ㅅㅇ
242 posts




시발... 그놈의 AI가 사람을 대체할 수 있다는 시절 언제오냐...
확실히 뭔가 급하게 보여줘야할때 AI 시키면 매우 빨라서 좋은데....
내가 주력으로 삼는 특정 분야는 AI 붙여도 개발 속도가 똑같거나 헛소리하는거 검증하는 시간이 더 늘어났음. ㅠㅠ
그런데 그 특정 분야가 내 밥벌이인데 AI로 유의미한 속도 향상을 못봐서 답답함.
장코드@jsh3pump_
요즘 면접장에서 주로 받는다는 질문 "AI 대신 왜 본인을 뽑아야 한다고 생각하십니까"
한국어
ㅅㅇ 리트윗함
한창 프리랜서 활동할 때 고용보험이랑 산재보험을 자발적으로 셀프 가입했단말임.
당시 프리랜서 하던 다른 사람들은 나보고 다들 미쳤냐고 했었음. 안내도 되는걸 왜 스스로 돈줘가며 손실보냐고.
결과는?
그로부터 10년 뒤에 경력 증빙을 할 일이 생겼는데 당연히 그때 프로젝트 했던 곳들이 온전하게 있을리도 없고 있어도 이전 자료를 수소문하는건 불가능에 가까운 상황이었음.
경력 인정에서 손실보는거 아닐까 걱정했는데, 그 미쳤냐고 수근대던 고용보험 가입 이력덕분에 경력 손실 안보고 그대로 인정받음.
한국어
ㅅㅇ 리트윗함

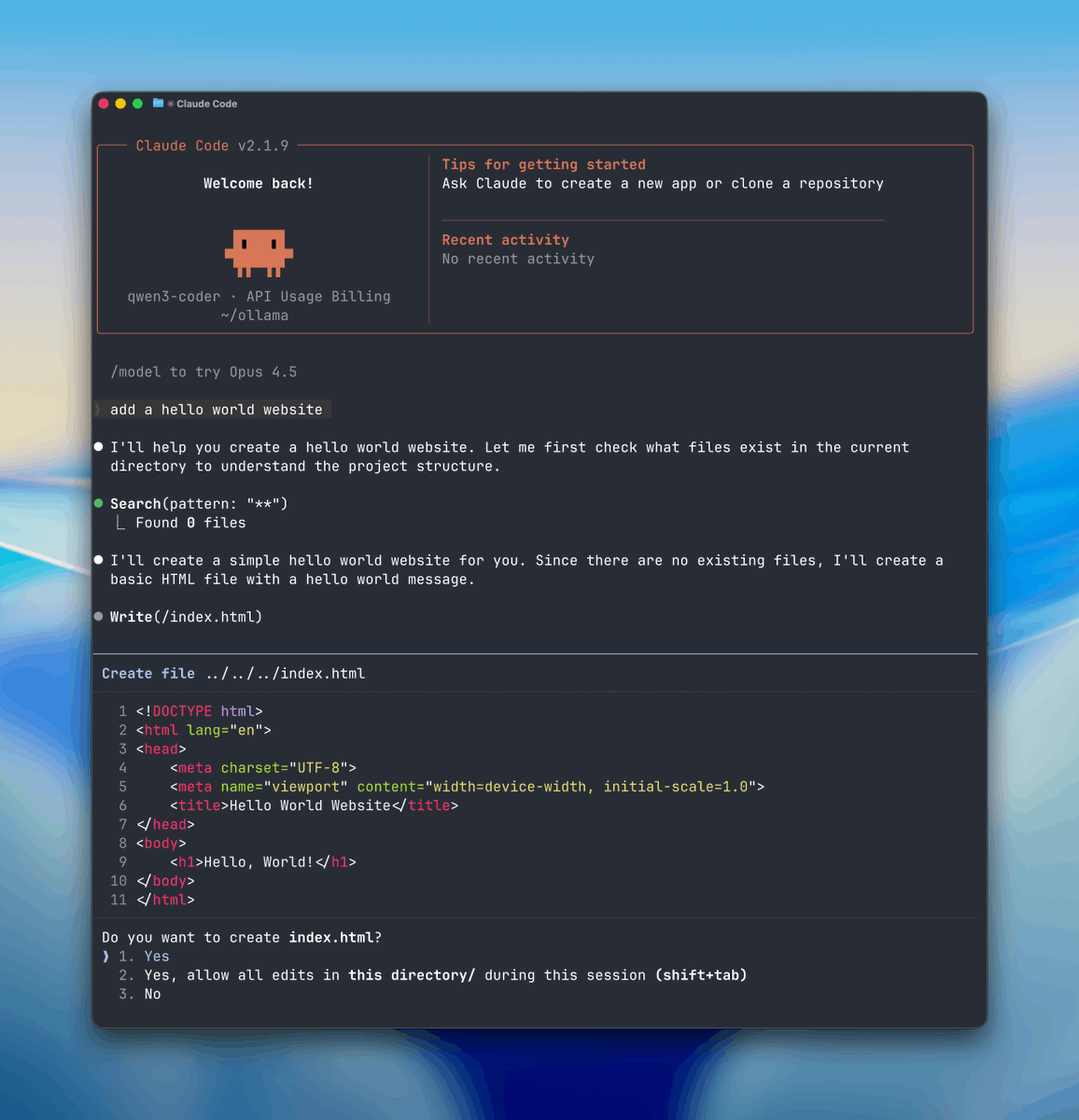
🚨BREAKING: You can now run Claude Code for FREE.
No API costs. No rate limits. 100% local on your machine.
Here's how to run Claude Code locally (100% free & fully private):
English
ㅅㅇ 리트윗함

New Partnership: AKEDO × Minara AI @minara 🤝
We are thrilled to announce a community partnership between AKEDO, the multi-agent AI content creation platform, and Minara AI, an AI-powered trading system that autonomously analyzes market conditions and executes strategies in real time.
✅ What’s coming:
Community Synergy
Expanding interaction between the AKEDO and Minara AI communities.
Exclusive Access
Providing AKEDO members with hands-on access to Minara’s AI-driven trading experience — where strategies adapt dynamically to market regimes.
Future Ecosystem
Building a long-term model for an interconnected AI Creator + AI Finance network, where intelligence doesn’t just create — it acts.
Stay tuned for the future of AI. 🌟
#AI #Web3 #AKEDO #MinaraAI #Partnership

English
ㅅㅇ 리트윗함

ㅅㅇ 리트윗함

"강의 도중 순간적으 로 깨달음을 얻은 그는 슈밋-칼먼 필터의 개발에 착수하게 된다. 이 필터는 기본적으로 다양한 데이터를 통합하고 문제를 방해할 수 있는 '잡음'을 걸러냄으로써 우주선의 더욱 정확한 위치를 제공하는 데 필요한 계산 시간을 줄인다."

한국어
0: 영개 (Young gay)
1: 한개 (Hot gay)
2: 두개 (Do gay)
3: 세개 (Say gay)
8: 여덟개 (Adult gay)
9: 아홉개 (I hope gay)
10: 열개 (You're gay)
11: 열한개 (You're hot gay)
12: 열두개(You're too gay)
20: 스물개 (Small gay)
100: 백개 (Back gay)
캣츠파파@ceolmh3
우리나라는 천재들이 많다 이게 왜 다 읽히는건데 ㅋㅋㅋ
한국어
`에드작러 집가고 싶다` 게시글 포워딩 이벤트
t.me/Iwanttogohome0…
X에 업로드하면 참여하고 구글폼 작성하면 끝.
~2/28
한국어
2년 전 쯤에 전국의 모든 대학교를 총 망라한 대학 연합 마약동아리 적발된 적 있었는데
이 시기에 엄청 기괴한 뉴스 많이 나왔었음.
얼마 전까지 같은 학교 학생이었는데 어느날 돌변해서 창문으로 던져 살해한다던가
생명이 위독할 직전까지 폭행한 뒤에 옷을 다 벗겨서 겨울에 길거리에 버린다던가
이런거 다 약을 했다는 이유로, 심신미약을 직접적으로 인정하면 여론의 뭇매를 맞으니 간접적인 방법으로라도 아득바득 인정해서 감형해줬다고 들었는데
이때 정말 작정하고 소탕을 했어야 했는데 정치인이라는 사람들은 마약을 처벌보다는 그 세력을 활용해야한다는 이상한 논의하다가
결국 아무것도 못했지
이런거 보면 화남
한국어
ㅅㅇ 리트윗함

이미지 변환 라이브러리 정리
Node.js - sharp sharp.pixelplumbing.com
Cloudflare Workers - cf-wasm/photon github.com/fineshopdesign…
브라우저 - jSquash #readme" target="_blank" rel="nofollow noopener">github.com/jamsinclair/jS…
CF, 브라우저에서 쓸 수 있는 라이브러리가 있는 게 반갑네
한국어
나는 사람들이 내 사생활을 캐기 시작하면
언제부턴가 입을 다물어버리던데...
특별하게 내 사생활에 대단한거나 무서운 것도 없는데도 한결같이 그래가지고
이게 맞나....? 싶지만
요즘 예전과 달리 괴롭히는 사람이 없어서 좋음. ㅋㅋ
쨔@mansik_ggang
사람들 입이 정말 가볍다는점 하루만에 제 얘기 다퍼지는거보고 절대 사생활 얘기 안하고 다녀요 모두들 입조심하세요 믿을 사람 없습니다
한국어
ㅅㅇ 리트윗함

1인개발자 필수 사이트 모음
나는 개발보다 여기서 보내는 시간이 훨씬 더 많았었음
1. sensortower.com: 국가별 앱 순위, 매출 순위, 스크린샷, 구독모델 상품 목록 웹에서 확인 가능. 여기 구경하다보면 아이디어 샘솟음
2. mobbin.com: 수많은 앱 온보딩, 주요기능 스샷 깔끔히 정리되어있음. 벤치마킹 & 화면기획에 큰 도움
3. revenuecat.com: 구독플랜 관리 saas. 편의성 압도적임 돈값함
4. superwall.com: 유료구독 관련 ui관리, 결제 ab테스팅, paywall관련 끝판왕 노코드. 템플릿엄청많음
5. supabase.com: GOAT
6. appsflyer.com: 마케팅 어트리뷰션 트래킹 툴. LTV, roas계산등에 필수
7. mixpanel.com: GA 슈퍼 상위호환. Amplitude가 더 유명하긴함 취향차
8. reddit.com: 대형 커뮤니티. 디시같은거라고 보면됨. 여기 눈팅하는것만으로도 인사이트 폭발
9. polar.sh 사업자 없이 웹 saas 결제 받아봐야할때 좋음. 레몬스퀴지는 stripe인수이후 조금 상태이상해졌고 paddle은 제일안정적이지만 첫 심사가 끝이안남 많이 바쁜듯 몇주씩걸림
10. resend.com 개발자지원 미친수준인 메일 발송 SaaS. 관대한 무료플랜
mobbin 제외 9개 다 무료 플랜 존재하고 트래픽 늘어서 사업커지기전에 돈 낼 일 거의 없음
한국어

[ 피지컬 AI 시대, 데이터의 ‘소유권’이 핵심 인프라가 된다 ]
AI 산업이 빠르게 진화하면서 이제 경쟁력의 본질은 모델 성능 → 데이터 확보 → 데이터 권리 구조로 이동하고 있습니다
이런 흐름 속에서 IP 블록체인 인프라 @StoryProtocol 와 실세계 데이터 수집 플랫폼 젠오(ZenO)의 협력은 단순 파트너십 이상의 의미를 가집니다!
이번 협업의 핵심은 하나입니다
👉 AI 학습 데이터에도 ‘저작권’과 ‘수익권’을 부여하는 구조
젠오는 사용자들이 업로드한 영상·음성 데이터를 수집하고, 품질 검증과 익명화 과정을 거쳐 데이터 마켓플레이스에 저장합니다
여기서 스토리 블록체인은 데이터의 메타데이터와 라이선스 정보를 기록하는 역할을 맡습니다
이 구조가 중요한 이유는 크게 세 가지입니다!
1️⃣ 프로그래머블 데이터 권리
데이터 사용 조건을 코드로 정의하고 자동 실행할 수 있게 됩니다
→ AI 기업 입장에서는 법적 리스크 감소, 데이터 공급자는 권리 보호 강화
2️⃣ 투명한 라이선싱 + 자동 수익 분배
AI 모델이 특정 데이터를 활용해 수익을 창출하면, 기여자에게 자동으로 보상이 돌아가는 구조가 가능해집니다
→ Web3가 AI 경제에 실제로 적용되는 대표 사례
3️⃣ 피지컬 AI 시장의 핵심 병목 해결
로봇, 자율주행, 공간 AI 등 피지컬 AI는 텍스트 데이터보다 훨씬 비싼 ‘실세계 데이터’를 필요로 합니다
→ 결국 데이터 공급 네트워크를 가진 플랫폼이 가장 큰 가치를 갖게 될 가능성이죠
특히 흥미로운 포인트는 젠오가 도입한 2단계 인센티브 모델입니다
• 베타 기간: XP 지급 (참여 유도)
• 상용화 이후: 데이터 판매 수익을 스테이블코인으로 분배
이 구조는 과거 “데이터는 무료로 제공된다”는 인터넷 패러다임을 뒤집고,
👉 데이터 노동(Data Labor)이 경제로 연결되는 모델을 보여줍니다
✅ 장기적으로 보면 이 협력은 다음 질문을 던집니다
“AI 시대의 원유는 데이터인데, 그 원유의 소유자는 누구인가?”
스토리와 젠오가 만드는 구조는 AI 경제의 새로운 자본시장 레이어가 될 가능성이 있습니다
피지컬 AI, 데이터 IP, 온체인 라이선싱이 결합되는 영역이죠
앞으로 몇 년간 가장 큰 기회 중 하나가 될 수도 있습니다
#IP, #STORYprotocol, #storysylee
향후 스토리가 보여줄 퍼포먼스 기대가 됩니다!

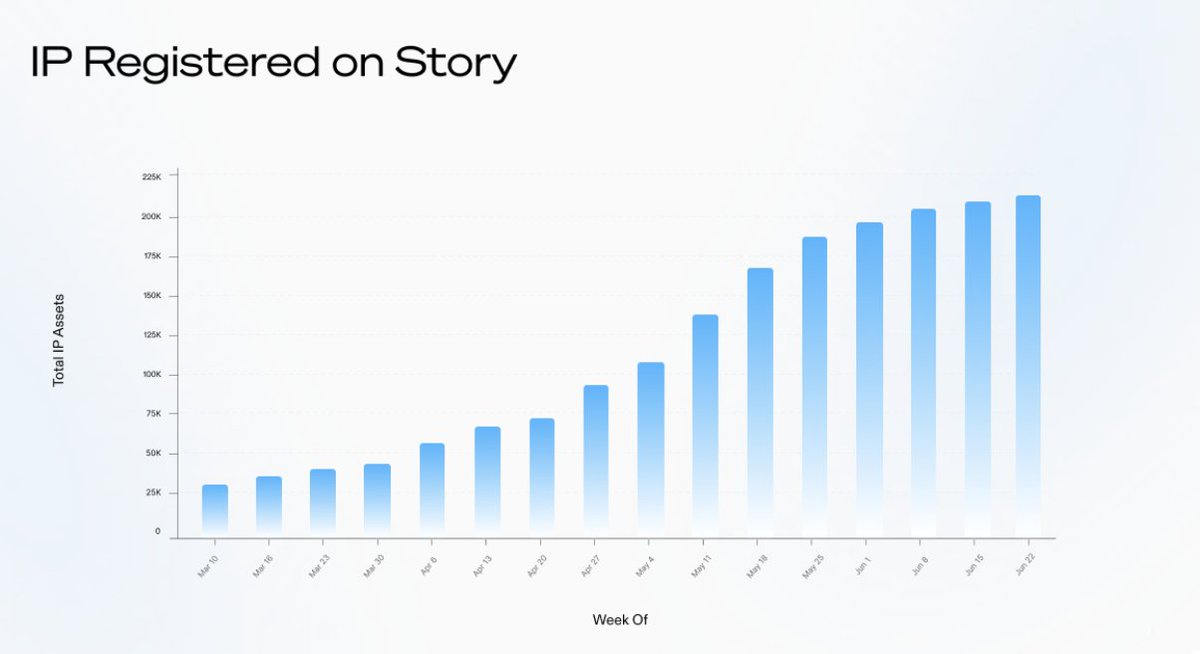
Story@StoryProtocol
We’ve made it past the first year of mainnet and continue to ascend with the community. Our OG expectations are now fully in effect as year two begins. The standard is clearer than ever for keeping OG status. A review is coming. Who’s truly meeting the bar?
한국어
ㅅㅇ 리트윗함

Before AI Agents, RAGs were the most popular GenAI solution
Let us understand their evolution from their development...
Depending on your use case, you would only use a few types of RAGs.
To understand that,
📌 Let's break down the popular architectures behind RAGs with their pros and cons:
1. Naive RAG
- Retrieves documents via straightforward embedding similarity.
- Feeds into LLM to generate an answer.
2. Graph RAG
- Extracts structured knowledge graphs from retrieved text.
- Uses graph context to enrich the LLM prompt for better reasoning.
3. Hybrid RAG
- Combines standard vector retrieval with graph-based retrieval.
- Retrieves both dense embeddings and structured graph context.
4. HyDe (Hypothetical Document Embeddings)
- Generates a hypothetical answer document from the user’s query
- Embeds that hypothetical document and uses it to retrieve real documents.
5. Contextual RAG
- Enriches each chunk with contextual information before embedding.
- Reasons over every chunk individually, adding document-level context to improve retrieval accuracy.
- Reduces information loss by maintaining semantic boundaries within chunks.
6. Adaptive RAG
- Analyzes whether the query requires simple or multi-step retrieval.
- Breaks down complex queries into smaller reasoning steps when needed.
7. Agentic RAG
- Learn In-depth from here:
lnkd.in/gUb9T233
📌 Best fit Use Cases
- Naive RAG: Best for simple FAQ-style retrieval where direct matching works well.
- Graph RAG: Ideal for exploring complex relationships in structured knowledge bases.
- Hybrid RAG: Great for combining unstructured text and structured graph knowledge in answers.
- HyDe: Useful for retrieving relevant documents when queries are vague or underspecified.
- Contextual RAG: Perfect for long documents where maintaining context across chunks is critical.
- Adaptive RAG: Suited for handling both straightforward and multi-step, layered questions.
- Agentic RAG: Best for complex tasks needing planning, memory, and multiple data/tool integrations
📌 But what about Self-RAG and Modular RAG?. You can learn more about the current and 3 more types of RAGs in my latest newsletter: lnkd.in/gau-BKNs
Save 💾 ➞ React 👍 ➞ Share♻️
& follow for everything related to AI Agents
GIF
English