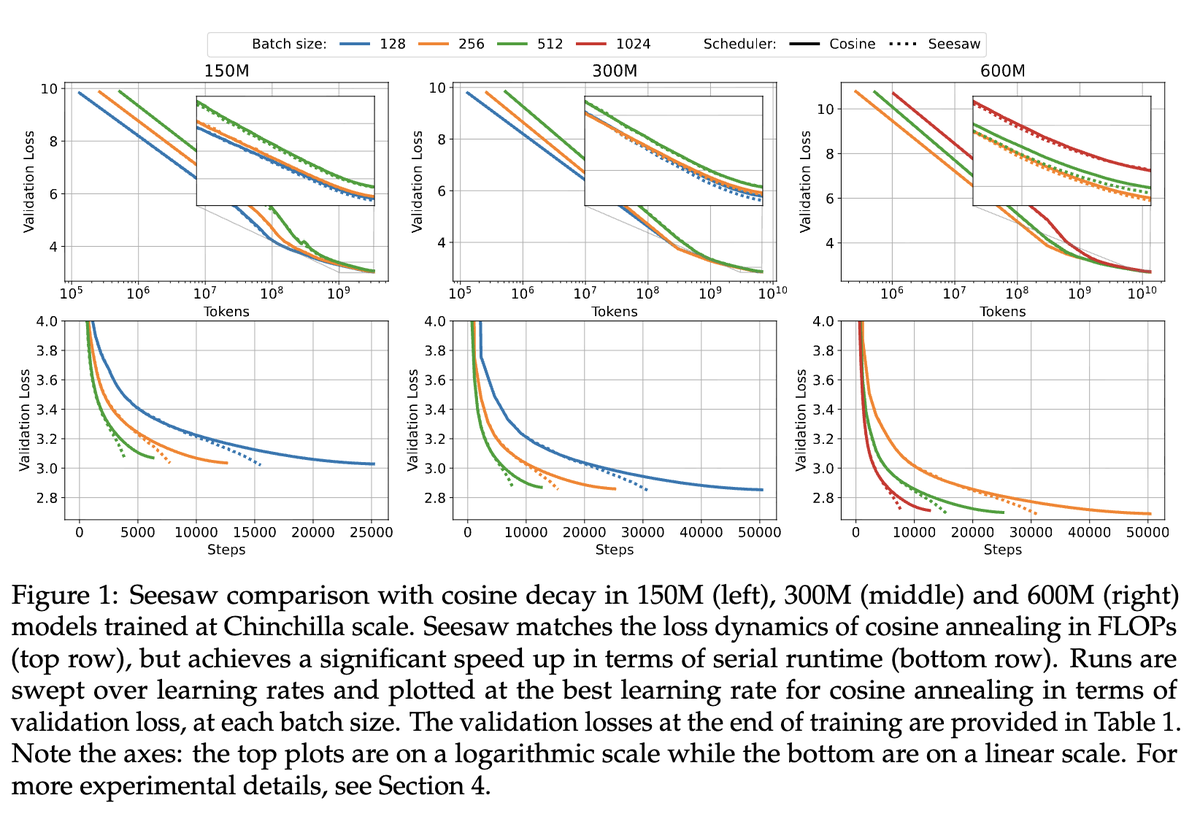
固定されたツイート

sharing a new paper w Peter Bartlett, @jasondeanlee, @ShamKakade6, Bin Yu
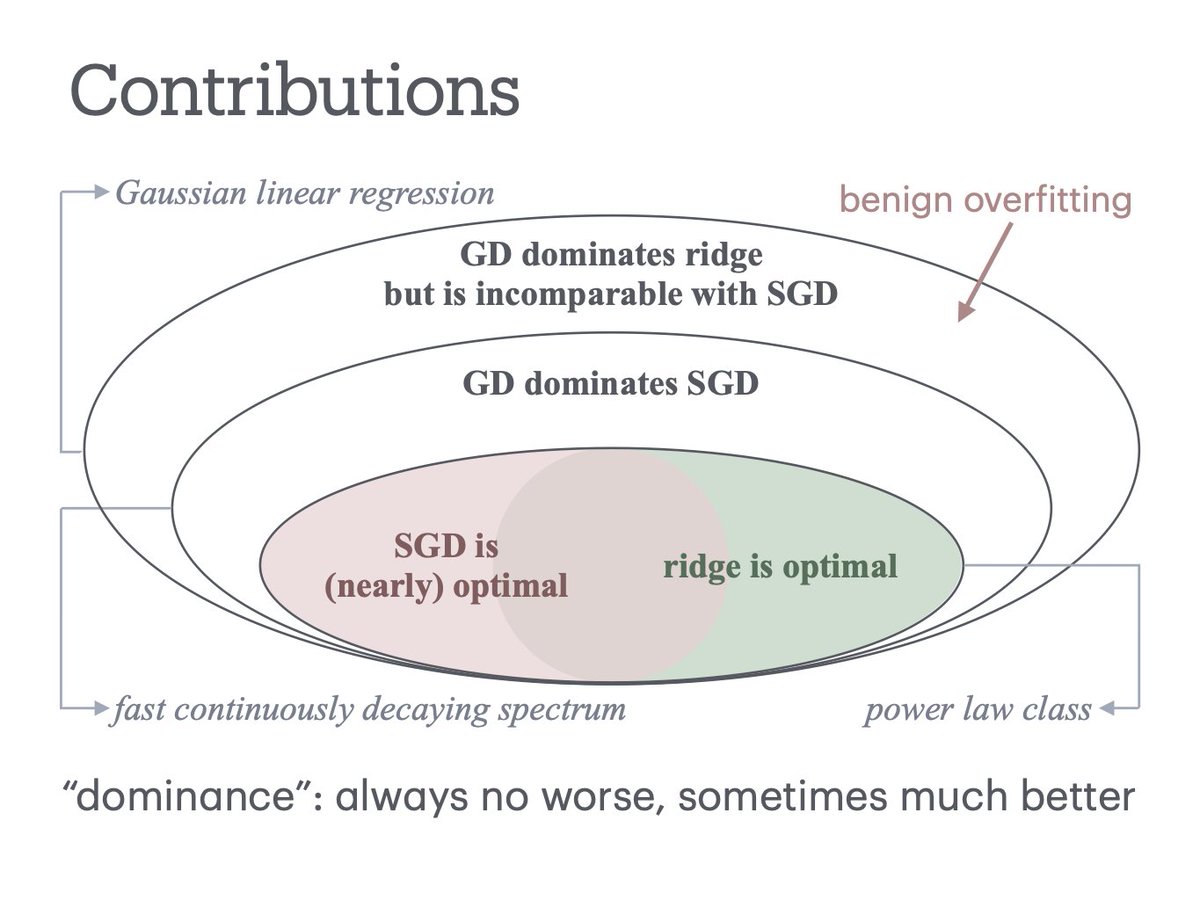
ppl talking about implicit regularization, but how good is it? We show its surprisingly effective, that GD dominates ridge for all linear regression, w/ more cool stuff on GD vs SGD
arxiv.org/abs/2509.17251
English