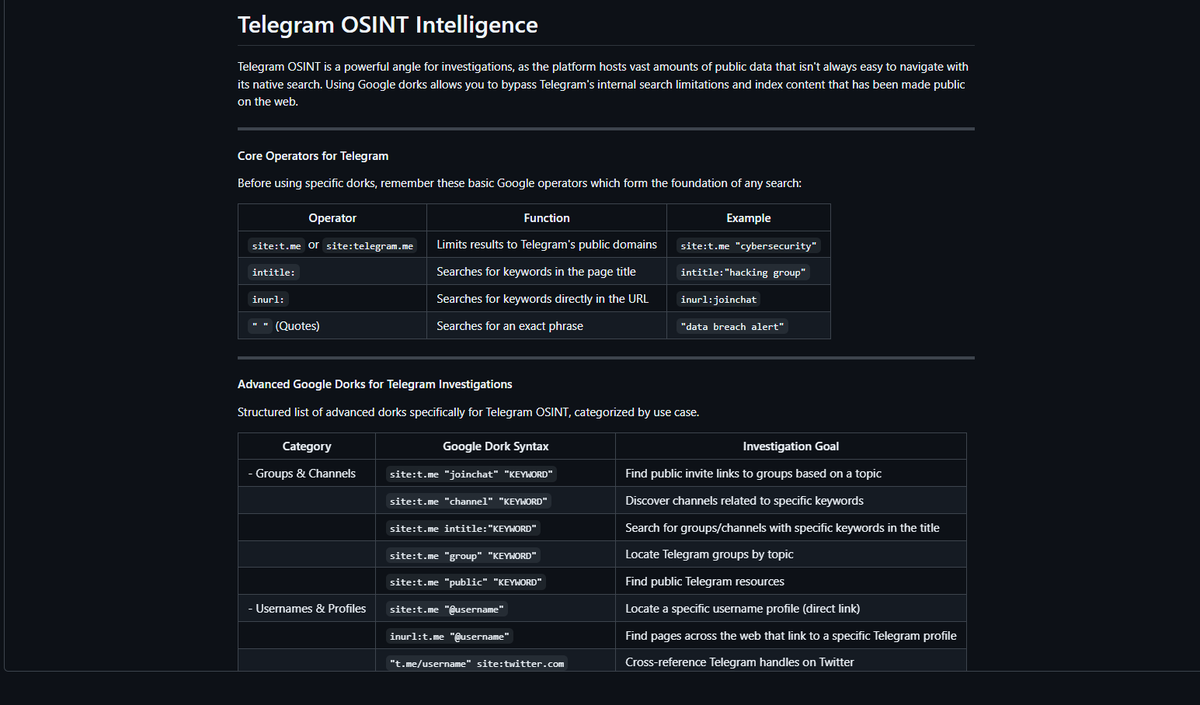
Graeme@gkisokay
The Local LLM cheat sheet for your 16GB RAM device
I pulled together a lineup of small models that can run comfortably on a Mac Mini or personal laptop while still leaving room for context without melting your machine.
Models for Daily Use
Qwen3.5 9B / GGUF / Q4_K_M
Daily driver. General chat, drafting, research, translation. If you're keeping only one, keep this.
DeepSeek-R1 Distill Qwen 7B / GGUF / Q4_K_M
Reasoning engine. Math, logic, step-by-step problems. Slower, but worth it when you need actual thinking.
Models for Specialty Work
Qwen2.5 Coder 7B / GGUF / Q4_K_M
Code specialist. Completions, refactors, debugging, repo Q&A. Better than a generalist when the task is code.
Llama 3.1 8B / GGUF / Q4_K_M
Long context worker. RAG, doc chat, codebase Q and A. The output isn't top tier, but the context is strong for its size.
Phi-4 Mini Reasoning / GGUF / Q4_K_M
Compact thinker. Logic, structured answers, math, and short coding bursts. Smaller context is the catch.
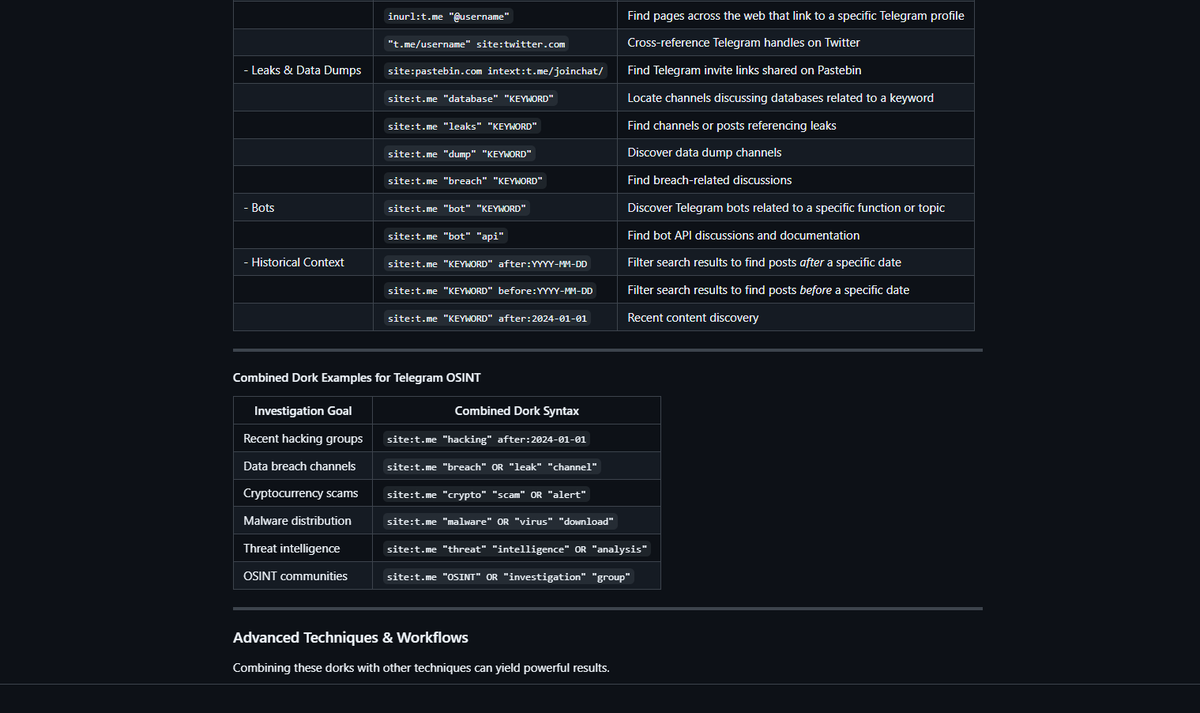
Models for Efficiency
Gemma 4 E4B / GGUF / Q4_K_M
Light all-rounder. Writing, chat, light agents, structured output.
Phi-3.5 Mini / GGUF / Q5_K_M
Pocket sidekick. Summaries, extraction, background doc chat. Easy to pair with a bigger model.
Qwen3.5 2B / GGUF / Q4_K_M
Useful for summaries, tagging, rewrites, and lightweight sidekick work.
Micro Models
Qwen3.5 0.8B / GGUF / Q5_K_M
Classification, keyword routing, binary decisions, triage.
Gemma 4 E2B-it / GGUF / Q4_K_M
Lightweight chat, quick Q and A, summaries, tiny agents.
My personal choice for a single model is Qwen3.5 9B
For two models use Qwen3.5 9B + Qwen2.5 Coder 7B for code, or Qwen3.5 9B + Phi-3.5 Mini for support tasks.
Let me know in the comments your experience with these models, or any I have left out.