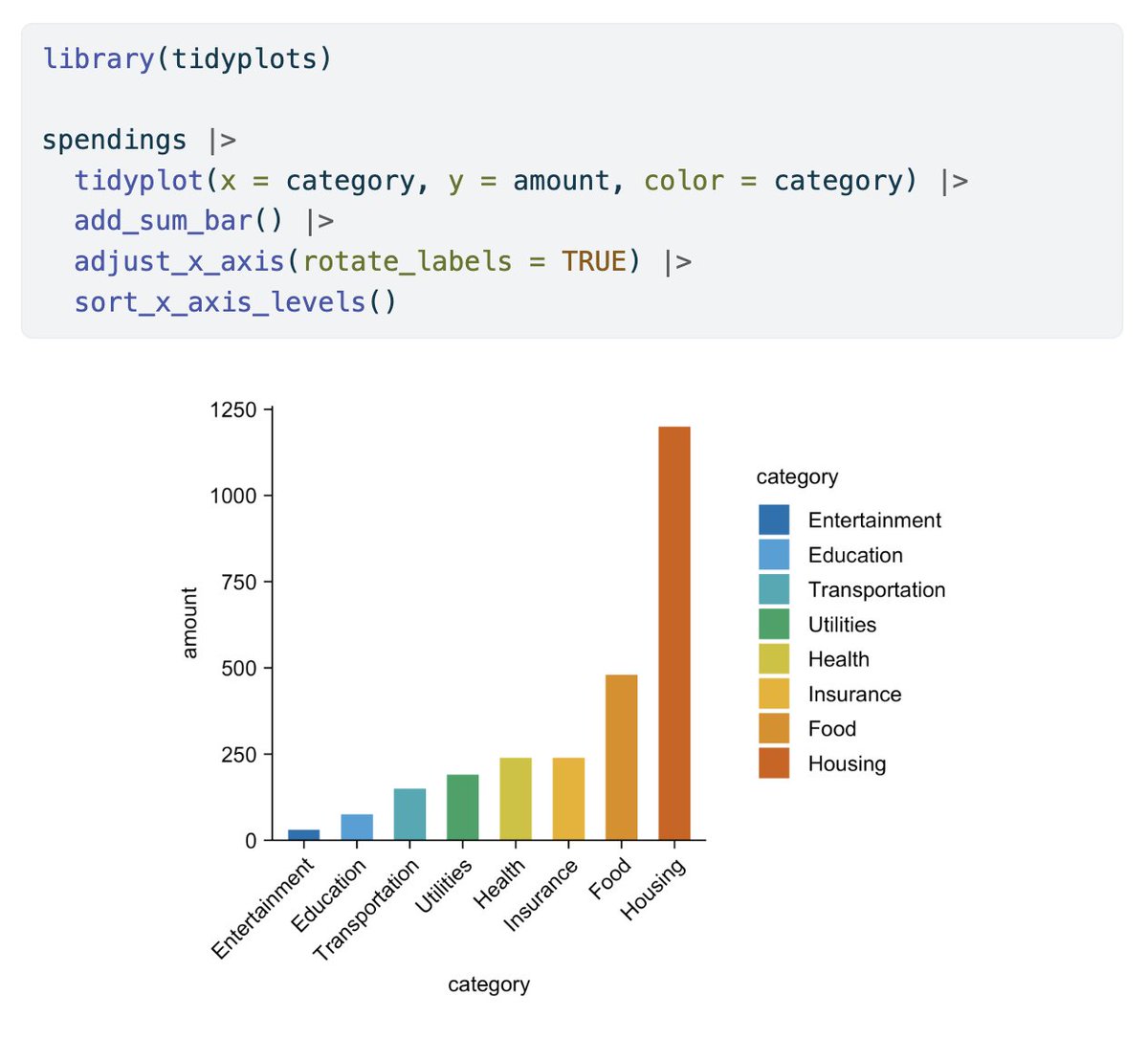
@agraybee I did make a interactive chart for top IMDB shows that compares the average rating to the end (last 2 episodes):
public.flourish.studio/visualisation/…
Dexter and HIMYM also ended pretty badly.
English
The Data Digest
385 posts


What TV Show had the worst ending?