0dteezy
1.4K posts



Aujourd'hui grosse discussion avec mes ingés (chez Argil) sur pourquoi Elon a viré le LIDAR de ses voitures autonomes. Choix radical, moqué pendant des années, et comme d'hab il avait raison depuis le début.
Le LIDAR c'est un laser qui balaye l'environnement et crache un nuage de points 3D. Sur le papier tu obtiens la géométrie exacte du monde. Dans la vraie vie c'est une verrue technologique collée sur le toit parce qu'on sait pas faire mieux avec la vision seule.
Problème numéro un : ça rajoute une modalité dans le training du modèle. Ton réseau doit apprendre à fusionner vision + lidar + radar + ultrasons. Chaque capteur en plus c'est une source de désaccord à arbitrer, pas une source d'info supplémentaire. Sensor fusion artisanale = dette technique permanente.
Problème numéro deux, la bitter lesson de Rich Sutton : scaler le compute sur une seule modalité bat systématiquement les architectures bricolées à la main. Tesla a dropé le radar, puis les ultrasons, est passé full end-to-end vision. Leur courbe sur les edge cases s'est accélérée APRÈS, pas avant. Waymo fait l'inverse et reste stuck en ops géofencée.
Problème numéro trois, le plus fondamental : le LIDAR voit la géométrie, pas la sémantique. Il sait qu'il y a un truc, pas ce que c'est ni ce que ça va faire. Les derniers 9 de fiabilité sont des problèmes de cognition, pas de perception brute. Un capteur de plus résout rien, il ajoute du bruit.
Sébastien Loeb balance une 208 T16 à 180 dans un chemin boueux corse sous la pluie avec zéro LIDAR. Deux yeux, un cerveau. L'évolution a donné des yeux aux prédateurs pendant 500 millions d'années, pas des lasers. Il y a une raison.
Le LIDAR c'est l'équivalent du marxisme appliqué à l'économie. Une solution planifiée, centralisée, qui prétend modéliser explicitement ce qui doit émerger d'un système distribué et adaptatif. Tu remplaces l'intelligence par de la mesure, la compréhension par de la donnée, l'émergence par le contrôle. Ça rassure les ingénieurs qui veulent tout spécifier en amont, exactement comme la planif rassurait les économistes soviétiques. Et ça échoue pour les mêmes raisons : la réalité est trop riche pour être capturée par un capteur, comme elle est trop riche pour être capturée par un plan quinquennal.
La vraie intelligence, celle de Hayek comme celle de Tesla, c'est de faire confiance à un système qui apprend de l'expérience plutôt que de tout pré-encoder. L'élégance d'une solution c'est son rapport signal sur complexité. Le LIDAR explose le dénominateur.
Défendre le LIDAR en 2026 c'est préférer empiler des hacks plutôt que résoudre le vrai problème. C'est de la feignasserie intellectuelle maquillée en rigueur d'ingénieur. Les mêmes gens qui défendaient les systèmes experts en 2012 contre le deep learning. Ils finiront pareil.
Never bet against end-to-end. Never bet against la simplicité. Never bet against Elon.

Français
Good luck ever convincing those grifting evil people in government
Elon Musk@elonmusk
Universal HIGH INCOME via checks issued by the Federal government is the best way to deal with unemployment caused by AI. AI/robotics will produce goods & services far in excess of the increase in the money supply, so there will not be inflation.
English

Really hope Illinois legislature can get a deal done in Arlington Heights…



English


Qwen3.6 35B-A3B dropped yesterday, so I ran it on 4 GPUs to see how it performs:
🟣 RTX 3090 — 49.78 tok/s, TTFT 852ms
🟡 RTX 4090 — 118.93 tok/s, TTFT 686ms
🟢 RTX 5090 — 160.37 tok/s, TTFT 409ms
🔵 DGX Spark — 59.98 tok/s, TTFT 228ms
I went with ollama as the backend because honestly, it's the easiest way for most people to get started. One command, model pulled, done.
I used Q4_K_M (24GB) across all four cards. The reason is the 3090 and 4090 don't support NVFP4 (only the 5090 and DGX Spark could use it). Keeping the same quant everywhere felt like the fairest way to compare.
And yes, you can absolutely squeeze more performance out of every card with vLLM, SGLang, or TensorRT-LLM. But that's not what this test is about. This is just the out-of-the-box experience for folks who own a GPU and want to try the new model tonight.
English
As she gets chauffeured around the city she gazes up at the buildings and thinks...Yes, its time to cut rates.
FinancialJuice@financialjuice
Fed's Daly: Office buildings appear less empty.
English

@stevibe @makulas1913 Just for reference I’m getting 90TPS with 3090
Ollama is just that bad
English


85-100 tok/s on the 3090 with qwen 3.6 already? that's in line with what 3.5 MoE was doing. drop your full flags and context length you tested at, i'm pulling 3.6 on the 5090 24gb and will run the same config for a direct comparison.
if anyone else is running qwen 3.6 on a 3090 or any consumer card drop your tok/s, quant, and flags below. building the community benchmark sheet before i publish my own numbers
Jacob Verdoorn@VerdoornJacob
@sudoingX 3090 getting 85-100 t/s on cpp server with new qwen3.6 35b a3b ud q4 k m 262k context
English

Oh.... also their SABER abliterated twin is done!
Again quants are coming so they will be there when they get there!
huggingface.co/DJLougen/Ornst…
huggingface.co/DJLougen/Ornst…

English


@sudoingX 3090 getting 85-100 t/s on cpp server with new qwen3.6 35b a3b ud q4 k m 262k context
English
let me clear something up for the new followers. the 5090 mobile has 24gb vram, same class as the 3090.
when i benchmark a model on the 5090 and give you the flags and the tok/s, that translates directly to your 3090 at home. the architecture is newer so the 5090 numbers will be slightly faster maybe, but the configs are identical. if it fits on my machine it fits on yours.
and i'm not stopping at one gpu. 3090 nodes are still in the rotation for controlled comparisons, smaller gpus are coming for the 8gb and 12gb crowd, and nvidia sent me a dgx spark that's clearing customs right now. 128gb unified memory on my desk soon.
7 models loaded on the 5090 today, hermes agent work i've been cooking for weeks is almost ready to ship, and open source keeps dropping new models faster than i can pull them. the benchmark pipeline is about to run nonstop. i am so soo back.
English

@FBGreatMoments Someone please explain to me what Jordan Love has ever done to make him untouchable
English

Quarterback tiers by trade value according to NFL on FOX.

English


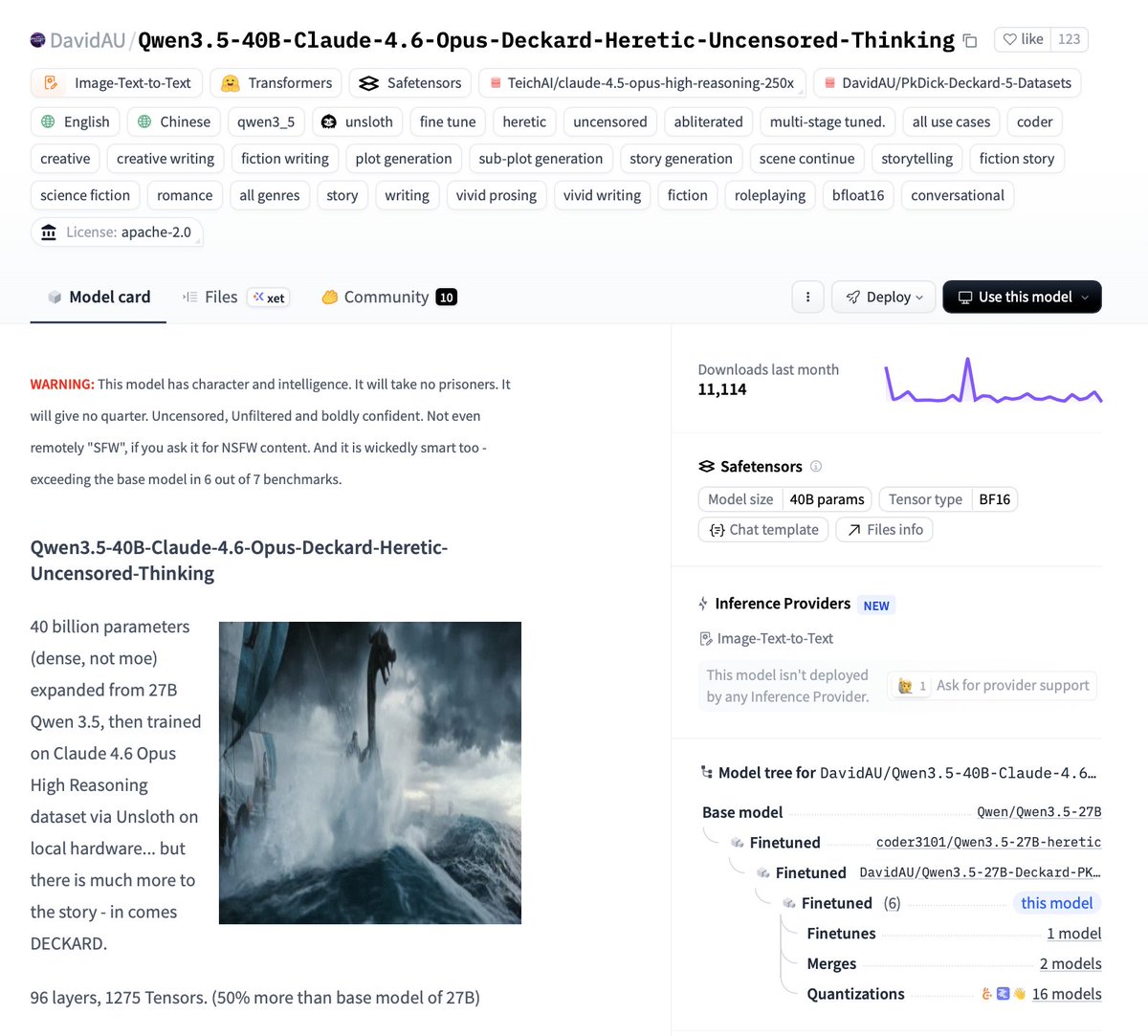
🚨QWEN 3.5 40B DENSE + FULL HERETIC + OPUS 4.6
🤗@huggingface model card:
🧠 40 Billion dense parameters (NOT MoE)
📈 Expanded from 27B → 96 layers + 1,275 tensors
🧪 Multi-stage trained on Claude 4.6 Opus High
⚔️ Fully Heretic-Uncensored first (abliterated)
🔧 Upgraded Jinja template = zero looping...
⚡ Tool calling + 256K context 🧠
Trained via @UnslothAI 🦥on local hardware
And yes it runs on consumer hardware:
💻 Single RTX 4090 friendly (Q4_K_S / IQ3_S )
⚡ Quantized, fast, and ready to go full Deckard mode
Pull this model and share results 👇🏻
English