Sabitlenmiş Tweet

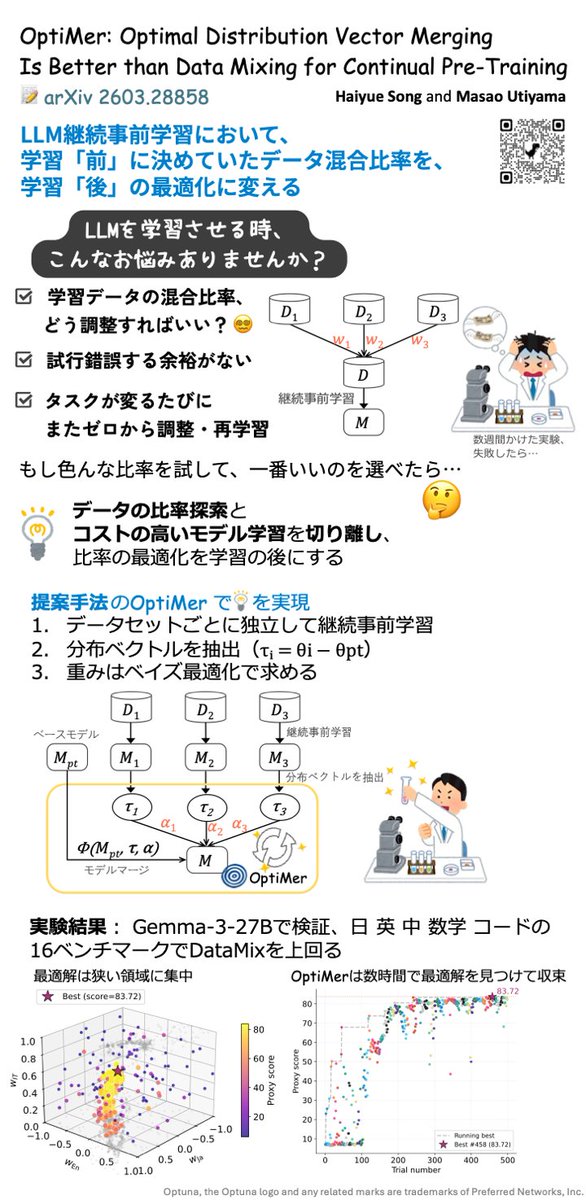
🤯 Struggling with dataset mixing ratios in LLM continual training?
🧩 We propose OptiMer: train one model per dataset, then merge them optimally. No more costly ratio tuning!
📄OptiMer: Optimal Distribution Vector Merging Is Better than Data Mixing for Continual Pre-Training
🔗arxiv.org/abs/2603.28858
My last work at @NICT_Publicity also related to our collaboration with @AISingapore
🧵 1/9
#NLProc #NLP #LLM #ModelMerging #大規模言語モデル #AI
English