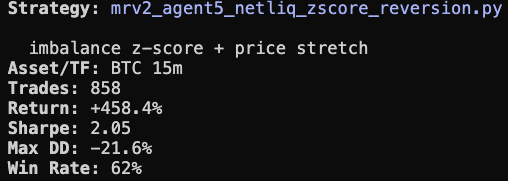
고정된 트윗

Starting this account properly today.
I use AI tools until the ugly parts show up: limits, bad runs, weird failures, wins.
I'll post Codex notes and what breaks after the demo.
No hype farm. No magic. Just notes from using the stuff.
English