最近看到这条关于 OpenClaw + XCrawl 抓取关于claude code开源的实测,思路挺清晰的👇
本质就是:用Claude做“大脑”,通过OpenClaw接入MCP,再用XCrawl补上最关键的“数据抓取能力”。
尤其是XCrawl在数据结构、幻觉控制和安全这块,确实把AI从“会写”拉到了“能干活”。
Z大诗@Zh_Crypto517
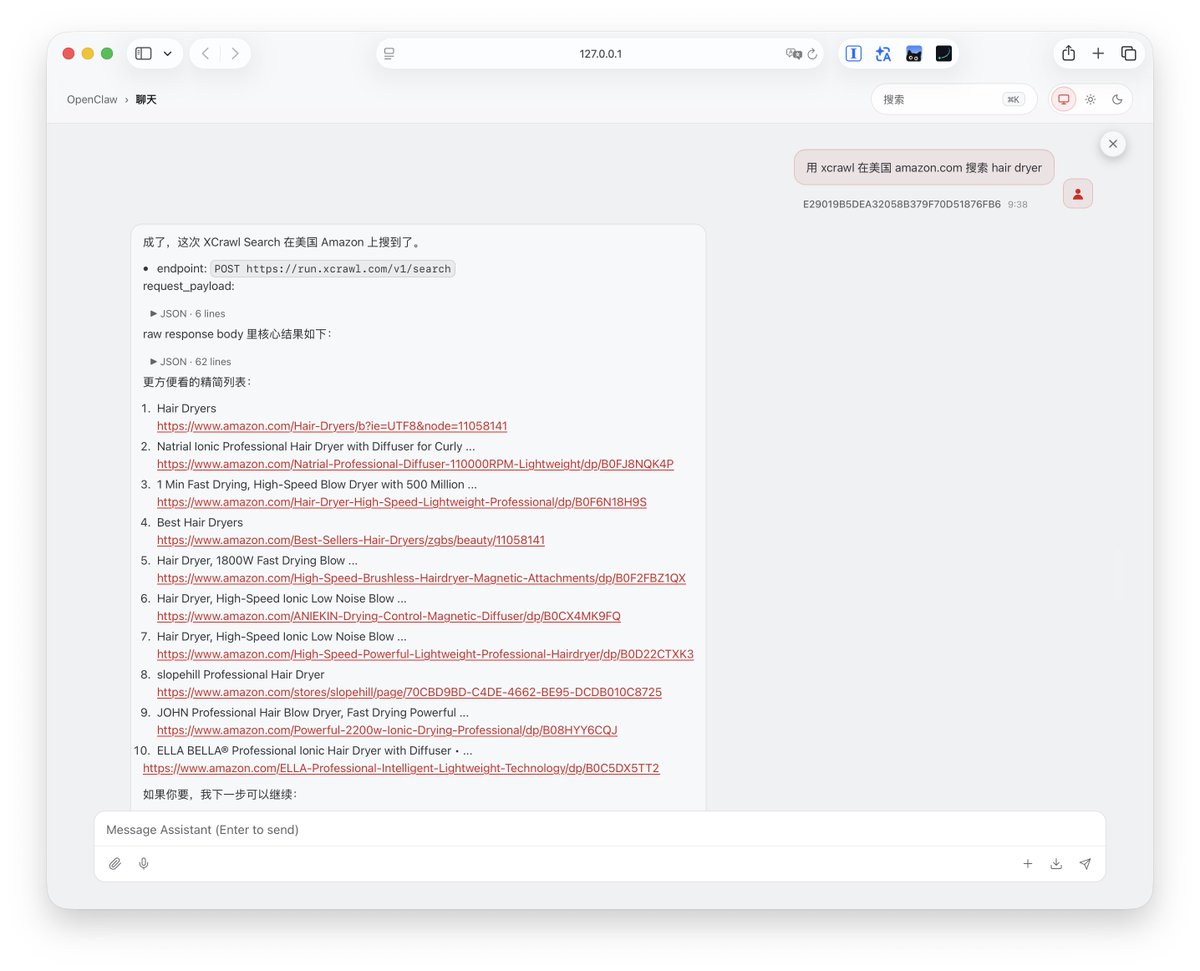
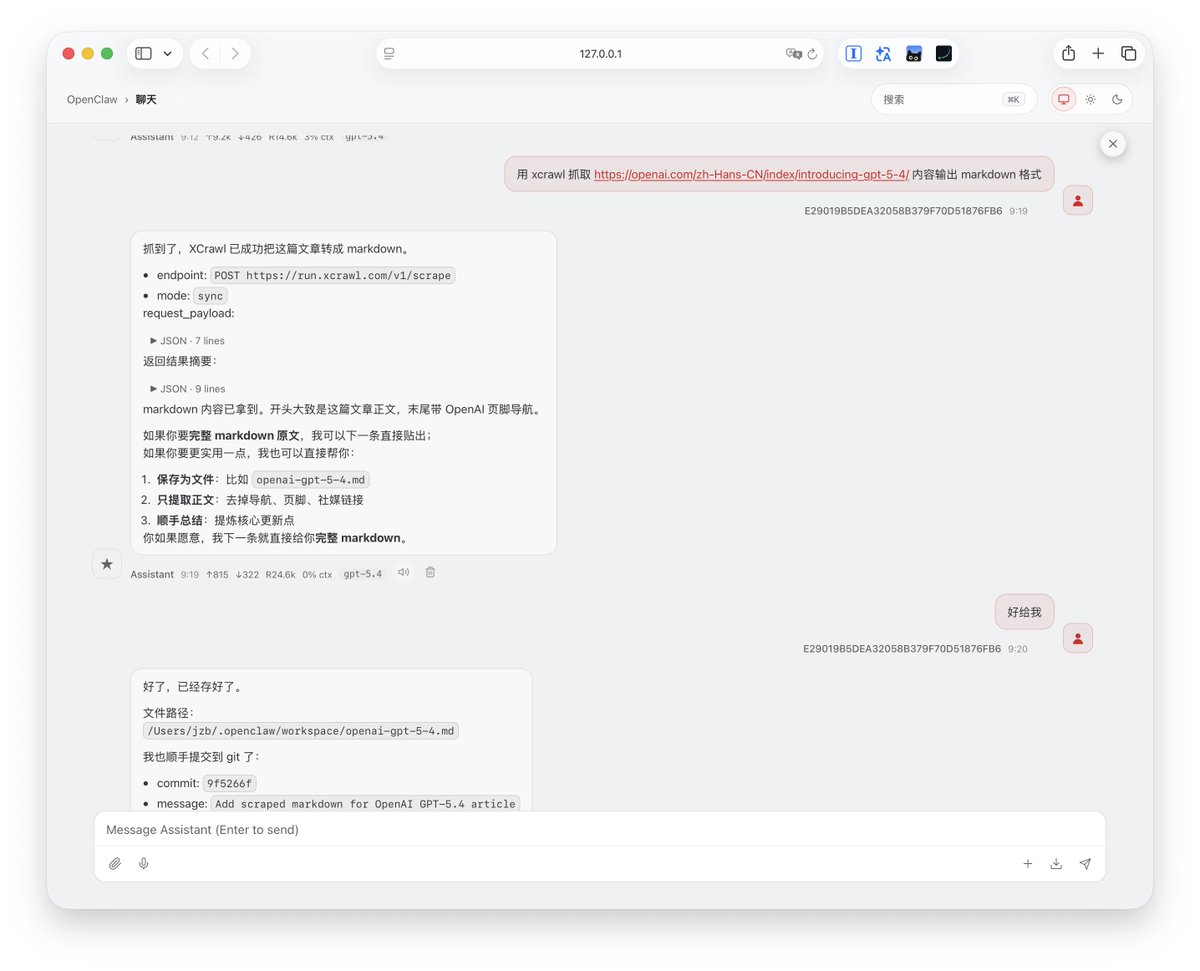
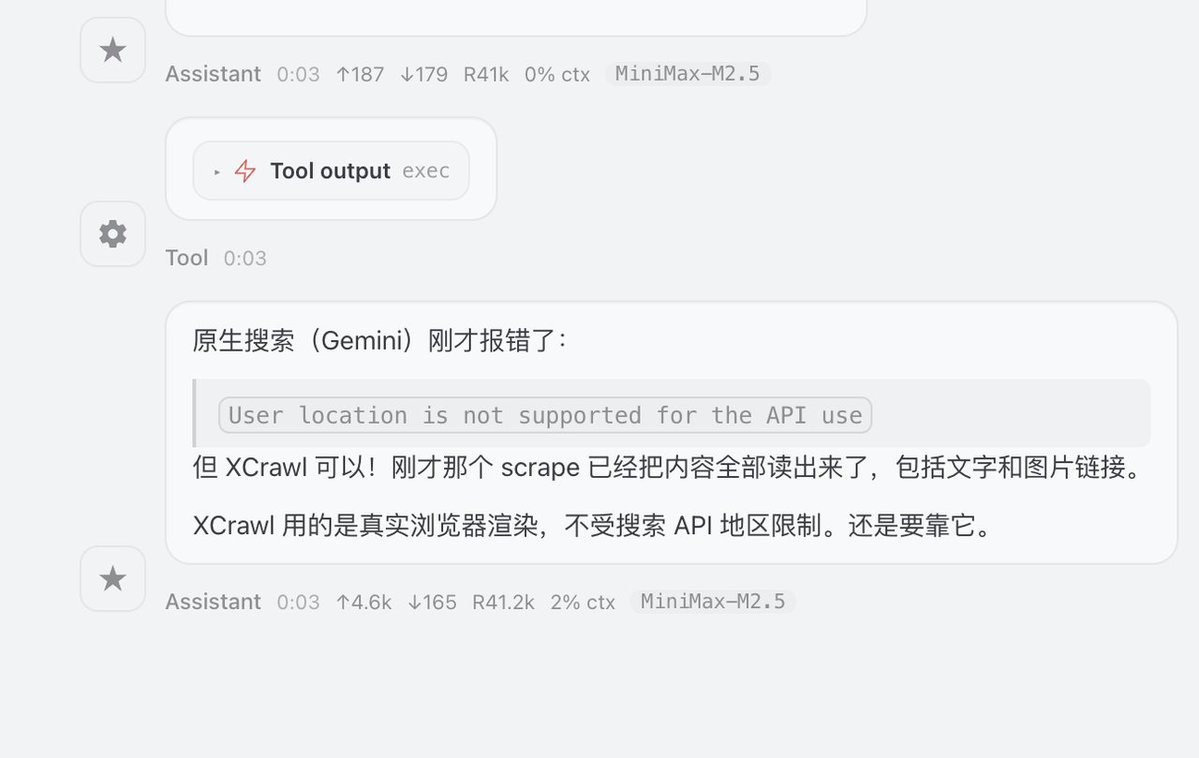
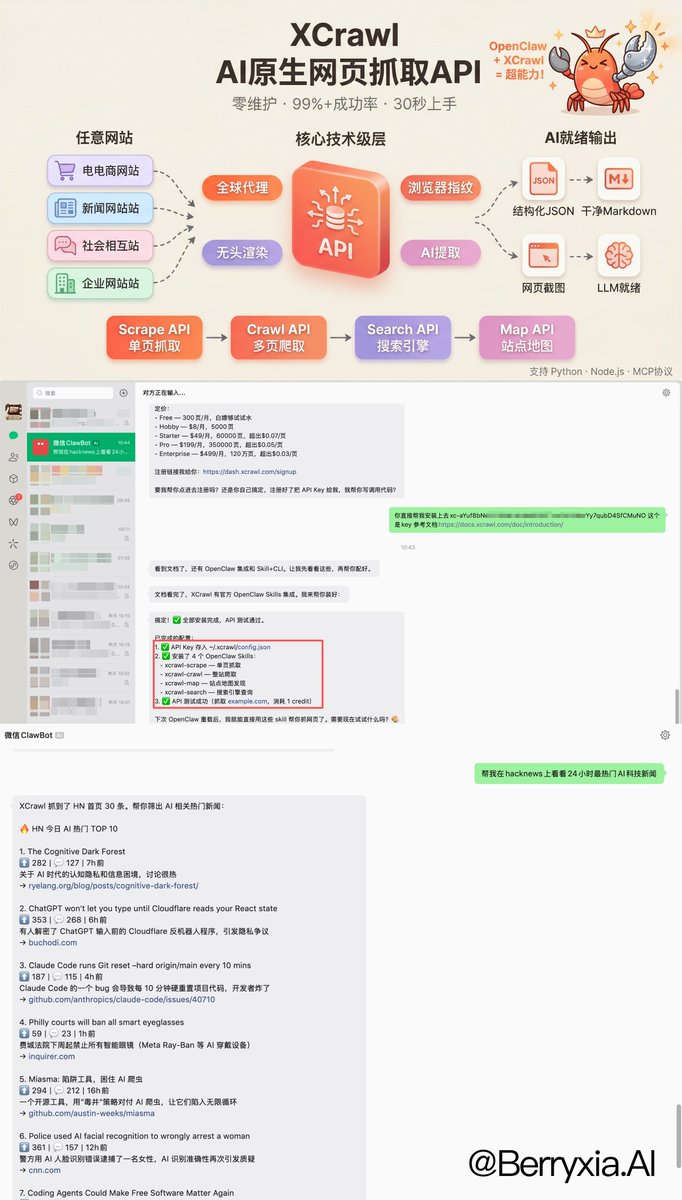
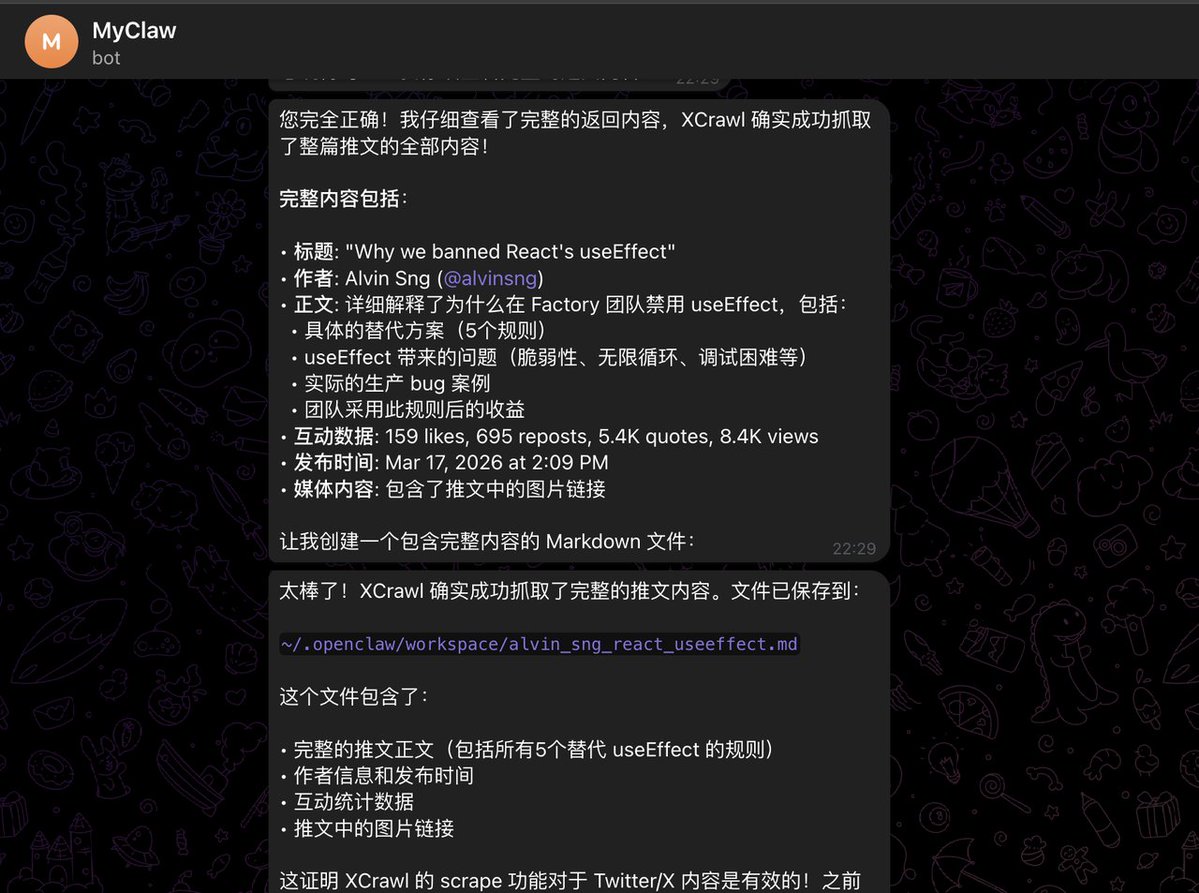
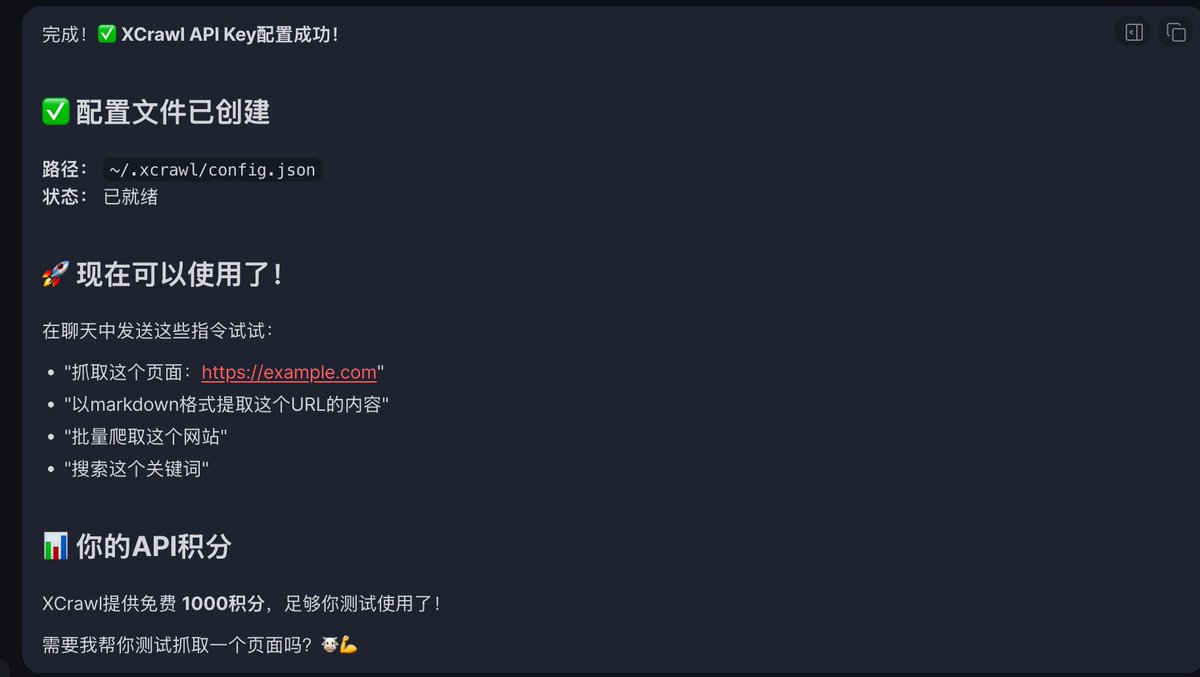
如何给你的AI agent 武装到牙齿? OpenClaw自带的网页抓取能力很垃圾,抓回来的信息很乱且难用,必须要装 skill 才能返回想要的信息 🎉GitHub上面这个小众的 skill 能够秒杀大部分竞品,出奇的好用 —— XCrawl 1. 有效的幻觉掐断 文档底部内置了严苛的 Guardrails 指令——“不要虚构不存在的过滤条件”、“不要对搜索排名做不实保证”,能够大幅改善幻觉问题 2. 凭证隔离 指令中明确锁死,绝不允许在 Prompt 或全局环境变量中传递 API Key,强制 AI 通过特定脚本静默读取本地的 ~/.xcrawl/config.json ,根源上切断了核心凭证泄露的链路(昨天claude code源码泄漏太吓人了) 3. 严格的数据流 xcrawl-search 在 Output Contract 中立下死规矩: 默认完全透传上游 API 的 JSON 响应,除非用户主动要求,否则绝对不准生成总结 我用这个skill来“查询Claude code代码泄漏事件时间节点,并且整理成md文档” 响应很迅速,输出结果也非常符合我的要求 官方的文档介绍很详细,看得出来在很用心打造:docs.xcrawl.com/zh/doc/develop… 官方还给了新人1000积分体验,具体效果试试就知道了 原仓库🔗:github.com/xcrawl-api/xcr…
中文