@Miss_Otis @Ben_Aaronovitch I also like "Am Arsch die Räuber!"
Deutsch
Michael Tiemann (né Schober)
678 posts
@mschoberml
Research scientist @ Bosch Center for Artificial Intelligence (BCAI). Interested in all things dynamical systems and numerical solvers. Views are my own. He/him


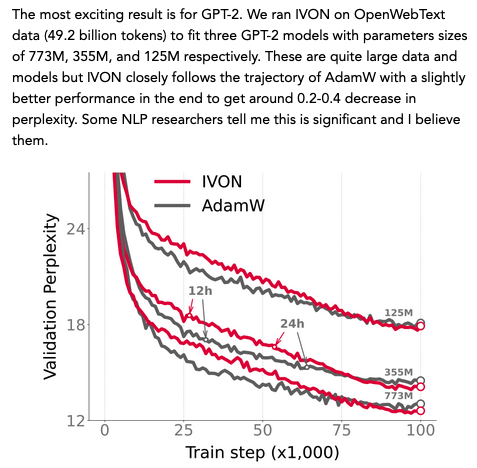





While GenAI is fun, I think its economic value is grossly over estimated, because it’s unreliable, risky and expensive to make and serve. It’s fine for creative tasks, but not (yet) autonomous agents







Anyone who thinks Auto-Regressive LLMs are getting close to human-level AI, or merely need to be scaled up to get there, *must* read this. AR-LLMs have very limited reasoning and planning abilities. This will not be fixed by making them bigger and training them on more data.