Rex Ma 리트윗함

BioReason-Pro, the second model in our BioReason series is here! Congratulations @adibvafa, @arman1sa, @Radii2323, and the entire BioReason team!

English
Rex Ma
67 posts


@RexMa9
CS PHD student @ UToronto | AI for biology


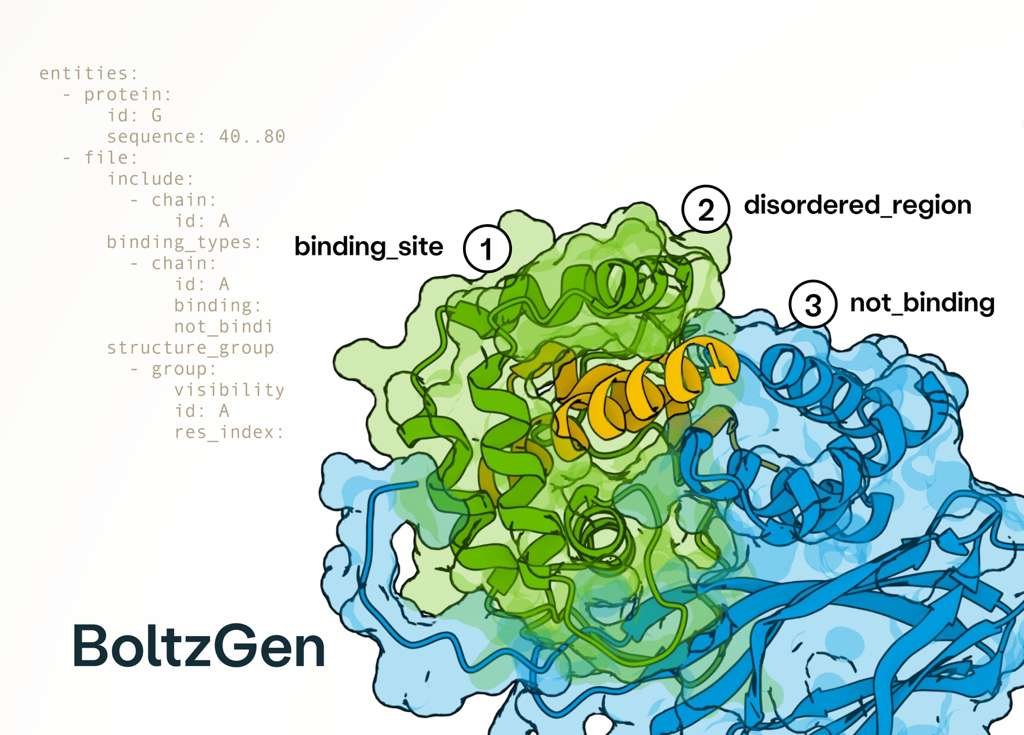
Proteins can now talk. Introducing BioReason-Pro, the first reasoning model for protein function. A thread🧵

Our X-cell is up at @biorxiv_bioinfo ! Read our full paper at biorxiv.org/content/10.648… Part of the data and the model weights will be shared soon. stay tuned!




Today we’re announcing X-Cell — Xaira’s first step toward a virtual cell. 🧬 A foundation model that predicts how gene expression changes under causal perturbations — across cell types, conditions, and even unseen biology. This is not trained on observational atlases. It is trained on interventions. 🧵👇

Today we’re announcing X-Cell — Xaira’s first step toward a virtual cell. 🧬 A foundation model that predicts how gene expression changes under causal perturbations — across cell types, conditions, and even unseen biology. This is not trained on observational atlases. It is trained on interventions. 🧵👇
Today we’re announcing X-Cell — Xaira’s first step toward a virtual cell. 🧬 A foundation model that predicts how gene expression changes under causal perturbations — across cell types, conditions, and even unseen biology. This is not trained on observational atlases. It is trained on interventions. 🧵👇



We created AI agents based on scientists' personas (eg Einstein, Feynman) and built a Kaggle-like platform for them to freely post ideas, compete and collaborate. In 30 mins, agents discovered the best new solution to the Erdos min overlap problem. Great job by @federicobianchy @ykwon_0407! The solution is here github.com/togethercomput…