Trelis Research@TrelisResearch
++ Reinforcement Learning for LLMs in 2025 ++
===
How to elicit improved reasoning from models?
- Is reasoning innately in pre-training datasets and just needs the right examples to be brought out?
- Why does GPRO make sense, as opposed to Supervised Fine-tuning with the right examples?
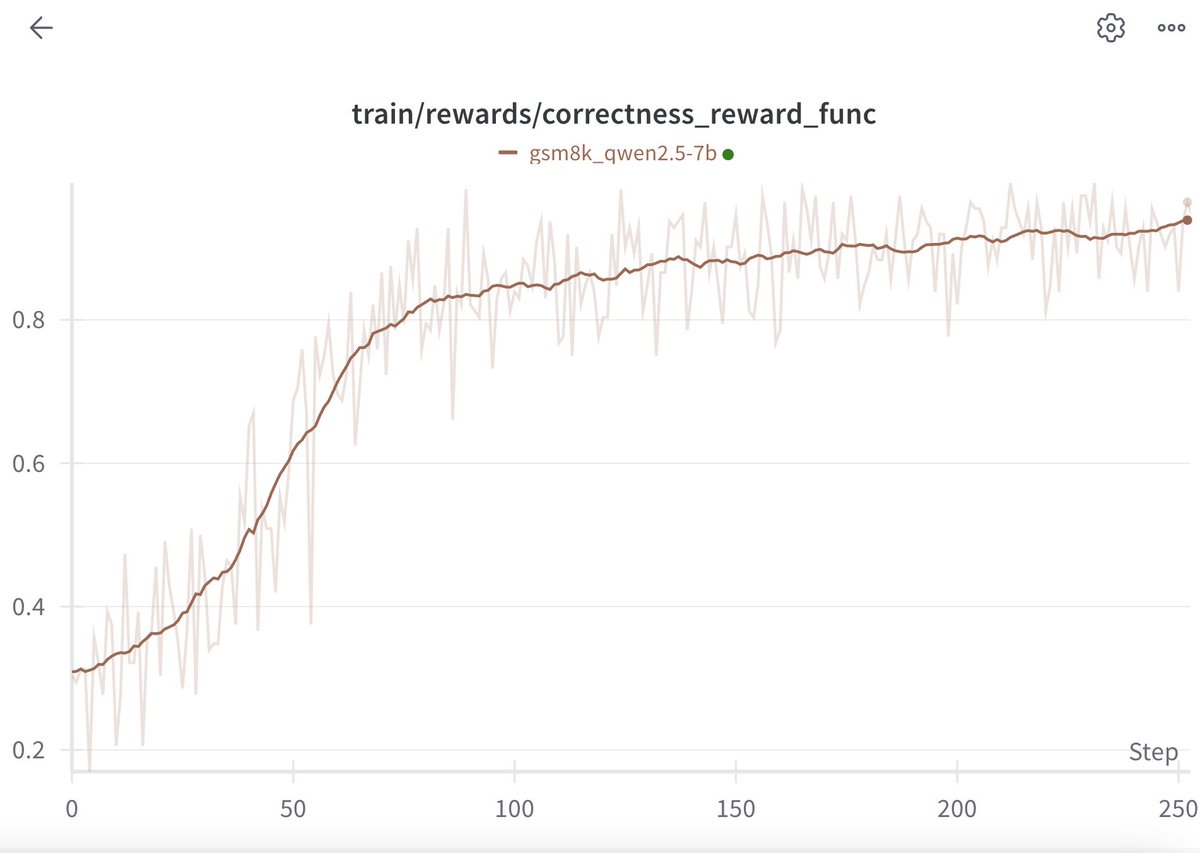
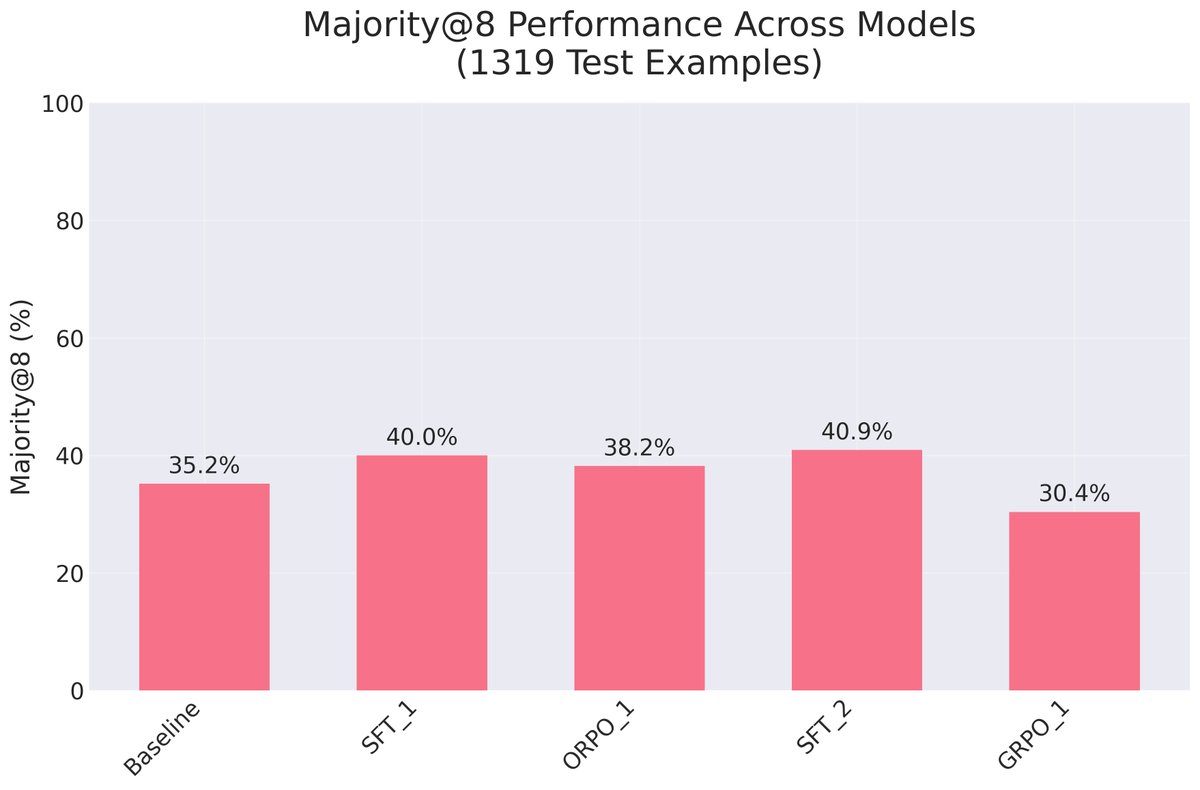
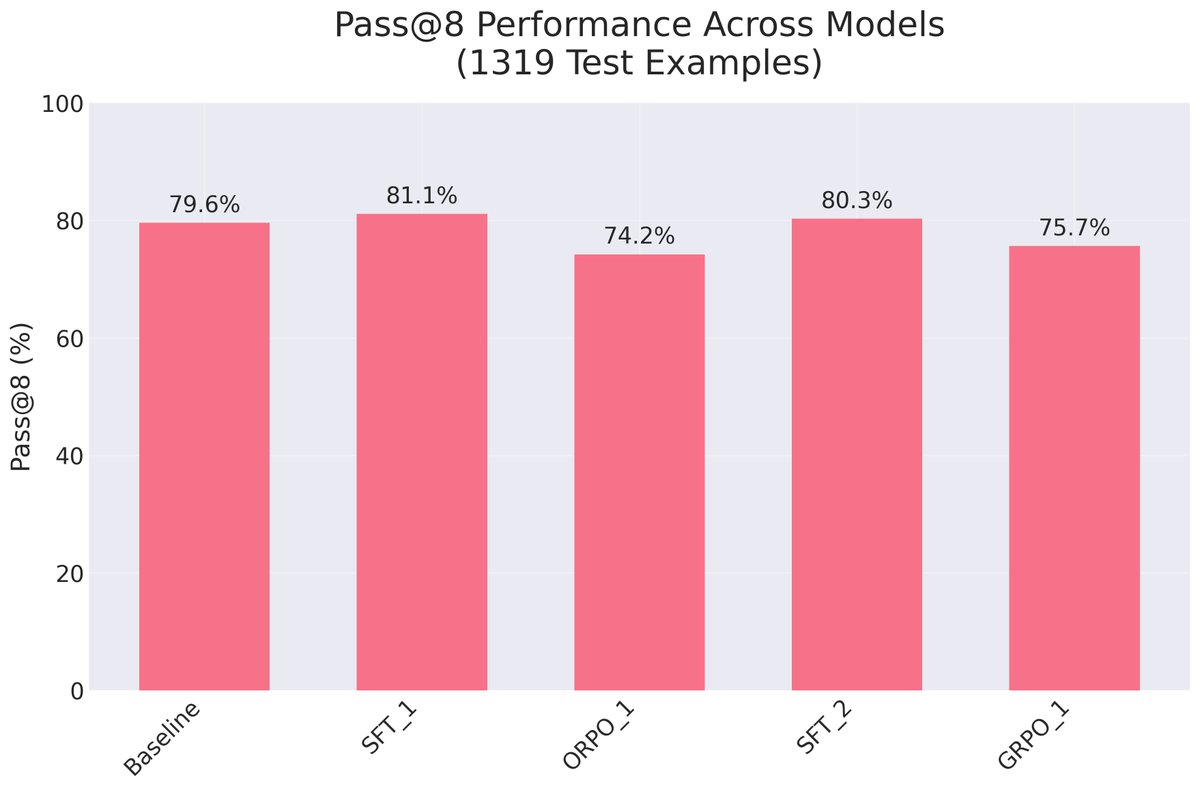
My general sense is that GRPO (or PPO or ORPO) may not offer all that much benefit over SFT. In fact, they generally are more complex. What matters is how the fine-tuning data is created.
This is the first video in a series on Reinforcement Learning.
Maybe you’re looking to directly dig into GRPO - but I think that’s the wrong way to look at things.
A better - ground up approach - is to:
a) start with careful performance measurement (there are gotchas even around how one marks answers correct or not),
b) then carefully think about data preparation,
c) then do Supervised Fine-tuning, and only then
d) start to look at preference and reward methods.
Definitely leave comments if i) you see things that can be improved or I’ve made mistakes on, or ii) you have a specific reasoning dataset in mind that would be useful to see a demo on in the future.
---
+ Timestamps
---
00:00 Introduction to Reinforcement Learning
00:56 Practical Programming for RL
01:59 Setting Up the Environment
02:40 Cloning and Configuring Repositories
04:10 Understanding the Dataset
05:03 Supervised Fine Tuning and Reinforcement Learning
08:54 Downloading and Preparing the Dataset
09:09 Installing Necessary Libraries
13:58 Implementing the Answer Checker
22:30 Running Inference and Evaluating Performance
28:53 Analyzing Results and Setting Baselines
31:03 Batch Inference Script Breakdown
38:00 Preparing for Reinforcement Learning
38:57 Understanding Think Tags in Dataset Generation
39:36 Improving Performance with Supervised Fine Tuning
41:09 Creating and Filtering the Dataset
41:20 Introduction to Preference Fine Tuning
42:21 Generating ORPO Pairs
46:03 Training the Model with Supervised Fine Tuning
49:26 Setting Up and Running the Training Script
50:47 Evaluating the Model's Performance
01:02:35 Exploring ORPO Training
01:07:49 Theory and History of Reinforcement Learning
01:13:54 Final Evaluation and Insights