
Paco
347 posts



English
@ryenarussillo - catching up on the pod during my commute this am…he’s got a ton of goats…appreciate the laugh
English
@BrianRoemmele This paper came out a year ago. Why are hyperscaler capex investments still so high? Oracle still inking 5 year deals…
English

BOOM! MAJOR AI SPEEDUP!
Hot Rod AI 100 times faster inference 100,000 times less power!
—
Reviving Analog Circuits: A Leap Toward Ultra-Efficient AI with In-Memory Attention
I got my start in analog electronics when I was a kid and always thought analog computers would make a comeback. Analog computing of the 1960s neural networks used voltage-based circuits rather than binary clocks.
Analog is Faster Than Digital
Large language models at their core lies the transformer architecture, where self-attention mechanisms sift through vast sequences of data to predict the next word or token.
On conventional GPUs, shuttling data between memory caches and processing units devours time and energy, bottlenecking the entire system. They require a clock cycle to precisely move bits in and out of memory and registers and this is >90% of the time and energy overhead.
But now a groundbreaking study proposes a custom in-memory computing setup that could slash these inefficiencies, potentially reshaping how we deploy generative AI.
The innovation centers on "gain cells"—emerging charge-based analog memories that double as both storage and computation engines.
Unlike digital GPUs, which laboriously load token projections from cache into SRAM for each generation step, this architecture keeps data where the math happens: right ON THE CHIP! With a clock speed near the THE SPEED OF LIGHT because it is never on/off like in digital binary.
By leveraging parallel analog dot-product operations, the design computes self-attention natively, sidestepping the data movement that plagues GPU hardware.
To bridge the gap between ideal digital models and the noisy realities of analog circuits, the researchers devised a clever initialization algorithm.
This method adapts pre-trained LLMs, such as GPT-2, without the need for full retraining, ensuring seamless performance parity despite non-idealities like voltage drifts or precision limits.
The results are nothing short of staggering!
Simulations show the system slashing attention latency to 100 times faster inference for token generation—while curbing energy use by a jaw-dropping five orders of magnitude, or 100,000 times less power-hungry than GPU baselines. For context, this could mean running a full LLM on a device no larger than a a card deck, without any thermal throttling or grid-straining demands of today's data centers.
The approach targets the attention block specifically, the transformer’s energy hog, but slso broader integration with other in-memory techniques to turbocharge the entire model pipeline.
Analog tech isn't pie-in-the-sky quantum wizardry; it's grounded in ancient mature electronics theory, with gain cells already prototyped in labs.
The only engineering issue, and it is simple: tolerances for noise, scaling arrays of cells, and fabricating at microchip densities. Existing CMOS processes tweaks for analog fidelity. From there, Full ecosystem integration, including software stacks for model adaptation, could happen in a year, disrupting GPU dominance sooner than skeptics predict.
Risks are low but hybrid digital-analog interfaces could introduce unforeseen bugs. However this can be rapidly iterated and addressed.
This isn't just hardware tinkering; it's a philosophical pivot back to AI's analog origins, where computation flows continuously rather than ticking in discrete cycles.
This in-memory attention could democratize AI power, making low power, lightning-fast AI not a luxury, but an inevitability to even the smallest devices.
Most have no idea how big this is: It is the biggest shift in AI since the invention of LLMs.
The world will struggle to find true experienced analog engineers, most are gone.
In my garage I will have a test Analog CMOS Gain Cells using off the self parts in the next few days, if Radio Shack was still around I would have have done today. I suspect I can scale to a proto AI model in a few weeks.
PAPER:
arxiv.org/abs/2409.19315

English

@BillSimmons - first the prem pod and now Russillo? That’s my commuting routine. This hurts
English

@Ceruti @AnthonyDabbundo @PaulCarr really crushed to hear the news about the pod - your show makes my week every week
English

You have to have undeniable confidence to go by Kevin and Kevin alone.
Fabrizio Romano@FabrizioRomano
🚨⚪️⚫️ EXCL: Shakhtar Donetsk turn down €30m plus add-ons proposal from Fulham for Brazilian winger Kevin. Total package close to €40m add-ons included has been rejected in recent hours. Shakhtar want more and are also aware of interest from several clubs, Napoli and more.
English
@AnthonyDabbundo Hopefully not podding while watching will help this time around
English

i bet spain -131 🇪🇸a couple days ago — fully expecting england to ruin me once again on some late match absurdity
Paco@ProctorMan
@AnthonyDabbundo what’s the play for the women’s final?
English
Sinner/Alcaraz first ever grand slam final meeting on Sunday at 9am is appointment television
These two guys are remarkably clear of the rest of the world right now
English

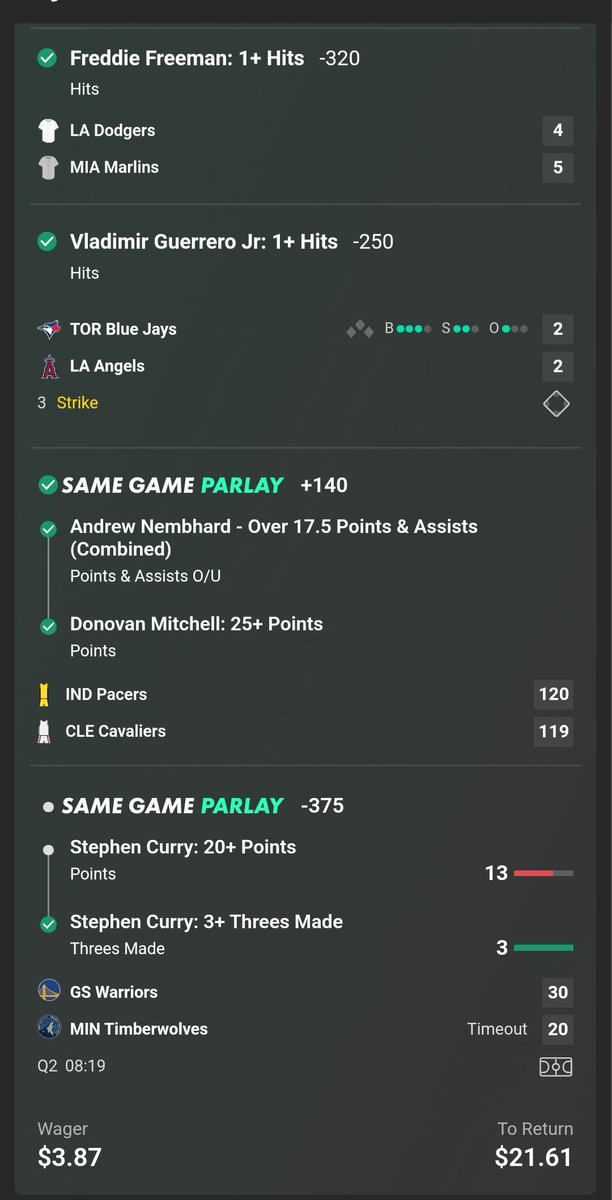
Curry just left the game.
ARE YOU FU*KING KIDDING ME???
English
@JoeFortenbaugh - You're gonna be a genius anyway! Nothing new, but you’re the man
English
@fantasyEK - your years long stat about NBA home teams with extra rest saved me tonight - much appreciated
English