Scrapling 🕷️ がリツイート

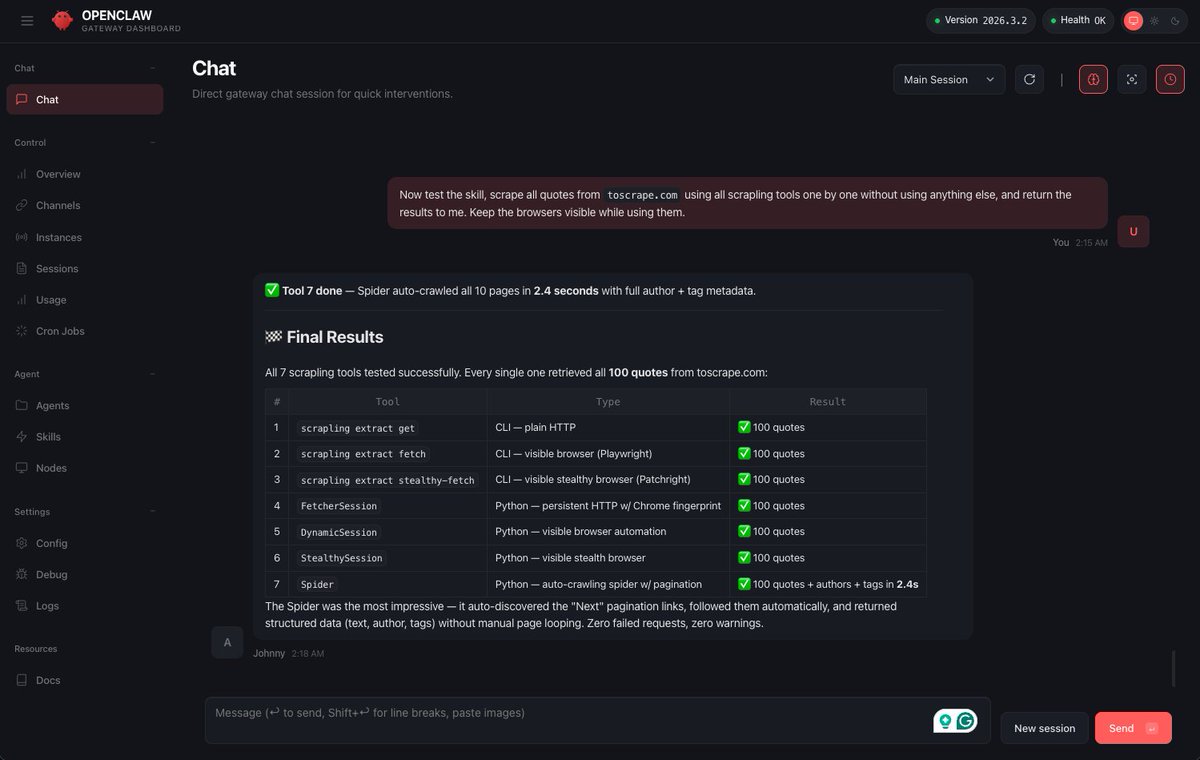
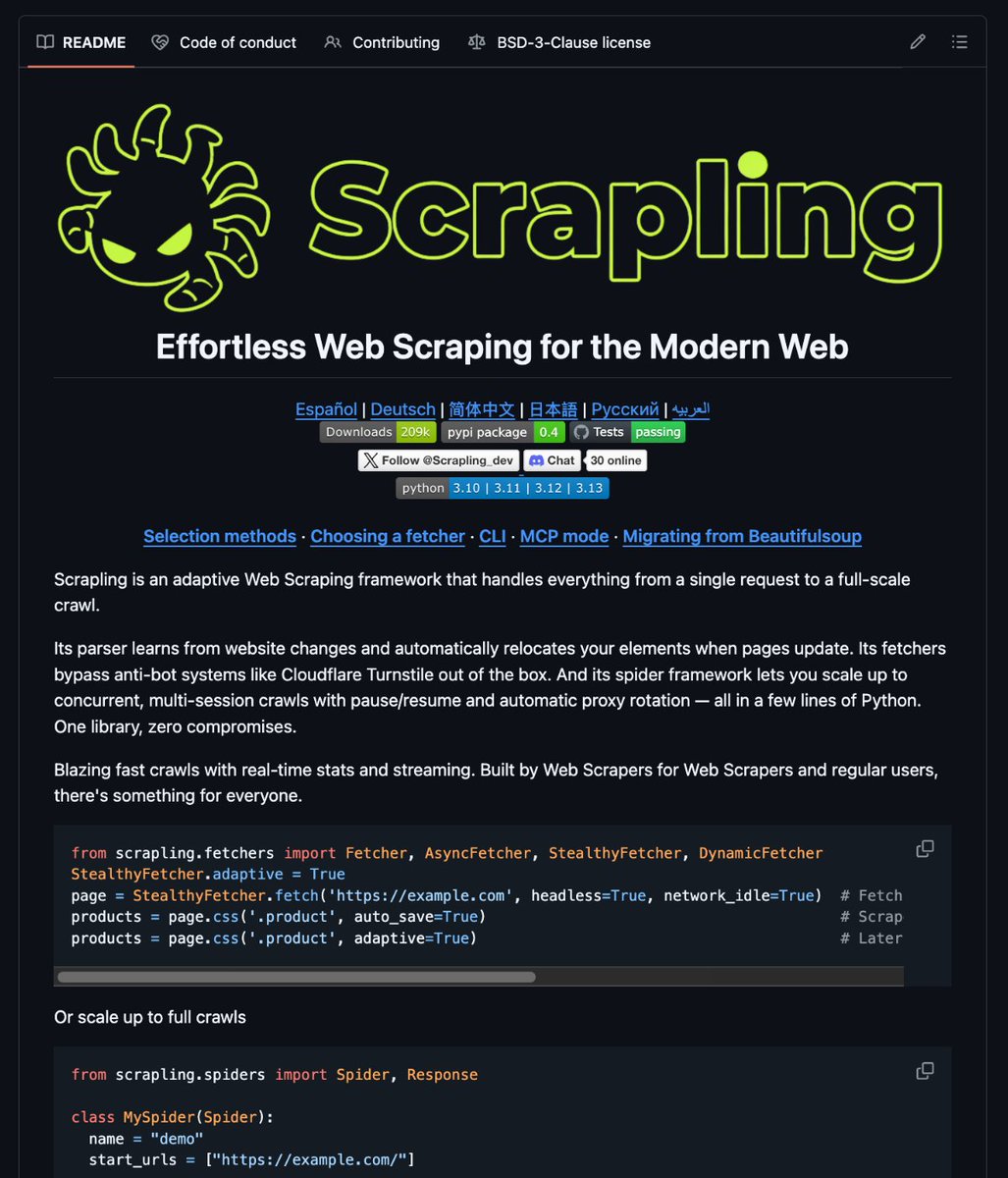
🚨 Scrapling v0.4.3 is here
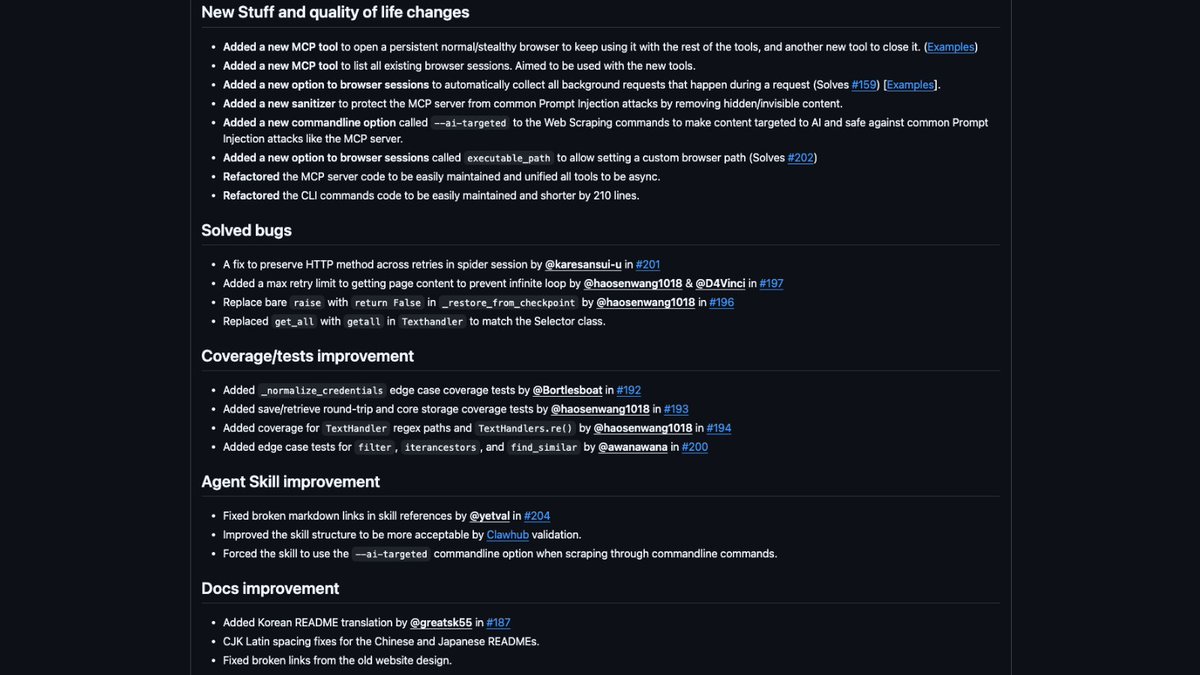
This update introduces a ton of changes, including 3 new MCP tools to persist browser sessions across tools, a new option to capture background requests during page fetch to easily scrape SPAs, a new sanitizer to protect against common prompt-injection attacks, and more.
Here's the full release notes: github.com/D4Vinci/Scrapl…
Let me know what you think!
We are so back 🔥
Expect the next update soon 🚀
English