
Daniel Abyan
1.7K posts

Daniel Abyan
@abyandaniel
⌨️Born to code. 🏢https://t.co/eNlUezQwIn
Armenia 가입일 Haziran 2012
411 팔로잉199 팔로워

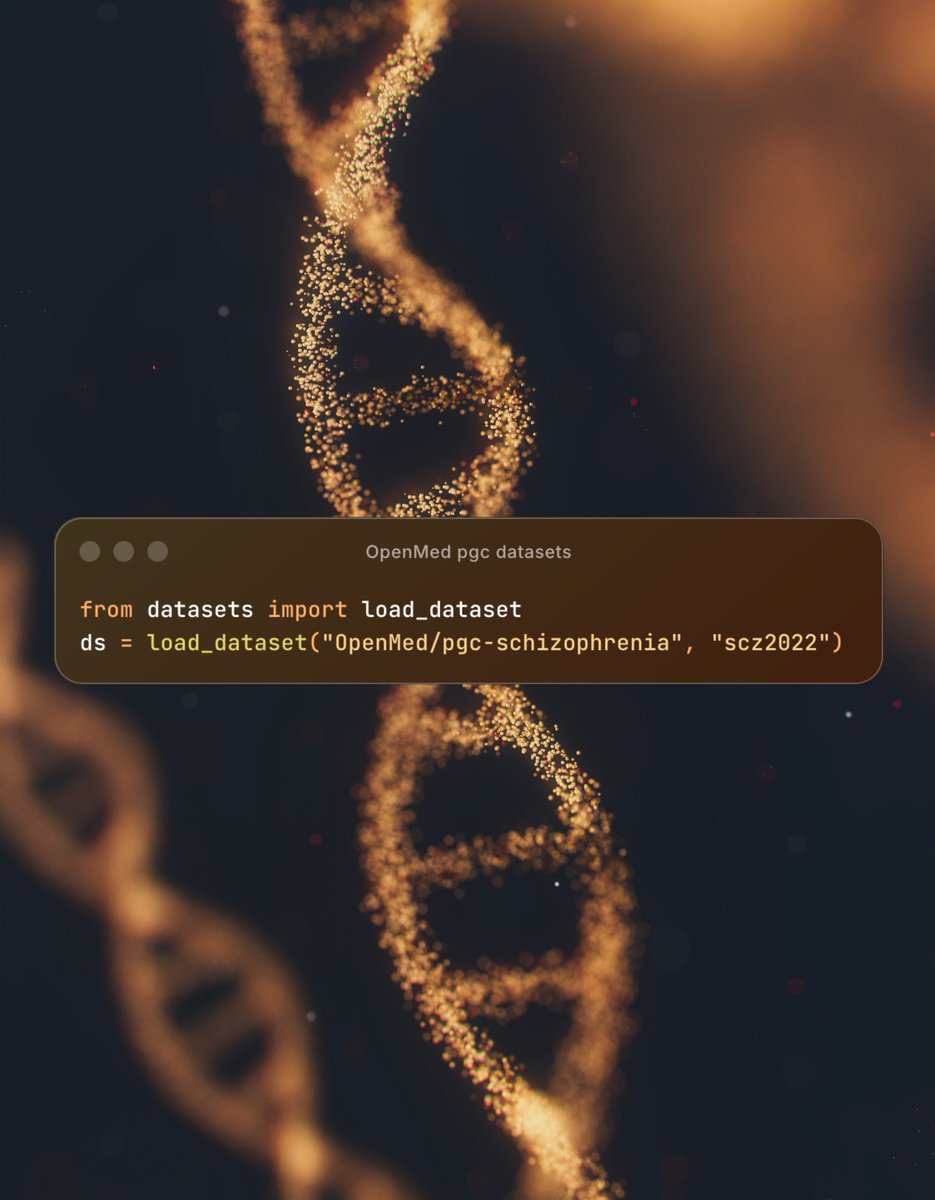
🚨 Over 1 billion rows of psychiatric genetics data. Now on Hugging Face.
ADHD. Depression. Schizophrenia. Bipolar. PTSD. OCD. Autism. Anxiety. Tourette. Eating disorders.
12 disorder groups. 52 publications. Every GWAS summary statistic from the Psychiatric Genomics Consortium.
Before: wget, gunzip, 20 minutes debugging separators, repeat 50 times.
Now: one line of Python.
English

- quantum computing
- next-generation space engines (e.g. fusion rockets)
- programmable and personalized medicine
- SAI
- brain–computer interfaces
- bioprinting
- nuclear fusion energy
- self-replicating machines
- self-improving AI.
The future motivates 🔥
English
The greatest problem humanity needs to solve right now is consciousness.
Transferring consciousness into new environments will be a turning point in human history.
English
@NightSkyToday We're creating new bodies for robots, better than ours. Maybe for us too, who knows?
English

🚨: South Korean engineers are developing an artificial muscle 30 times more powerful than human tissue and capable of supporting 4,000 times its own weight.

English

@xah_lee AGI ARC-3. But AI will outperforms us there in 1 year imho
English

@vishaldeshpande Yep 💯 This story shows how badly drug development needs strong IT talent. Companies like Isomorphic Labs and Bioptic.io are already building AI-powered medicines. This motivates me 😍
The future of healthcare = biology + tech.
English

@abyandaniel Rosie's story was really heartwarming and motivational. Like if someone out of pure love can go to a length to create a vaccine protocol without any previous experience it shows what people are capable of doing.
He's the real John Wick.
English
The availability of such technologies is impressive. Cancer and, apparently, 99% of all diseases will be a thing of the past in 5-10 years.
Paul S. Conyngham@paul_conyngham
English
@fchollet 10,000 IQ is a completely different cognitive perception of the world. In my opinion, this is where the line between humans and ants lies. Such AI will perceive reality in a completely different way.
English

One of the biggest misconceptions people have about intelligence is seeing it as some kind of unbounded scalar stat, like height. "Future AI will have 10,000 IQ", that sort of thing. Intelligence is a conversion ratio, with an optimality bound. Increasing intelligence is not so much like "making the tower taller", it's more like "making the ball rounder". At some point it's already pretty damn spherical and any improvement is marginal.
Now of course smart humans aren't quite at the optimal bound yet on an individual level, and machines will have many advantages besides intelligence -- mostly the removal of biological bottlenecks: greater processing speed, unlimited working memory, unlimited memory with perfect recall... but these are mostly things humans can also access through externalized cognitive tools.
English
I'm filled with excitement when I think about it. If these kinds of engines become a reality, colonizing our solar system will be a simple task. I can't believe we'll get so close to that goal so quickly.
independent.co.uk/tech/nuclear-f…
English


NASA is advancing nuclear power and propulsion in space to accomplish President Trump’s national space objectives.
With SR-1 Freedom, launching in 2028, we will demonstrate nuclear electric propulsion and deliver SkyFall helicopters to Mars.
In collaboration with @Energy, these capabilities are key to future missions to Mars and beyond.
A new chapter of deep space exploration begins. 🚀
English

CPU vs GPU vs TPU vs NPU vs LPU, explained visually:
5 hardware architectures power AI today.
Each one makes a fundamentally different tradeoff between flexibility, parallelism, and memory access.
> CPU
It is built for general-purpose computing. A few powerful cores handle complex logic, branching, and system-level tasks.
It has deep cache hierarchies and off-chip main memory (DRAM). It's great for operating systems, databases, and decision-heavy code, but not that great for repetitive math like matrix multiplications.
> GPU
Instead of a few powerful cores, GPUs spread work across thousands of smaller cores that all execute the same instruction on different data.
This is why GPUs dominate AI training. The parallelism maps directly to the kind of math neural networks need.
> TPU
They go one step further with specialization.
The core compute unit is a grid of multiply-accumulate (MAC) units where data flows through in a wave pattern.
Weights enter from one side, activations from the other, and partial results propagate without going back to memory each time.
The entire execution is compiler-controlled, not hardware-scheduled. Google designed TPUs specifically for neural network workloads.
> NPU
This is an edge-optimized variant.
The architecture is built around a Neural Compute Engine packed with MAC arrays and on-chip SRAM, but instead of high-bandwidth memory (HBM), NPUs use low-power system memory.
The design goal is to run inference at single-digit watt power budgets, like smartphones, wearables, and IoT devices.
Apple Neural Engine and Intel's NPU follow this pattern.
> LPU (Language Processing Unit)
This is the newest entrant, by Groq.
The architecture removes off-chip memory from the critical path entirely. All weight storage lives in on-chip SRAM.
Execution is fully deterministic and compiler-scheduled, which means zero cache misses and zero runtime scheduling overhead.
The tradeoff is that it provides limited memory per chip, which means you need hundreds of chips linked together to serve a single large model. But the latency advantage is real.
AI compute has evolved from general-purpose flexibility (CPU) to extreme specialization (LPU). Each step trades some level of generality for efficiency.
The visual below maps the internal architecture of all five side by side, and it was inspired by ByteByteGo's post on CPU vs GPU vs TPU. I expanded it to include two more architectures that are becoming central to AI inference today.
👉 Over to you: Which of these 5 have you actually worked with or deployed on?
____
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
GIF
English

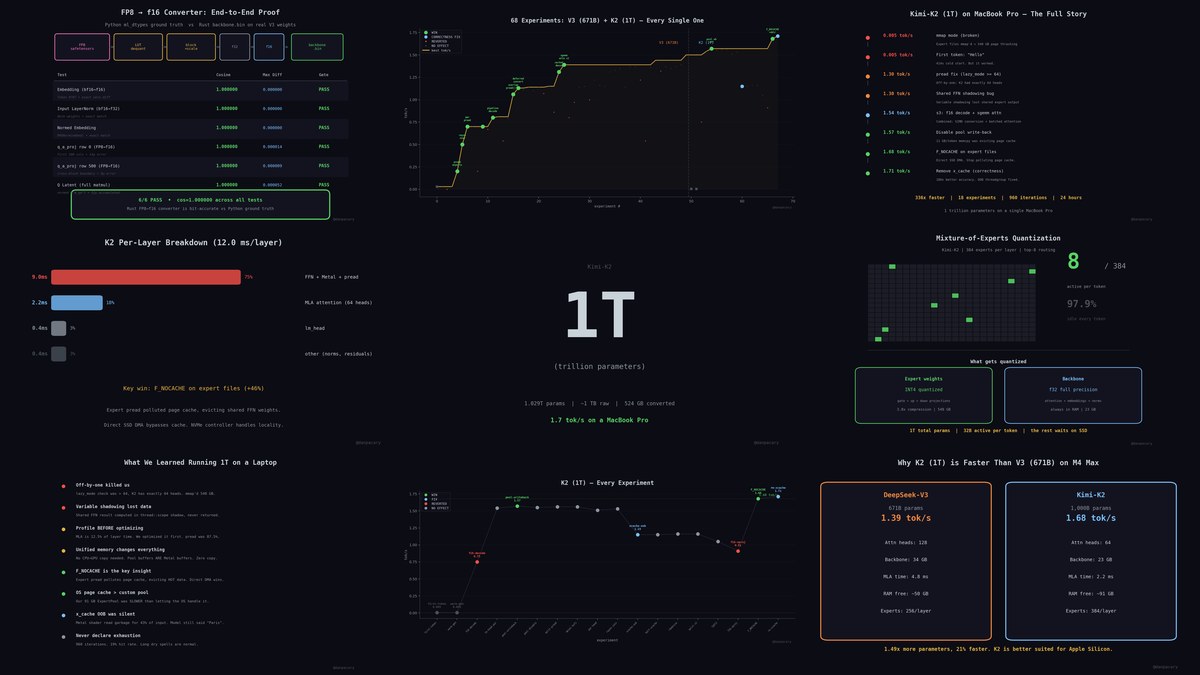
I got a 1T (trillion) parameter model running on my MacBook Pro.
Kimi-K2. 1.029T params.
~1 TB raw weights.
524 GB converted.
~1.7 tok/s.
Yesterday it was 671B. Today it's 1T.
Same laptop. Same M4 Max. No cloud.
When I say we: I mean Claude and me.
English

ARC-AGI-3 launches tomorrow
- The first interactive reasoning benchmark built to test human-like intelligence in AI
- 1,000+ levels across 150+ environments requiring exploration, learning, planning, and adaptation
- Video-game-like tasks with no instructions, requiring multi-step reasoning and rule discovery
The highest score on ARC-AGI-1 currently is Gemini 3.1 Pro with 98%, while on ARC-AGI-2 it is Gemini 3 Deep Think with 84.6%

English

David Sinclair said: "You can reverse aging by 75% in 6 weeks… by reinstalling the "software" of the body so that it's young again."
This idea sprouted when he proved in his first experiment that you can accelerate aging in mice:
"We took two mice born on the same day—same age, same genetics. We 'scratched the CD' of one mouse, corrupting its software and accelerating its aging. The result was dramatic. One looked far older than its brother."
He believed if you can give aging, you can also take it away.
Tomorrow, I'll share his experiment on how he reversed aging in mice (and then Monkeys).
— @davidasinclair
English

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
GIF
English