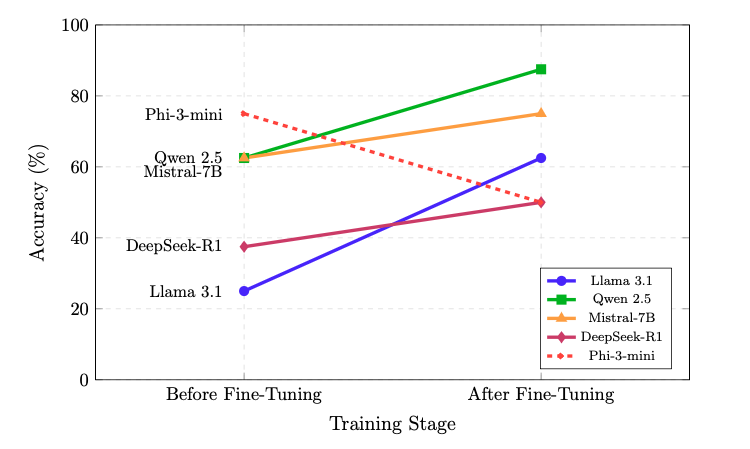
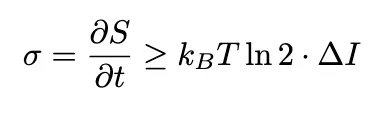It’s clear that current autoregressive models do not equal human intelligence. Everybody knows that. But I do not understand why so much people acts like “well, AI are only good pattern matching systems”. We should remember that our universe started with hydrogen + helium and end up writing poetry.
English