fudingyu 리트윗함

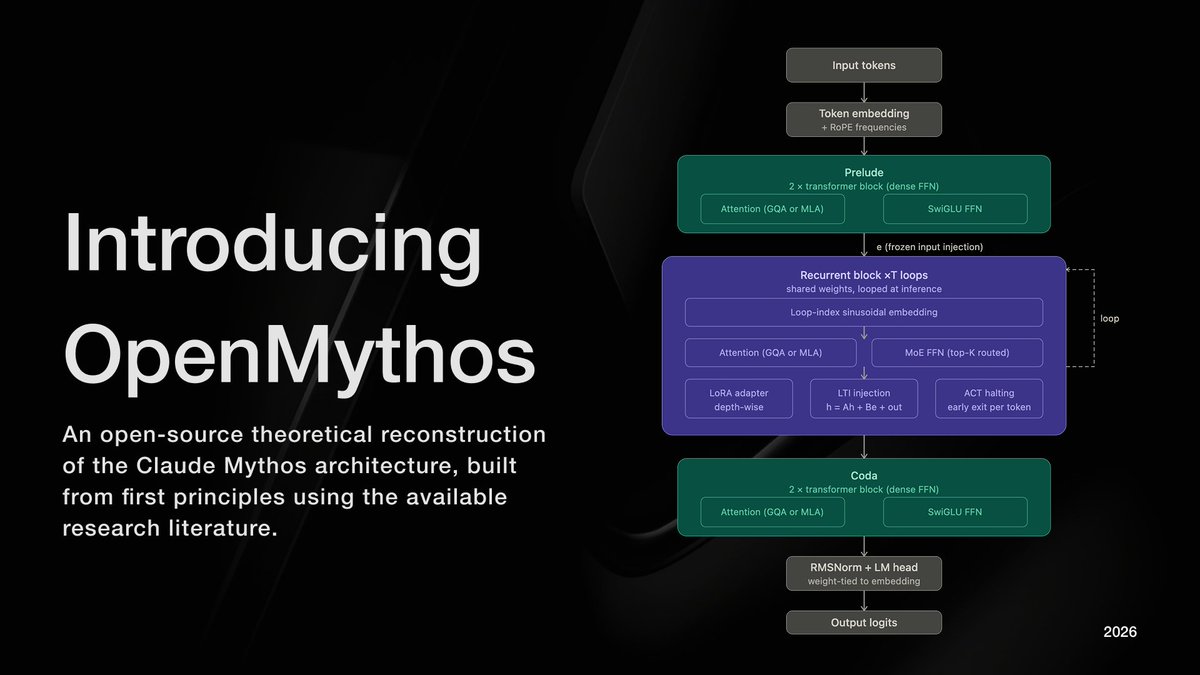
Introducing OpenMythos
An open-source, first-principles theoretical reconstruction of Claude Mythos, implemented in PyTorch.
The architecture instantiates a looped transformer with a Mixture-of-Experts (MoE) routing mechanism, enabling iterative depth via weight sharing and conditional computation across experts.
My implementation explores the hypothesis that recursive application of a fixed parameterized block, coupled with sparse expert activation, can yield improved efficiency–performance tradeoffs and emergent multi-step reasoning.
Learn more ⬇️🧵
English