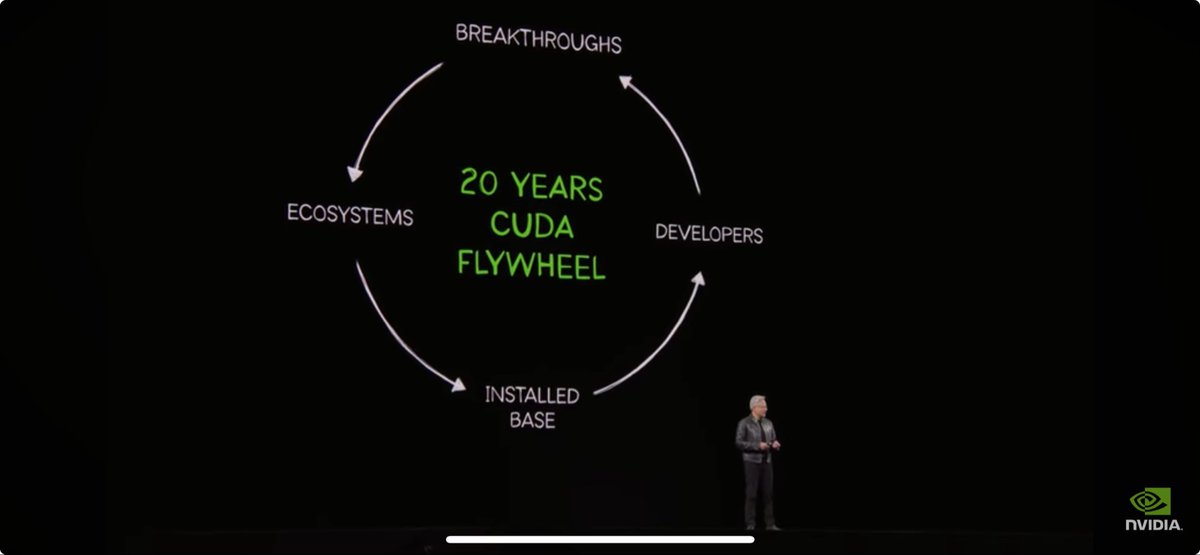
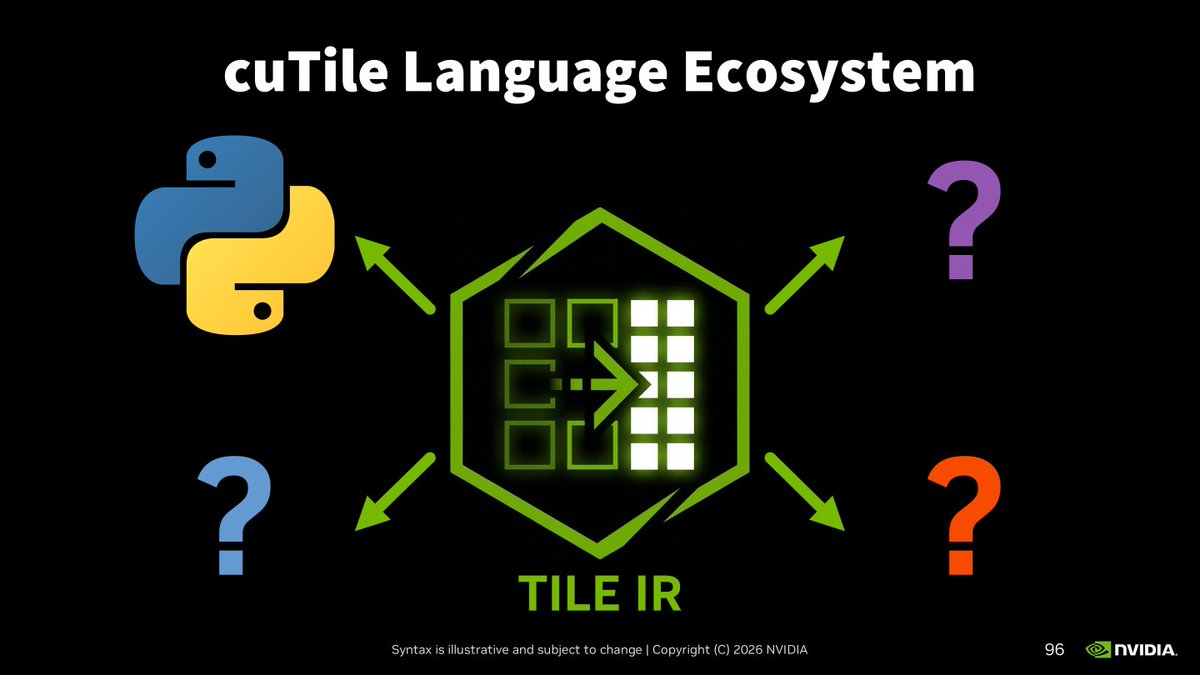
Sabitlenmiş Tweet

The latest revision of @INCITS/@isostandards COBOL comes out this year
The goals of COBOL sound normal today:
- Portable
- Freely available
- Designed by the community
In 1959 it was radical & unprecedented
It was also conceived of & led by women
This is the story of COBOL


English