. For example, yesterday I was curious about "how does torchao implement fp8 training?". I find that in *many* cases, library docs can be spotty and outdated and bad, but directly asking questions to the code via DeepWiki works very well. The code is the source of truth and LLMs are increasingly able to understand it.
But then I realized that in many cases it's even a lot more powerful not being the direct (human) consumer of this information/functionality, but giving your agent access to DeepWiki via MCP. So e.g. yesterday I faced some annoyances with using torchao library for fp8 training and I had the suspicion that the whole thing really shouldn't be that complicated (wait shouldn't this be a Function like Linear except with a few extra casts and 3 calls to torch._scaled_mm?) so I tried:
"Use DeepWiki MCP and Github CLI to look at how torchao implements fp8 training. Is it possible to 'rip out' the functionality? Implement nanochat/fp8.py that has identical API but is fully self-contained"
Claude went off for 5 minutes and came back with 150 lines of clean code that worked out of the box, with tests proving equivalent results, which allowed me to delete torchao as repo dependency, and for some reason I still don't fully understand (I think it has to do with internals of torch compile) - this simple version runs 3% faster. The agent also found a lot of tiny implementation details that actually do matter, that I may have naively missed otherwise and that would have been very hard for maintainers to keep docs about. Tricks around numerics, dtypes, autocast, meta device, torch compile interactions so I learned a lot from the process too. So this is now the default fp8 training implementation for nanochat
github.com/karpathy/nanoc…
Anyway TLDR I find this combo of DeepWiki MCP + GitHub CLI is quite powerful to "rip out" any specific functionality from any github repo and target it for the very specific use case that you have in mind, and it actually kind of works now in some cases. Maybe you don't download, configure and take dependency on a giant monolithic library, maybe you point your agent at it and rip out the exact part you need. Maybe this informs how we write software more generally to actively encourage this workflow - e.g. building more "bacterial code", code that is less tangled, more self-contained, more dependency-free, more stateless, much easier to rip out from the repo (x.com/karpathy/statu…)
There's obvious downsides and risks to this, but it is fundamentally a new option that was not possible or economical before (it would have cost too much time) but now with agents, it is. Software might become a lot more fluid and malleable. "Libraries are over, LLMs are the new compiler" :). And does your project really need its 100MB of dependencies?
We built a code to human language transpiler as the basis of our context layer.
In this article, I articulate how our approach succeeds where previous methods have failed, and the importance of a context infrastructure layer.
x.com/dw_hensley/sta…
Take a look and tell me what you think!
@karpathy@karpathy you mention "The intelligence part suddenly feels quite a bit ahead of the rest of it..." Definitely agree.
Ahead of effective and consistent context management. I'm curious what your take on our exhaustive compiler-based approach would be:
x.com/dw_hensley/sta…
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
For over 2 years, my team and I have been building a technology solution for context engineering at Driver.
We're really excited about our approach, which has been heavily inspired by compiler systems and my background in signal processing. We're equally excited by the results it provides today.
Check this article out where I discuss in detail: x.com/dw_hensley/sta…