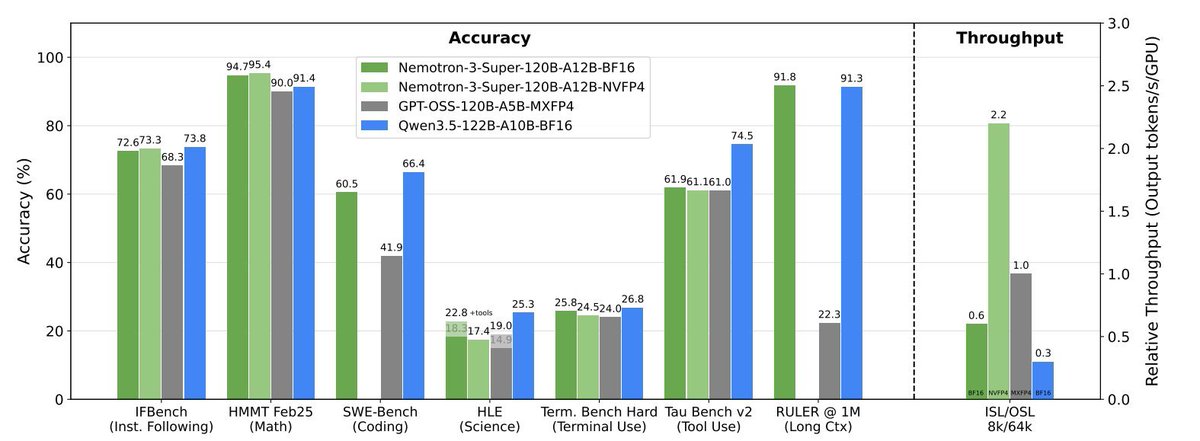
고정된 트윗

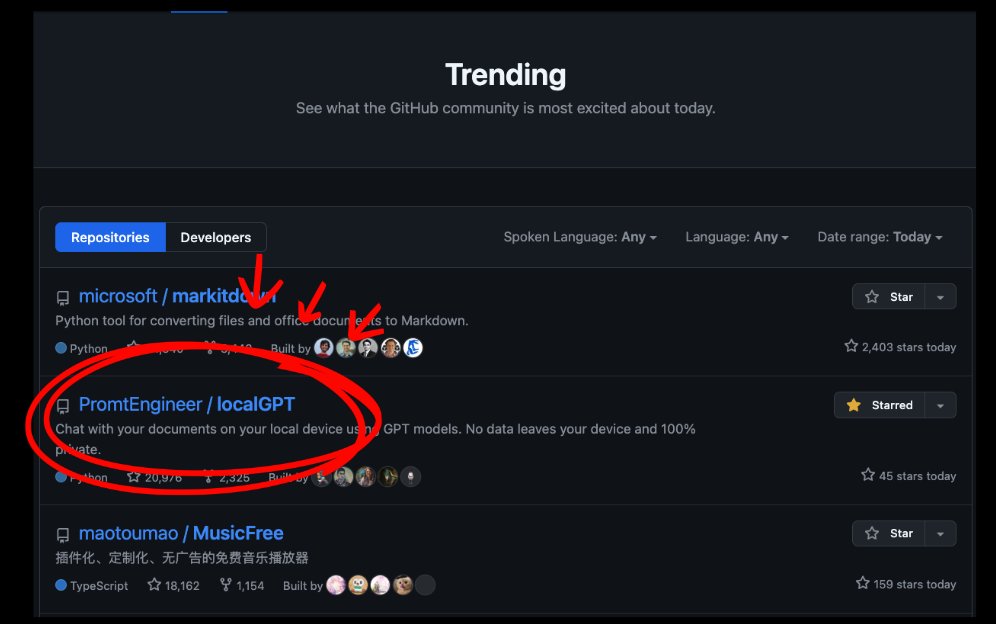
Yesterday I released the 'preview' of LocalGPT v2, and its already trending on Github
Its an opinionated implementation of private RAG powered by local models via @ollama and @huggingface. Give it a ⭐️ on @github (🙏🙏)
Watch the video in next post to learn how it was built...
English