固定されたツイート

We’re excited to share our work "A Model Can Help Itself: Reward-Free Self-Training for LLM Reasoning".
An earlier version of this work has been on arXiv for a few months. We added more experiments and revised it to this new title.
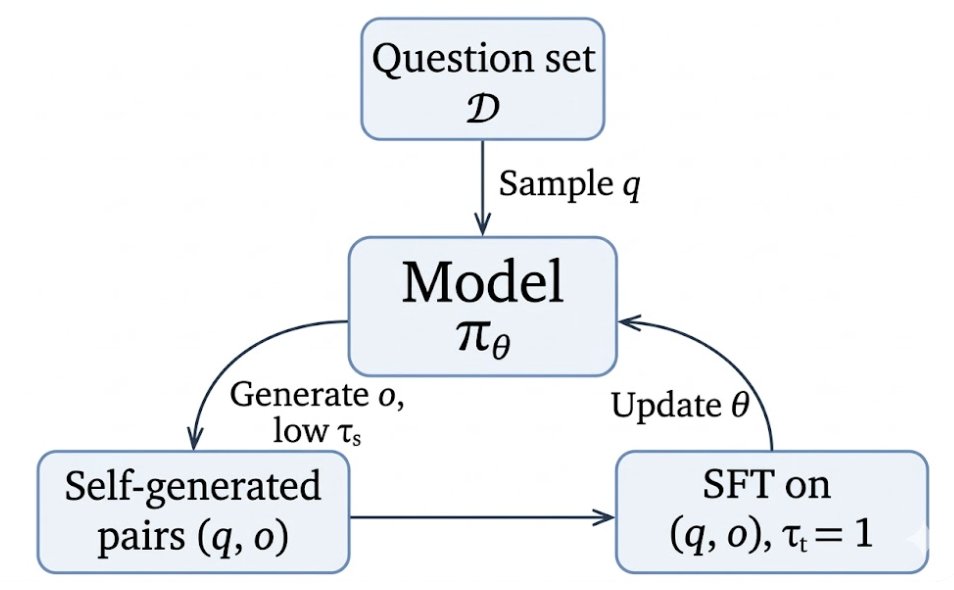
The recipe is simple: the model samples its own reponses at low temperature, learns from them with ordinary SFT training, and repeats.
No reward.
No verifier.
No fancy objective beyond standard SFT.
On Qwen2.5-Math-7B, mean Pass@1 over 6 math benchmarks improves 22.7 → 39.5.
Note that mean Pass@32 also improves 61.0 → 67.9, suggesting that this simple reward-free procedure unlocks more of the model’s existing reasoning potential.
See the updated paper directly at:
github.com/ElementQi/SePT…
The arXiv link is:
arxiv.org/abs/2510.18814
The updated version will appear on arXiv shortly.
@Phanron_xli

English