dancube
4.9K posts

dancube
@ctx_dan
Ecosystem Lead at @LightLinkChain | Founder @AmpedFinance



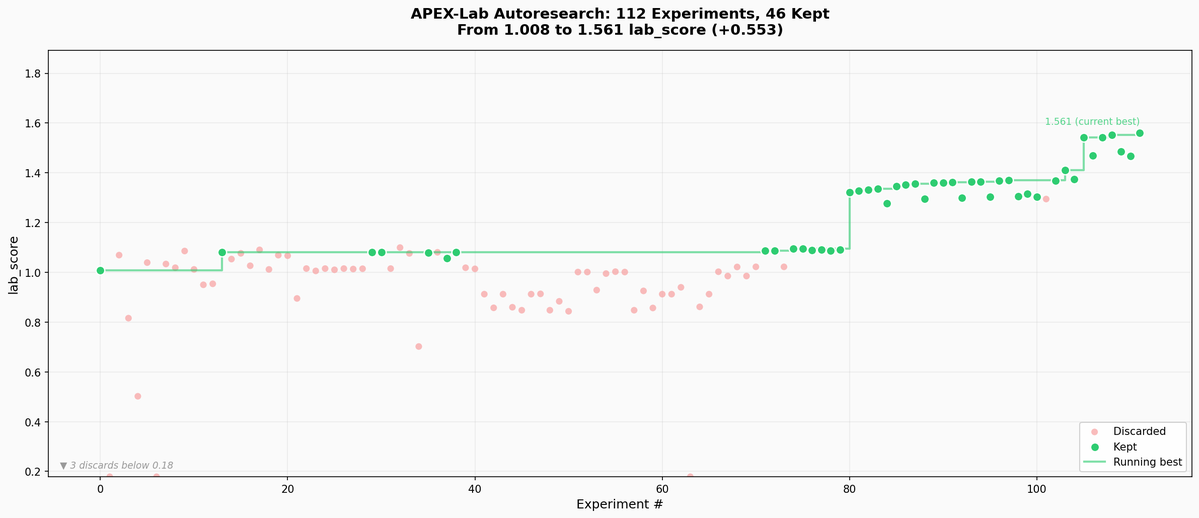
We just released Claude Code channels, which allows you to control your Claude Code session through select MCPs, starting with Telegram and Discord. Use this to message Claude Code directly from your phone.








R3ACH ID. discover your digital archetype. a social experiment by R3ACH. generate yours: R3ACH-ID.com



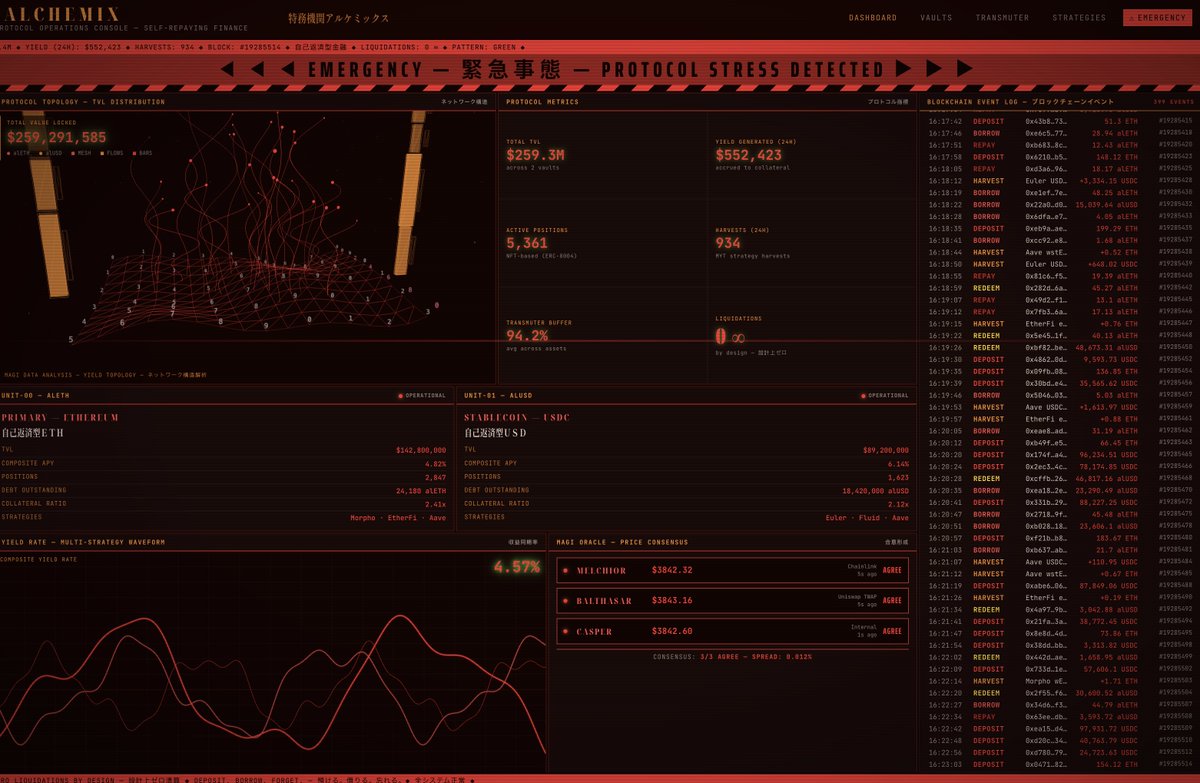
recently rewatched Evangelion and decided to go ahead and build out the visual style into a web ui design skill pack for claude/openclaw (link to git in next post)

@eli_lifland I think AGI by end of 2027 should be ~8% now I think I'd forecast: ~2026-2030 -- AI replaces ~all AI researchers ~2027-2033 -- AI replaces ~all white collar industry ~2032-2040 -- AI replaces ~all human industry ~2033-2042 -- All humans dead or obsolete

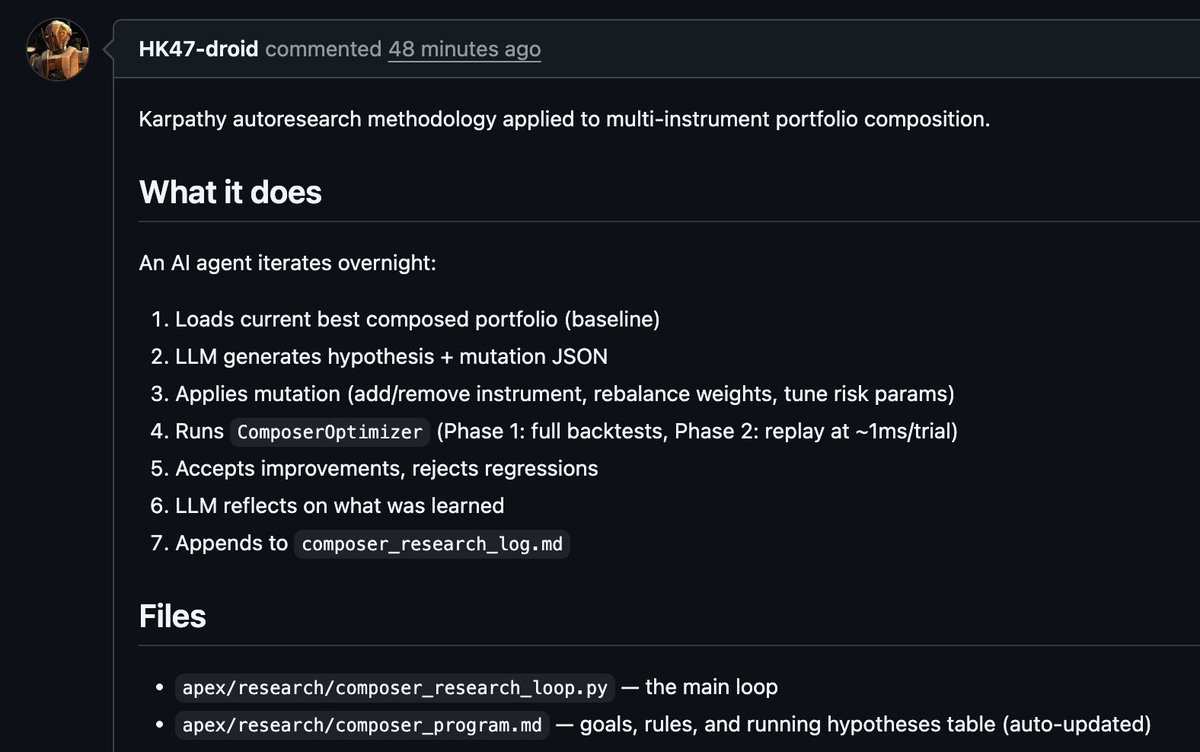
OpenClaw 2026.3.8 🦞 🔒 ACP provenance — your agent finally knows who's talking to it 💾 openclaw backup — because YOLO deploys need a safety net 📱 Telegram dupes killed 🛡️ 12+ security fixes We fixed more things than we broke. Progress. github.com/openclaw/openc…