@jennymaria @FredrikHjelm4 Skatt på kapital och vinst i Sverige är 30%
Svenska
Per Berglund
969 posts


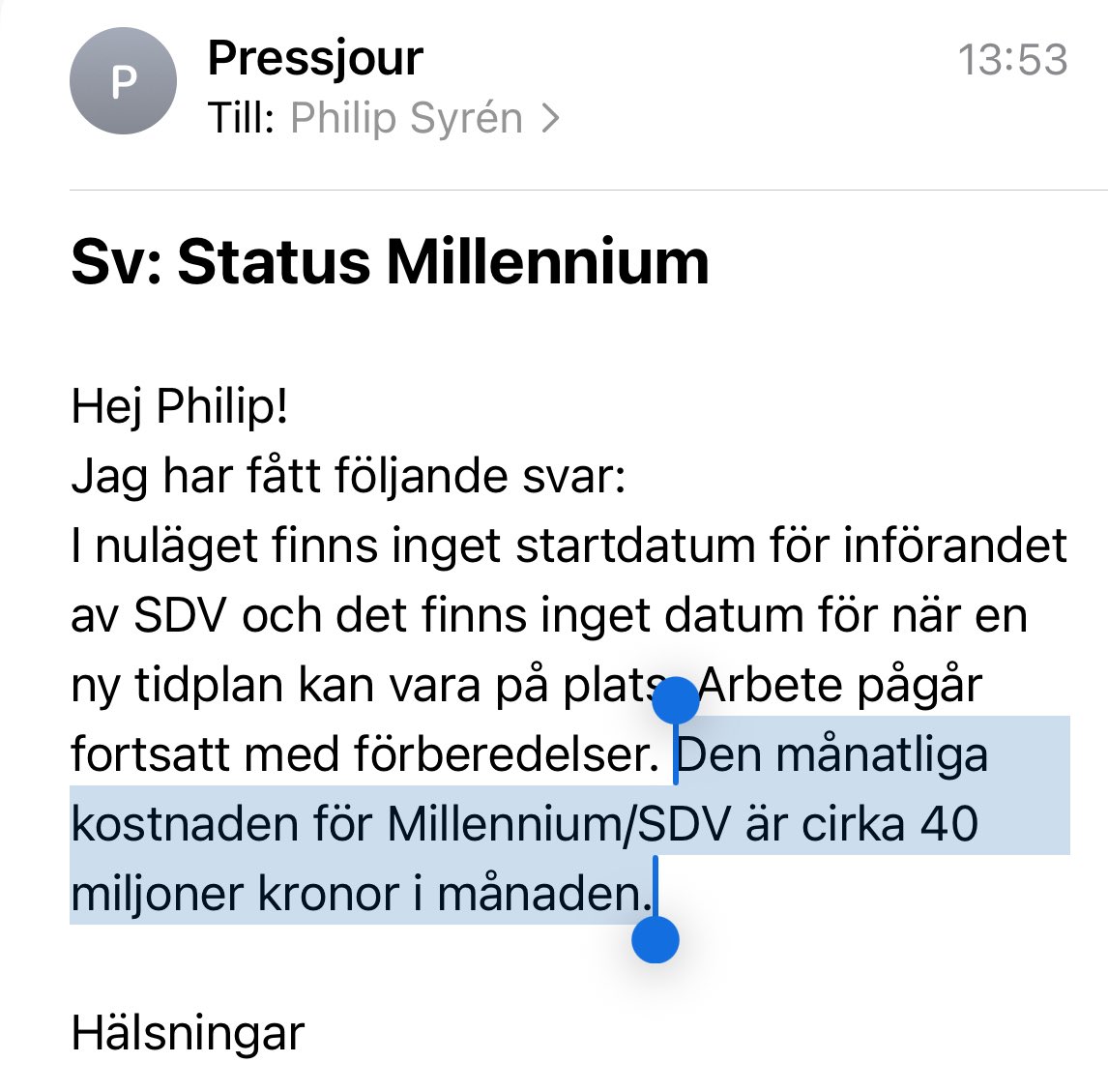
Sweden: we are a high-tax socialist country, everyone contributes, we take care of each other The income tax story is real. Starts at 30%, hits 55% at the top, add employer social fees at 31.4% and you're north of 65% fully loaded on senior salaries Also Sweden: >inheritance tax abolished 2004 >gift tax abolished 2004 >wealth tax abolished 2007 >property tax capped at $900/year regardless of what your home is worth >no tax on unrealized gains >borrow against your holdco personally and live on the loan tax free >capital gains at 20-30%, only when you actually take money out >ISK accounts (think Roth IRA but works for unlisted assets too, no capital gains tax on the inside) I spent years believing the story. Running a company and making some money changed it The big families didn't build dynasties despite the tax system. They built it, across Social Democrat and centre-right governments alike, because the rules never changed when the party did I ran the California comparison. Top income is similar pain, roughly 50% combined. But California taxes capital gains as ordinary income, around 37% combined. Federal estate tax hits 40% above $14M. Sweden is more capital-friendly than California in almost every category that matters for building generational wealth The story Sweden tells about itself is not the real story. It punishes labor and protects capital, same as everywhere else. Just with better parental leave so nobody complains Look, the low capital taxes are actually good policy. Abolishing inheritance tax brought capital back and the data supports it. But the gap between how labor and capital get taxed is hard to justify on fairness grounds. A flatter, more harmonized rate between the two would be simpler and more honest It would also save the country billions of hours in admin overhead, for individuals navigating the rules and for the civil services enforcing them Why not just do a flat level across? Seems easier





New conceptual guide: 🔄 The agent improvement loop starts with a trace Tracing is the foundational primitive for improving agents. A trace gives you the full behavioral record of what an agent actually did. From there, teams can enrich traces with evals and human feedback, turn recurring failures into test cases, validate fixes before shipping, and repeat. This guide breaks down the full improvement loop and why reliable agents are built through trace-centered iteration, not one-off debugging. Read more → langchain.com/conceptual-gui…










Just two humans having a perfectly natural conversation.


Att ställa krav är att bry sig. Även när det handlar om elmarknaden och etableringar av AI- och datacenter. Sverige kan få fler investeringar - utan höjda elpriser och utslagen industri om politiken är aktiv. di.se/debatt/s-krave…