CHRISPI@cripto_lion
The HIDDEN file that decides HOW WELL your @gensynai RL Swarm node performs.
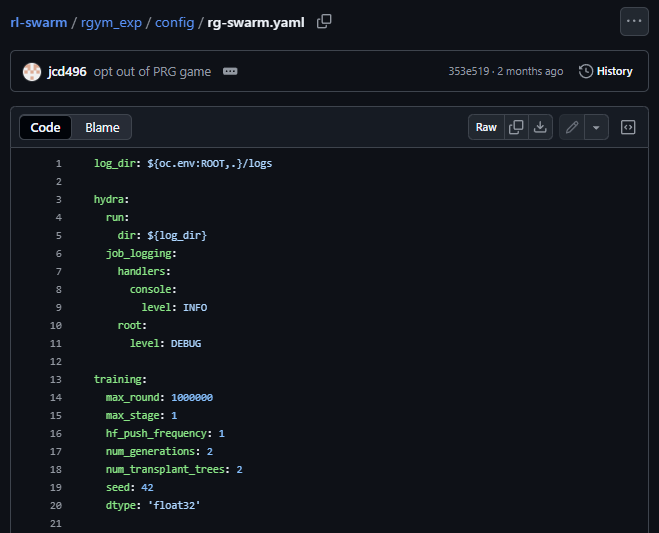
Inside every RL-Swarm node there’s a file called rg-swarm.yaml, it defines how your model learns, communicates, and reports to the @gensynai Testnet.
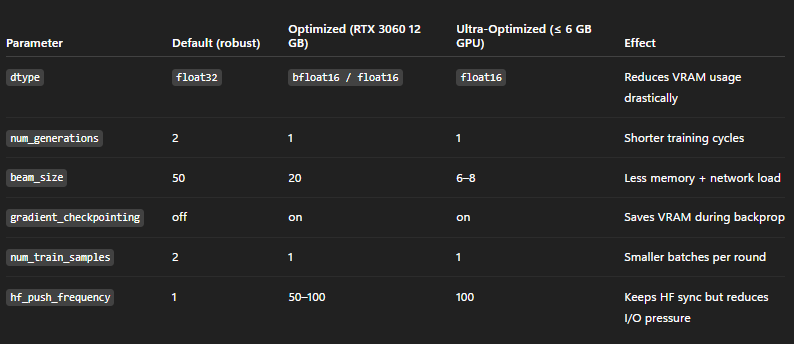
By default, this YAML is built for stability and performance, optimized for GPUs with 16–24 GB VRAM (like the 3090 or 4090).
But once you understand its structure, you realize it can be tuned to run even on a RTX 3060 (12 GB) or less...
That single insight changes how we think about distributed reinforcement learning.
HOW OPTIMIZATION WORKS
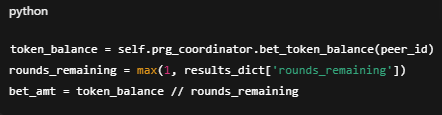
Inside rl_swarm/rgym_exp/config, the rg-swarm.yaml file controls your node’s workload: precision, number of generations, beam size, and more.
These are the levers that define how heavy or lightweight your node behaves.
Tweak these parameters and you can balance performance vs. efficiency depending on your GPU:
WHY IT MATTERS
The default YAML gives great rewards and stability on powerful cards, it’s built to deliver high-quality training and consistent scores across the swarm.
Optimizing it doesn’t “break” the system; it simply makes it accessible.
You’ll still receive participation points and rewards, but since your GPU delivers smaller batches and shorter sequences, the total yield per round will be slightly lower.
This approach is about inclusion, helping more people run nodes locally or cut GPU rental costs, without fear of OOM errors or instability.
ABOUT MODELS
If you’re optimizing for lower VRAM, using the lightest model available in @gensynai RL Swarm is the smartest move, models like Qwen2.5-0.5B or Qwen3-0.6B fit perfectly on 8–12 GB GPUs.
If you have more VRAM (16–24 GB), switch to the 1.5B–1.7B models to take full advantage of your hardware and earn higher-quality rewards per round.
FINAL NOTE
These changes should always be tested, tweak and benchmark until you find the configuration that works best for your hardware.
And before launching your node, replace the original file in: rl_swarm/rgym_exp/config/rg-swarm.yaml,with your optimized version.
Understanding rg-swarm.yaml means realizing that reinforcement learning at scale isn’t just for datacenters, it can start right at home, with a single RTX 3060.
Credit to @0xMoei his optimized YAML was the base for these tests.