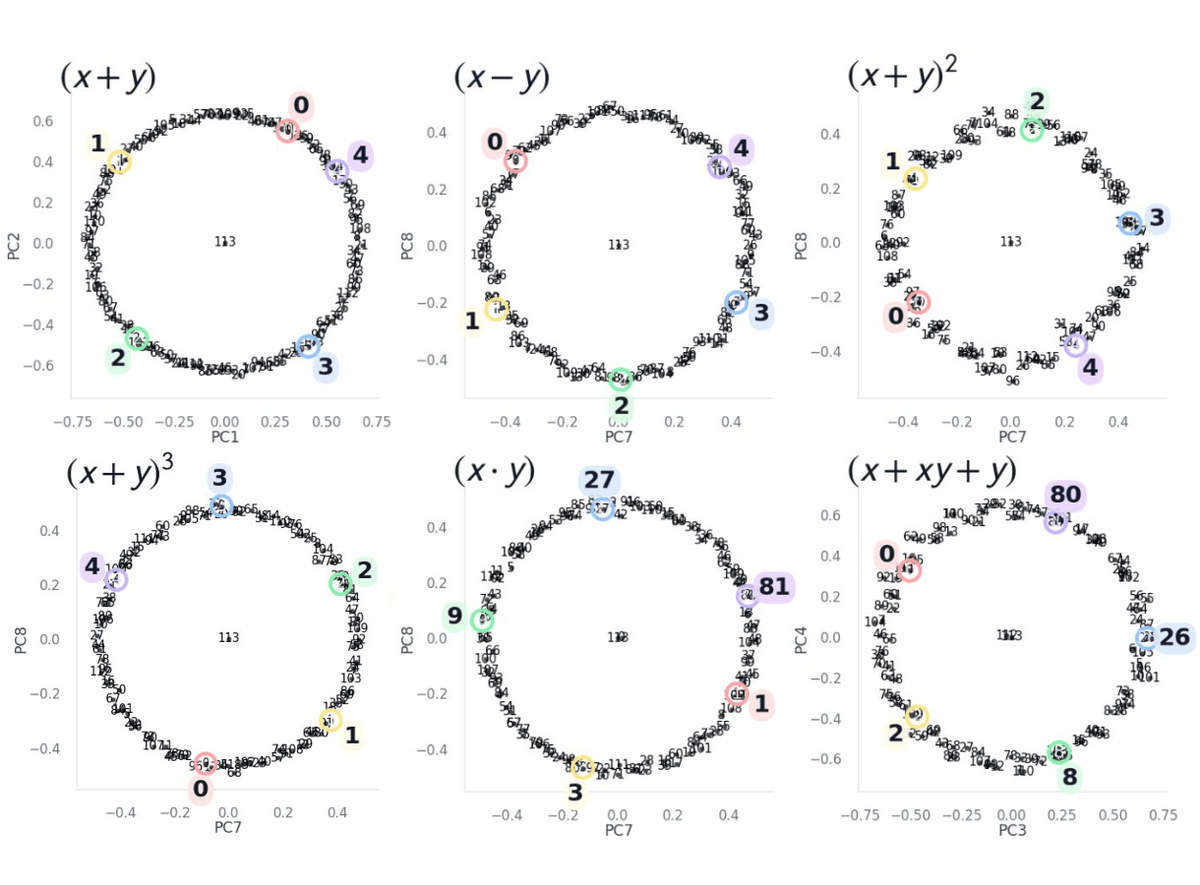
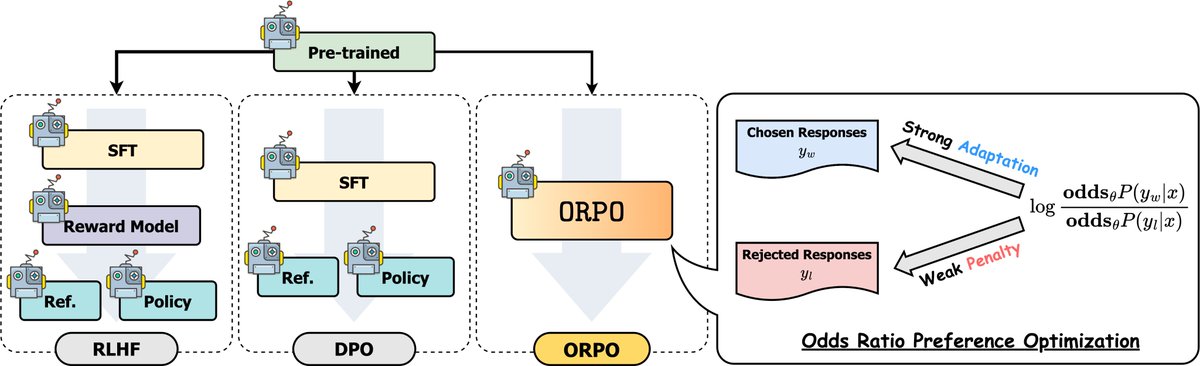
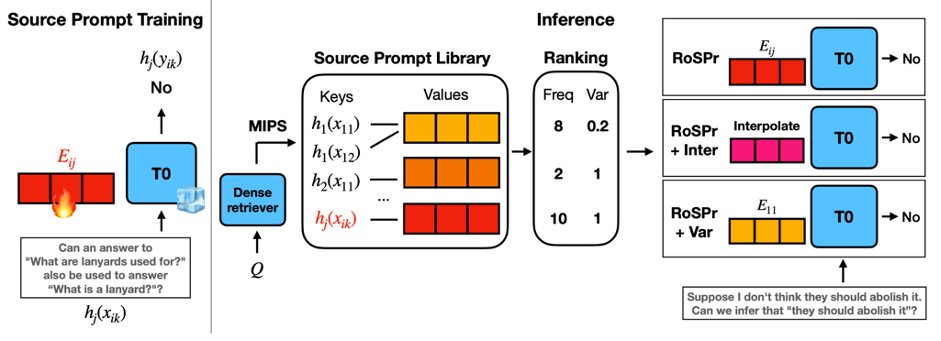
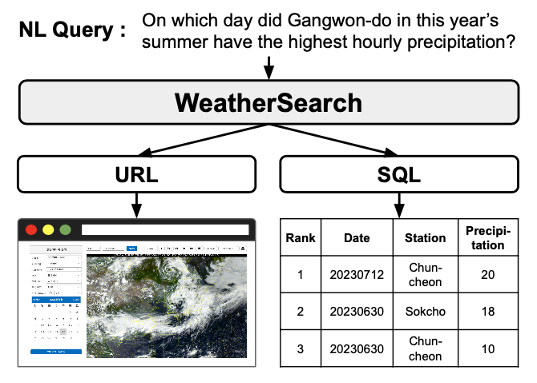
KAIST AI 리트윗함

Achieving generalizable manipulation is the north star for robotics learning, and while we’ve in the past seen incredible results on specific tasks using fine-tuned VLAs, this north star has remained elusive.
Perhaps what is needed is a different approach. DreamZero proposes World Action models (WAMs), which jointly model both action and video in order to achieve state-of-the-art performance on benchmarks like MolmoSpaces and RoboArena.
@SeonghyeonYe of @NVIDIARobotics joins us to talk about building a 14B parameter autoregressive diffusion model which achieves state-of-the-art generalization on real world tasks and on the best available benchmarks.
Watch episode #68 of RoboPapers, with @micoolcho and @chris_j_paxton, now!
English