Dev Patel がリツイート
Dev Patel
244 posts


Dev Patel
@devpatelio
making magic machines @ucberkeley | @novaskyai • @amd • @healthenginecal
SF, CA 参加日 Haziran 2022
1.1K フォロー中554 フォロワー

Dev Patel がリツイート

The RL training infra for Composer 2 was built with Ray. Very impressive work.

Cursor@cursor_ai
We're releasing a technical report describing how Composer 2 was trained.
English




Had a fun time building SimSafe for the @nvidiaomniverse Cosmos Cookoff!!
AV companies generate millions of synthetic training clips, but bad data with broken physics and unrealistic footage, degrades model performance.
SimSafe uses Cosmos Reason 2 to automatically detect physically implausible synthetic AV training data from dashcam footage (by looking at shadow consistency, vehicle dynamics, road texture realism).
English
Dev Patel がリツイート

Luckin Coffee (Chinese Starbucks) acquired Blue Bottle retail operations for $400M from Nestle, who had bought a majority at a ~$700M valuation back in 2017. Blue Bottle had raised from True, Index and GV.
Nestle will keep the FMCG brand.
Luckin was delisted from the Nasdaq in 2020 when it came out that they had fabricated $310M of sales, and paid a $180M fine. They seem to have turned it around and might get relisted after 5 years in the penalty box. It’s trading at ~$10B on OTC markets
en.sedaily.com/international/…
English
Dev Patel がリツイート

We’ve been consistently surprised lately by how capable frontier models are at handling complex kernel implementation and system optimization.
Check out this work as a step toward automating AI infrastructure building!
Shiyi Cao@shiyi_c98
Introducing our new work K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model — a new paradigm for automated GPU kernel generation, achieving SoTA results. 🔍 Big insight: Traditional methods treat LLMs as stochastic code generators inside heuristic loops — but this misses a key point: LLMs are powerful planners with rich domain priors. 🧠 Core idea: K-Search uses the LLM itself as a co-evolving world model — one that plans + updates beliefs + guides search decisions based on experience. 📌 This decouples high-level strategy (intent) from low-level code implementation, allowing the optimizer to pursue multi-step transformations even when intermediate implementations don’t immediately improve performance. 📈 Key results: 🔥 Our discovered kernels are ~2.10× average speedup vs state-of-the-art evolutionary search across 4 FlashInfer kernels on H100/B200. 🔥 Up to 14.3× gain on complex Mixture-of-Experts (MoE) kernels. 🔥 State-of-the-art performance on GPUMode TriMul (H100) task — beating both automated and human solutions. 🙏 Acknowledgements This work is developed in @BerkeleySky, w/ the amazing @ziming_mao, @profjoeyg, and @istoica05. We thank @DachengLi177, @MayankMish98, @randwalk0, @pgasawa, @fangz_zzu, and @tian_xia_ for helpful discussion and feedback. We also thank the generous compute support from @databricks, @awscloud, @anyscalecompute, @nvidia, @Google, @LambdaAPI, and @MayfieldFund. 👨💻 GitHub: github.com/caoshiyi/K-Sea… 📄 arXiv: arxiv.org/pdf/2602.19128…
English
Dev Patel がリツイート



Dev Patel がリツイート

@NovaSkyAI Personally, SkyRL is the best code repo for agentic RL. We have tested lots of other RL codebase and their examples can not even run correctly. Respect!
English
Dev Patel がリツイート
🔥Modifying 2 lines of code and get your agentic serving/rollout up to 3.9x faster losslessly!
⚡️Say hello to ThunderAgent, a fast, simple, and program-aware agentic Inference System.
🥇 We propose a program abstraction to schedule all GPU and CPU resources, the first principled approach for distributed agentic inference and rollout.
🌐 Blog: thunderagent.ai
💻 Code: github.com/ThunderAgent-o…
📜 Paper: arxiv.org/pdf/2602.13692
#AI #ThunderAgent #LLMAgent #Mlsys
1/n
English
Dev Patel がリツイート
Excited to see SkyRL being used by systems research to study how agentic RL workload can be optimized!! github.com/ThunderAgent-o…
Hao Kang@GT_HaoKang
🔥Modifying 2 lines of code and get your agentic serving/rollout up to 3.9x faster losslessly! ⚡️Say hello to ThunderAgent, a fast, simple, and program-aware agentic Inference System. 🥇 We propose a program abstraction to schedule all GPU and CPU resources, the first principled approach for distributed agentic inference and rollout. 🌐 Blog: thunderagent.ai 💻 Code: github.com/ThunderAgent-o… 📜 Paper: arxiv.org/pdf/2602.13692 #AI #ThunderAgent #LLMAgent #Mlsys 1/n
English


SkyRL 🤝 Harbor is the best way to train terminal agents.
Charlie Ruan@charlie_ruan
Releasing the official SkyRL + Harbor integration: a standardized way to train terminal-use agents with RL. From the creators of Terminal-Bench, Harbor is a widely adopted framework for evaluating terminal-use agents on any task expressible as a Dockerfile + instruction + test script. This integration extends it: the same tasks you evaluate on, you can now RL-train on. Blog: novasky-ai.notion.site/skyrl-harbor 🧵
English
Dev Patel がリツイート

Source: Benchmark's 2020 fund is now worth 10x+ and 2024 fund is 3x what investors put in, based on cash distributions and the paper value of its investments (@nmasc_ / Bloomberg)
bloomberg.com/news/articles/…
#a260217p46" target="_blank" rel="nofollow noopener">techmeme.com/260217/p46#a26…
📥 Send tips! techmeme.com/contact
English
Dev Patel がリツイート

🔥Excited to see SkyRL bringing Tinker to local GPUs.
Standardizing training APIs lowers the barrier for research and infrastructure innovation.
vLLM is proud to power the inference layer behind high-throughput RL training. 🚀
Tyler Griggs@tyler_griggs_
SkyRL now implements the Tinker API. Now, training scripts written for Tinker can run on your own GPUs with zero code changes using SkyRL's FSDP2, Megatron, and vLLM backends. Blog: novasky-ai.notion.site/skyrl-tinker 🧵
English

recently been interested in Meta's JEPA, an architecture for predictive models to be able to extract/understand higher level details from any modality of data.
walkthrough on my website: fazalmittu.com/reports/ijepa
going to be doing more of these going forward!
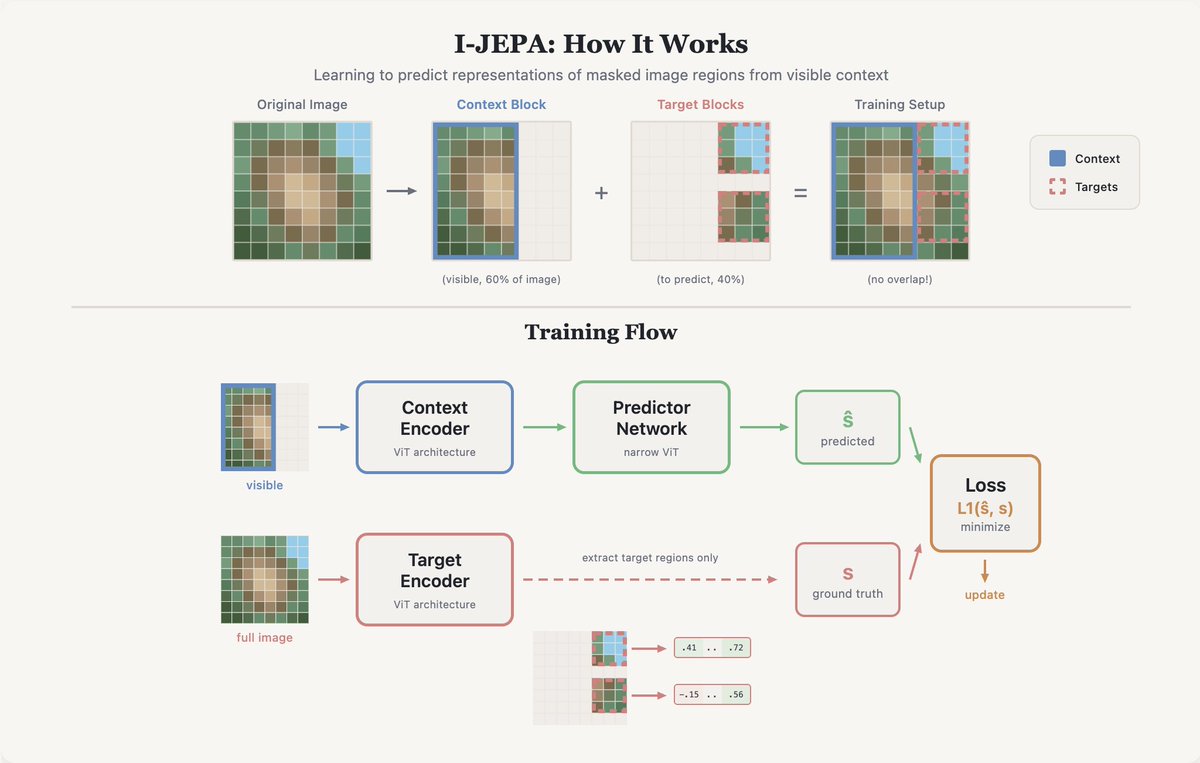
English
Dev Patel がリツイート

super excited about our release of the tinker API in skyrl!
come try it out for your next training run or if you're interested in building an open source Tinker engine!
Tyler Griggs@tyler_griggs_
SkyRL now implements the Tinker API. Now, training scripts written for Tinker can run on your own GPUs with zero code changes using SkyRL's FSDP2, Megatron, and vLLM backends. Blog: novasky-ai.notion.site/skyrl-tinker 🧵
English
Dev Patel がリツイート
We are excited to announce that SkyRL now implements the Tinker API. Run Tinker training scripts on your own hardware with zero code changes.
Try it out today: novasky-ai.notion.site/skyrl-tinker
Tyler Griggs@tyler_griggs_
SkyRL now implements the Tinker API. Now, training scripts written for Tinker can run on your own GPUs with zero code changes using SkyRL's FSDP2, Megatron, and vLLM backends. Blog: novasky-ai.notion.site/skyrl-tinker 🧵
English
We’re super excited to have SkyRL be fully implementing Tinker!
Tyler Griggs@tyler_griggs_
SkyRL now implements the Tinker API. Now, training scripts written for Tinker can run on your own GPUs with zero code changes using SkyRL's FSDP2, Megatron, and vLLM backends. Blog: novasky-ai.notion.site/skyrl-tinker 🧵
English