BySubject@BySubject
How BySubject is democratizing education:
Currently, BySubject has data from Fall 2023-Spring 2024 for classes from ten law schools (i.e., Stanford Law, Yale Law, Duke Law, Harvard Law, Penn Law, UVA Law, Columbia Law, Berkeley Law, Texas Law, UF Law), and there are over 1500 ISBNs in our database from over 700 class names. However, after BySubject raises capital, we will compile all available data from a set of schools, instead of just the law school classes.
If you click a content (e.g., book) image on any page of the website, it will link you to a website that is selling the particular ISBN, and if you click a school indicator on the homepage (i.e., bysubject.com), a popup will then be displayed that comprises the one or more class names from the respective school that required or recommended the respective content. If you click a class name that is displayed in a school indicator popup, the system will execute a search by using the clicked class name as the search query. Whether a user clicks a class name that is displayed in a school indicator popup, or manually types in the search via the search box, the search result will comprise all contents that were required or recommended for a class that matches the query, and all contents that have a matching title will also be identified for the search results. For example, after clicking the class name “Entrepreneurship,” the top ranked content is called Venture Deals: Be Smarter Than Your Lawyer and Venture Capitalist. Even though the word “Entrepreneurship” is not in the content name, this content was identified because it was required or recommended for at least one class name that includes the word “Entrepreneurship.” Identifying contents that are required or recommended for a class name that matches a query (even if a content name does not match the user’s query), is one of the most important and useful BySubject features. By identifying contents this way, the search results comprise objectively relevant contents that go beyond just identifying contents with a matching content title, and the results are ranked in a clear and objective fashion that is guided by authoritative sources. Moreover, class names listed in school indicator popups provide users with additional information.
Also, if a user clicks a content name, BySubjectAI will tell the user about the particular content. For example, if a user clicks “Secrets of Sand Hill Road: Venture Capital and How to Get It,” BySubjectAI will tell the user about that particular book. From there, a user can ask follow up questions, or anything else. If the user clicks “BySubjectAI” while on bysubject.com/ai, the user will be brought back to the homepage.
Scrolling down the homepage, you can see every content in our database, and the school indicators are in an order that is in accordance with their respective U.S. News and World Report ranking. If contents are tied on the homepage before a search is executed, the tie is first broken based on how many unique class names each tied content has, and then ABC order of Content names is used, followed by ISBNs. If contents are tied after a search is executed, the tie is first broken based on if a content name has an exact match to the user’s query, then ties are broken based on if a class name has an exact match to the user’s query, then ties are broken based on which content has a larger total of unique class names, then ties are broken based on ABC order of content names, and then ties are broken by ISBNs.
If the user clicks “BySubject” while on the homepage, the user will then be brought to a different page (i.e., bysubject.com/courseresults) that comprises ranked contents that are grouped for respective ranked class names. The top ranked class name is “Evidence,” and this class name was offered by each of the ten schools. Scrolling down the page, you can see the centered class names in ranked order, and you can also scroll through the ranked contents that are grouped for respective class names. Like on the homepage, a user can click BySubjectAI to navigate to that page (i.e., bysubject.com/ai), and a user can click on a content name to have BySubjectAI tell them about that particular content. However, on this page (i.e., bysubject.com/courseresults), a user can also click one of the centered class names to execute a search using BySubjectAI. For example, the user can click on “Copyright Law” to have BySubjectAI tell the user about Copyright Law, and what a law school class called Copyright Law would cover. From bysubject.com/courseresults, the user can click “BySubject” again to be brought back to the homepage.
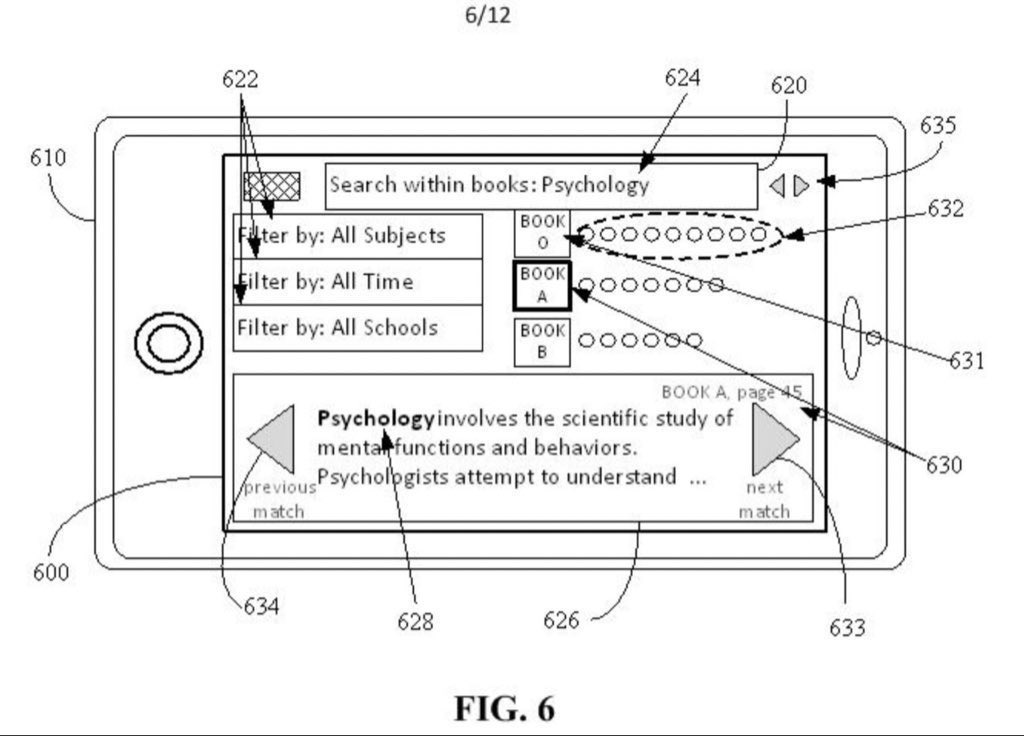
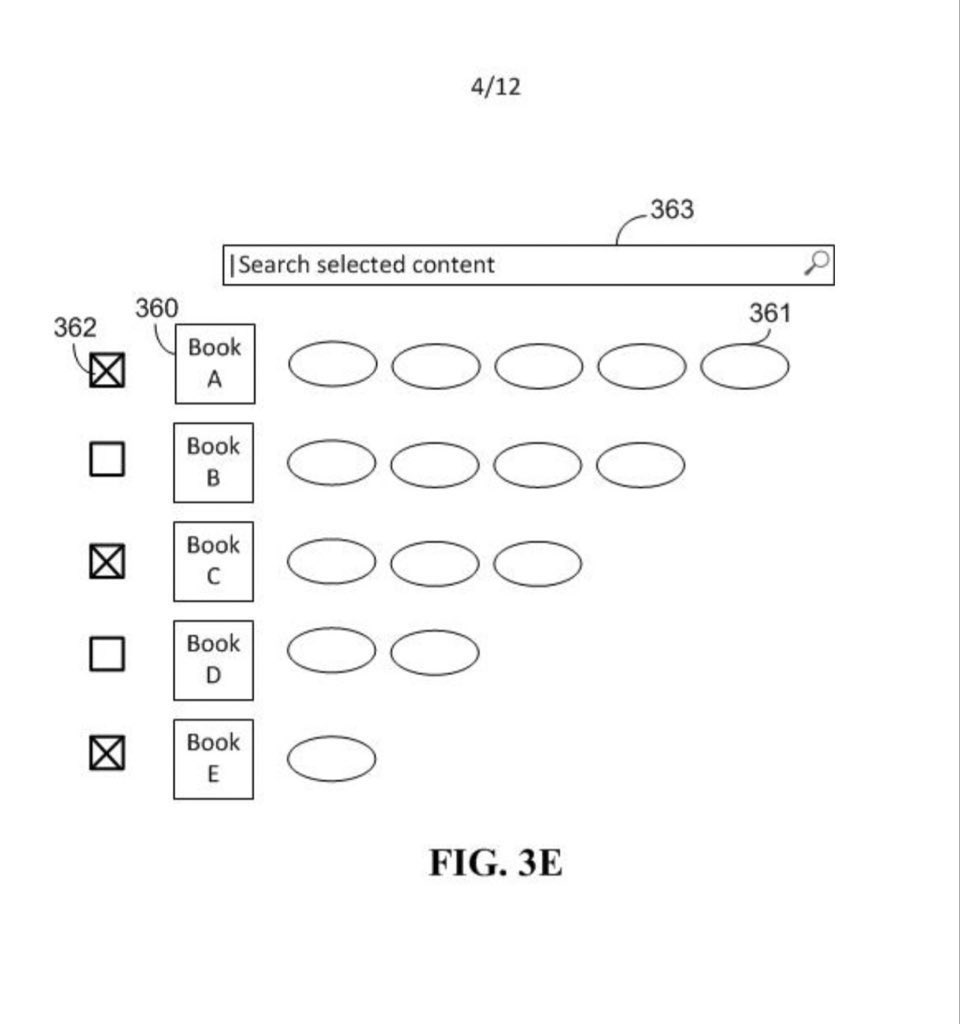
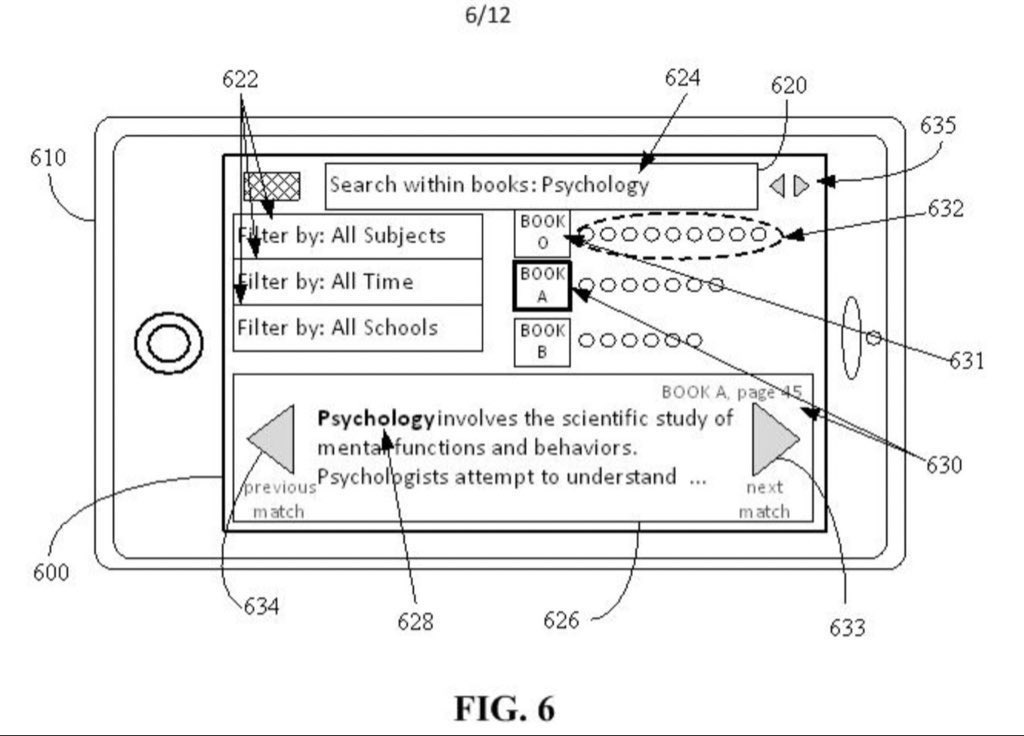
BySubjectAI is currently using GPT-4o with some prompting, but in the future, we want to train/improve/fine-tune/use a foundational model with the contents on BySubject, after we come to an agreement with the respective content providers. However, the primary objective is to come to an agreement with content providers to allow users to search within contents. For example, the user will be able to select one or more contents to search within the one or more contents, and the user will be able to search within one, multiple, or all contents without first selecting one or more contents. We strongly believe that promoting and providing access to these contents is what is best for the world, and what’s best for the content providers. By even just providing limited access through one or more matched within content ranked previews that are displayed in ranked order after a within content search is executed for one or more contents, a user can find out what the best contents say for any subject, and these content providers can receive a revenue or profit share that comes from ads, subscriptions, and/or user payments that occur before and/or after search execution. Moreover, the user will be able to click to a next or previous match, and the user will be able to see matched within content previews for multiple ranked contents at once (e.g., the matched previews can be ranked on top of one another), or the user can focus on one content at a time. Also, the one or more matched previews (or matched pages) that are returned can be (if the user controls for it) limited to matched previews (or matched pages) from pages that are listed from corresponding table of contents matches so that only matched previews (or matched pages) from relevant parts of relevant contents are returned. Moreover, we hope to come to an agreement with the content providers to also allow a user to subscribe, pay, and/or watch ads to unlock more access and/or more time with one or more contents. Of course, if our agreement permits, the user will also be able to access entire pages instead of just matched within content previews, but even just making an agreement for merely the previews will be fantastic because it still would provide great value to users, content providers, and BySubject. By promoting the best contents from the best sources, we provide clear value to users and content providers. In short, BySubject is going to make the best contents in the world searchable (e.g., a user will be able to search within one or more contents, and a user will be able to search for contents without searching within one or more contents), and we are going to do that by partnering with content providers in a way that promotes their contents, and makes them more money than they otherwise would have made. This will encourage humans to create more great content, and this will allow users from around the world to learn from the best contents that were required or recommended by the best schools. Also, BySubject can attempt to partner with as many content providers as possible (and keep increasing the amount over time), and searches (e.g., within content searches, etc) can be limited to (e.g., a user can filter for) whichever contents we have agreements for at the time.
Now that we have gone over some of the key features and future goals, let’s circle back and double click on some more helpful examples. For example, a user can execute a search for a particular ISBN, school name (e.g., Harvard Law, UF Law, etc), content name, course name, or any part thereof. For example, if the user executes a search for “Criminal Law,” the user will immediately notice that the top ranked content has 8 school indicators, and the second highest ranked content has 3 school indicators.Now ask yourself, how do you feel about using a content that 8 of 10 schools used to teach the subject you're interested in? Further still, imagine if you could search within one or more of the top ranked contents (e.g., user selected contents, or a user can search within all (or a filtered set of) contents on BySubject at once, etc) for a subject you’re trying to learn about. Furthermore, as previously noted, the user can click school indicators to see the class names from the respective schools that reference the respective contents, and the user can click the one or more class names that are displayed in a school indicator popup to execute a search with the clicked class name. Also, the user can click on the content names to have BySubjectAI tell them about clicked content names. If a person wants to learn about Criminal Law, then the top ranked content on BySubject is clearly a great place to start. Results from Google, Amazon, AI systems, and other services do not provide all the information and functionality that BySubject does (and will), and they can’t until our patents expire many years from now. There is clearly no better way to provide this information, and AI and/or other services can be layered in or used in conjunction with BySubject (like they already are), so one cannot say that those options are, or will be better than BySubject.
Moreover, the contents on BySubject are comprehensive, well organized, and are highly vetted by the best sources in the world. If a person wants to dive deep into a subject, then reading some of the top ranked contents for one or more respective subjects or class names is going to be a great option for the user. Why trust a random review, website, or AI when you can use what the best authoritative sources in the world use? BySubject makes the user feel confident that they have found high quality (and on point) content for what they are trying to learn, and this in turn will make the user more motivated and successful, while also bringing additional earnings to content providers.
Furthermore, once BySubject has data that is beyond merely law school data, the user can see a searchable ranked list (like the current BySubject homepage that is limited to law school data) of all ranked contents from a set of schools, or of all course names from a set of schools in ranked order with ranked contents grouped for respective ranked class names, instead of just law school classes. Moreover, the user will be able to get to a UI with ranked contents grouped for ranked course names by, for example, searching or filtering for one or more particular subjects, degrees, departments, buildings, a set of classes, schools or colleges that are within schools (e.g., college of medicine, school of law, engineering department, and/or the like, etc), and/or the like, etc. For example, the user will be able to search or filter by law, medical, engineering, math, psychology, etc, schools, departments, degrees (e.g., B.S. in Physics, Juris Doctor degree, etc), certificates, and/or the like, and this will provide the user with an overview of one or more particular subjects, degrees, certificates, departments, schools or colleges within schools, and/or the like. For example, by providing the user with the ranked course names, and respective ranked contents that are grouped for the corresponding ranked course names (e.g., see bysubject.com/courseresults), the user is exposed to subjects, courses, and contents that they may have never heard of, and didn’t know they should learn about. It does all of this in an objective way that is easy to understand and instantly verifiable. The user knows that these contents are vetted by some of the best schools, and the user knows that these are some of the best contents for what they are trying to learn. Furthermore, if a user searches or filters by a particular degree (e.g., by B.S. in Chemistry), BySubject can identify course names that are required for the degree (e.g., using data from one, any multiple, or all of the schools that are filtered for), and can also identify courses that are required to be picked from (e.g., a degree can require students to take a certain amount of a group of classes (e.g., a school could tell students that to get degree X they need to take and pass 3 of these 5 courses)). Additionally, a user (or default) can filter out (or in) one or more classes that may be required, or required to be picked from, if they are non-core (and/or the like, etc) classes. For example, if a user searches or filters by “B.S. in Psychology”, a user can filter out math and/or english classes so they (and their respective contents) are not listed, or the user can just scroll past them. Lastly, a user can also control for all the contents to be listed in ranked order against one another, instead of (or in addition to (e.g., the top ranked grouping of ranked contents could be a list of all contents from all the class names)) ranked contents being grouped for respective ranked class names.
For many of the most important use cases, the BySubject results are clearly superior to Google, Amazon, or AI results, but BySubject can be used in conjunction with all of those services (and more) as well, and as you have seen, AI or other services can be layered into BySubject (e.g., by having an AI tell the user about a content or class name after a user clicks a content or class name, etc).
In regard to the recent and future advances in AI (which are awesome and already integrated into BySubject), for many of the most important use cases, one or more results from one or more Al services (even assuming the one or more results are not very unreliable or incomplete like they very frequently are now) will never beat having (or ALSO HAVING) ranked results comprise multiple ranked matched previews from multiple carefully crafted comprehensive textbooks (and/or other content types) that are simultaneously displayed (e.g., see some of the images I have previously posted), and that the user has complete (or even partial) access to, and saying the Al will just generate whatever it wants, or reproduce what others have already created, ignores reality, and the IP (i.e., copyright and patent) protections that owners have. If the Al goes in a random or creative direction (which is great for certain use cases) that may be covered by fair use, then it is not necessarily giving you accurate/vetted/complete/concise information. Even if an AGI system paraphrases and generates a new or different textbook (or relevant part(s) thereof) for you (or another Al) on any subject, could you trust that the Al didn't make a mistake, leave something out, or waste your time in some way? How could you know for sure? Will it very reliably have all the words, ideas, images, and information without infringing on a prior work? Does certain code or weights that equate to or enable an exact or substantially similar copy of a substantial portion of a work to be generated inherently mean that a type of infringement will, is, or has occurred (e.g., even pre generation)? Did a type of infringement occur when the training occurred, or anytime thereafter? Moreover, if there's a short excerpt or summary of a work on a website and the model used that to train on, the model still doesn't have the benefit of the entire work in its vetted/complete/concise form, and even if it did, that wouldn't change the foregoing, or the following. If a model combines excerpts or other works with other information found on the web (or otherwise), will it reliably and concisely give you the complete, organized, and accurate picture like a carefully crafted book, article, or video would? Wouldn't you rather read/use/search the best heavily vetted complete textbooks (and/or other contents) that are well organized, made by real experts, and referenced (e.g., by being assigned or required for a class) by the best authoritative sources (e.g., schools), instead of using a random, unreliable, and incomplete Al output (or even a perfect AI output) that attempts to tell you the same or similar, or merely part(s) thereof? It would clearly be better to use BySubject with the transparency, information, and confidence that the respective source indicators (and popups therefrom) and search functionality provide, or the Al service(s) in conjunction with BySubject, instead of merely using one or more potentially unreliable or incomplete Al outputs.
Lastly, although I have talked about educational contents today, please note that some of our patents also cover medical contents, commercial contents, and other content types. BySubject aims to be the backbone (or at least one of the cornerstones) for the democratization of education, healthcare, commerce, and more.
If you would like to join, partner with, or invest in BySubject, then please email me at steven@bysubject.com.
#EdTech #LawSchool #VentureCapital #AI #Education #Books #Reading #Learning