고정된 트윗

Devon James ☀️
19.8K posts

@DevonRJames
Co-Inventor @OpenIndexProto | CTO @Alexandria | formerly sales @Apple, VFX artist @hensoncompany @Sony & @wbpictures, Infantry @USMC & Technical Dir @web3wg

My dear front-end developers (and anyone who’s interested in the future of interfaces): I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept): Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow


🎗️ "Medium-Sized" LLM Burners Coming Soon! 🔥 This Could Make Local HyperToken Generation a Reality. ⚡️ NVIDIA’s worst nightmare? 😱 ⚙️ Application-Specific Hardware Taalas new PCIe ASIC board would burn the entire medium-sized Qwen 3.5-27B LLM straight into silicon 🤯 (already doing it with small models) Taalos said medium models on ASIC would be available in their lab by Spring '26. 💭Imagine: 🚫 No more loading weights 🚀 ~10,000 Tokens Per Second locally (Llama 3.1 8B already @ 17,000 tps) 💻 Standard PC slot, ultra-low power (10x less) 🔋 🌍 100% offline with no cloud, no GPU farm 💰 Reddit unit cost rumor $300 to $400 🖥️ Imagine HyperToken generation on your desktop. 🤖 AI agents that think at light speed. ⚡️ Are you ready? 👀


Best models to run on your hardware level I'll be doing this every week, I hope you guys enjoy. ---- 8 GB ---- Autocomplete for coding (like Cursor Tab) - huggingface.co/NexVeridian/ze… - huggingface.co/bartowski/zed-… Tool calling, assistant style - huggingface.co/nvidia/NVIDIA-… ---- 16 Gb ---- Here things get better: Multimodal - huggingface.co/Qwen/Qwen3.5-9B - huggingface.co/Tesslate/OmniC… - huggingface.co/unsloth/Qwen3.… ---- 24 GB ---- - The best model you can get (thanks Qwen) huggingface.co/Qwen/Qwen3.5-2… - Great model (strong agents) huggingface.co/nvidia/Nemotro… - Mine hehe huggingface.co/0xSero/Qwen-3.… I'm doing a weekly series




.@JackPosobiec: Lord of the Rings is overtly pagan.



Iran doesn't seem intimidated at all and has just released another Lego video mocking the coalition.

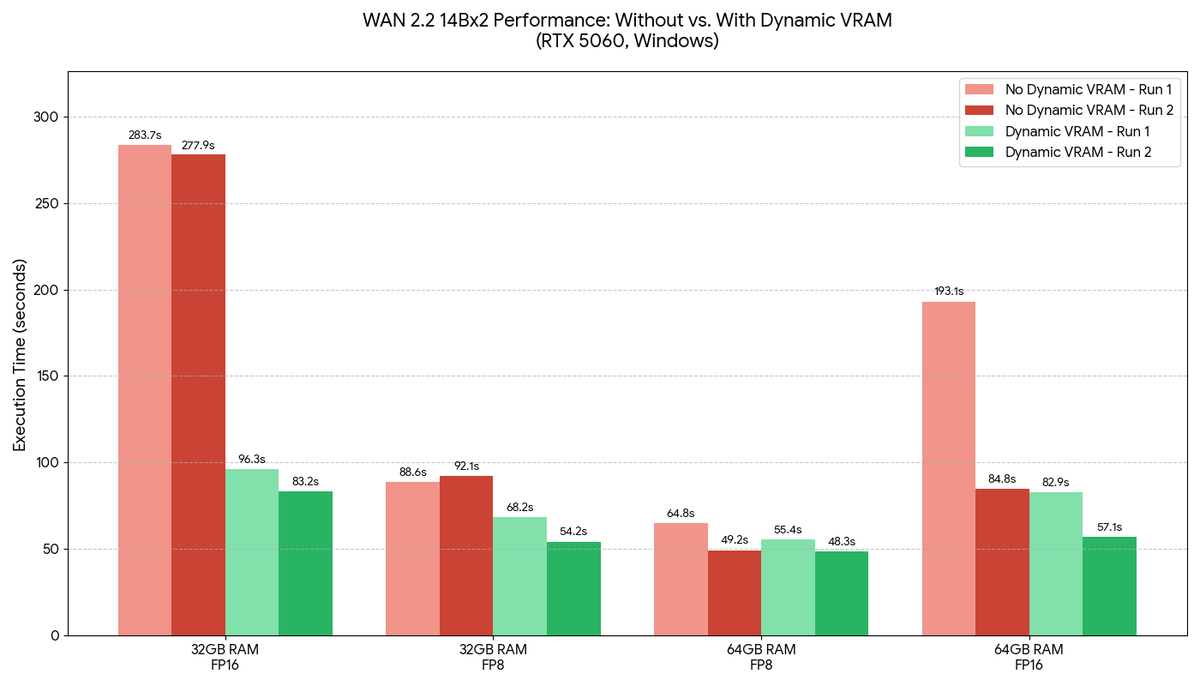

Upgrading your RAM is now unnecessary. Introducing our new ComfyUI Dynamic VRAM optimization. Running local models is now possible on even the most memory constrained hardware. Read more here: blog.comfy.org/p/dynamic-vram…






I trained models across MacBooks using Apple's AirDrop protocol. grove is a distributed training library for Apple Silicon. Devices discover each other over AWDL, a direct radio link. If there's a shared WiFi network it upgrades to that for speed, otherwise everything goes over the direct link. No router, no cloud, no setup. grove start





