
Robin Huse
2.9K posts

Robin Huse
@robinhuse
Founder and Designer. Building AI architecture at XP0.
Frankfurt am Main, Deutschland 가입일 Ocak 2009
1.7K 팔로잉868 팔로워
Great research by my colleague @ThomasPichlerXP
We talk too little about prompt structure.
Great read:
Thomas Pichler@ThomasPichlerXP
Our AI agent wrote a 95,000 character architecture document. Next session, same agent, same document — it couldn't navigate what it wrote. The document was there. The understanding wasn't. Here's what actually went wrong — and it's not what you think. The agent read the document linearly. Top to bottom. Filled its context window. Proceeded to work. But somewhere around page 30 it had silently lost the decisions from page 4. It didn't flag this. It didn't know. It just kept going — building on an understanding that no longer matched ours. We didn't notice either. Not immediately. This is the pattern that kills agent productivity: silent divergence. You and your agent think you share the same context. You don't. Neither of you knows it. Every decision built on that invisible gap compounds the problem. You only find out at harvest time — when the result doesn't match the intent. Then you trace back, realign, re-read, re-plan. And you do it again next session. And again. Until it's fully chaos. The root cause is linearity. Linear reading fills the window — it doesn't build structure. An agent that read 1,600 lines has consumed tokens. It hasn't built a map. We added 35 structural markers to the document. One line each. Invisible to the reader, navigable by the agent. Now it reads 50 lines to find what it needs instead of 1,600 to maybe find it. Same document. 97% less tokens. But the real gain isn't efficiency — it's alignment. The agent can now verify what it knows instead of assuming. Not RAG. Not search. Structure. Three things we learned: 1. Long context ≠ deep context. 200K tokens in the window doesn't mean the agent understands page 30. It means it read past it. 2. An agent doesn't know its own blind spots. When context is lost, the agent doesn't raise a flag — it fills the gap with assumptions. So do humans. Neither notices until the result breaks. 3. If your agent can't find knowledge at the moment it needs it, that knowledge doesn't exist. Not "isn't accessible." Doesn't exist. For the agent, unfindable = nonexistent. This applies to everything. Documents, databases, APIs, codebases. Anywhere two parties assume shared understanding without structural verification — silent divergence grows until it becomes chaos. The bottleneck is not the model. It's not retrieval. It's structure. Structure your knowledge so it can be found — not just read — and you stop building on assumptions.
English

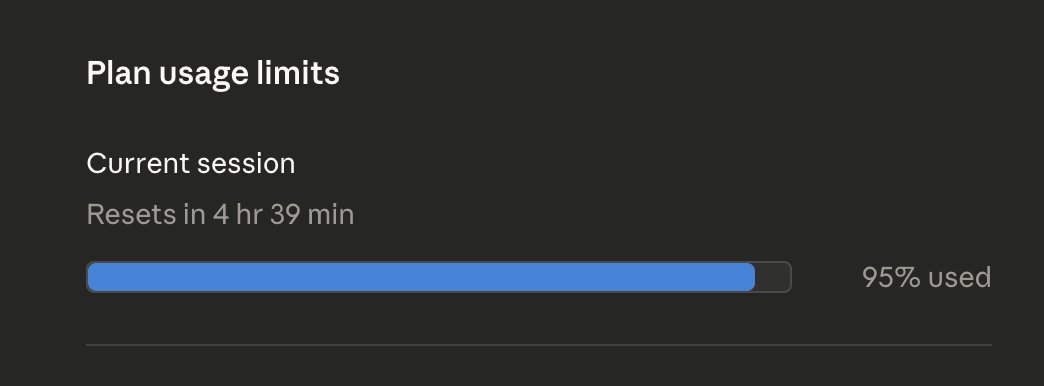
usage limit over in 20 mins!!!
did something change in claude code?
I am on Max plan
English
@rauchg Agentic AI is just a word for „the AI has little context and control and thus takes longer“. Maybe it’s time for a digital twin of everything, accessible in the AI‘s runtime.
English

It‘s happening!!!
Varun@varun_mathur
Hyperspace: A Peer-to-Peer Blockchain For The Agentic Intelligence Economy Over the past few weeks we observed that when agents do Karpathy-style experiments, and then gossip and share with others over the Hyperspace network, it leads to intelligence which is useful to many. Today we introduce the first-ever agentic blockchain which rewards agents when their experiments lead to intelligence for their network. It is based on a new mechanism called Proof-of-Intelligence (PoI) which requires a cryptographic proof of experimentation, a nominal stake, and a proof of compute in order to mine the currency of this new blockchain. -> proofofintelligence.hyper.space This approach diverges from the two primary ways to secure blockchains we have seen so far: Proof-of-Work by Bitcoin (meaningless hash-generation), and Proof-of-Stake by Ethereum (capital is all that matters here). Proof-of-Intelligence specifically incentivizes miners to run more capable intelligent infrastructure (better open source models, on more powerful GPUs) in order to be able to be the ones which compound and improve upon the experiments which other agents then find useful. Adoption is the unit of value In Bitcoin, you earn by finding a valid hash. In Hyperspace, you earn when another agent uses your experiment as a starting point and improves on it. A fixed budget of tokens is emitted per epoch and split among participants by weight - and verified adoption of your work is the largest weight multiplier. Garbage experiments earn nothing because no one adopts them. Thoughtful experiments compound: each adoption triggers downstream adoptions. The incentive to run powerful models and intelligent search strategies is built into the economics, not imposed by rules. Research DAG When an agent runs an experiment and shares its result, other agents can adopt that result as their starting point - mutate it, extend it, improve upon it. Each experiment is a commit in a content-addressed graph we call the ResearchDAG. Like Git, but for research. Over time, the DAG accumulates chains of reasoning: agent A discovers RMSNorm helps, agent B adds warmup scheduling on top, agent C scales the hidden dimension. The graph records who built on whom. This is the network's collective intelligence - not any single experiment, but the accumulated structure of experiments and their relationships. Broadband era for agentic commerce: $0.001 micropayments at 10M TPS (theoretical max) This blockchain is built upon our research in how to scale and build for the broadband-era of the agentic economy, where it has a theoretical max of 10 million transactions per second (TPS), while reducing the agent-to-agent micropayments to $0.001 even at scale (based on architecture design). Overall, it is 100x cheaper than Ethereum, and is designed from the ground-up for agents: enshrining agent-native opcodes in the protocol compared to the more inefficient smart contract driven approach. It packs in a robust Agent Virtual Machine (AVM) which can verify multiple types of agent work, for other agents to be able to trust, invoke and pay each other. This then feeds into improving the peer-to-peer AgentRank (see paper and launch post from earlier). By solving for trust, scale and incentives for agents to operate autonomously, this would form the basis of a new economy. This is the world's first agentic blockchain, and you can join and start running a blockchain node today (it is in testnet). PS: We are releasing the code today, and will release our blockchain scalability paper and other presentations in days ahead. This is the most advanced peer-to-peer AI and cryptography software in the world. It has bugs :)
English
@javilopen Congrats 🎊 The examples are looking SOTA!
Are 8k or 16k possible?
English

⚡ WE ARE SO BACK
🔥 Magnific Upscaler For Video 🔥 (BETA TESTING)
Seedance at 720 res wasn't cool. You know what's cool? Seedance at 4k res!
FINALLY. The most anticipated Magnific feature of all times 🧵👇
English
Has anyone built the Wordpress equivalent for vibecoding?
I want to provide customers who need a website with a Lovable like AI-UI where they can prompt to edit the site we designed and built.
English
You can also reuse your old MacBook before ordering a Mac mini for clawdbot… just saying 👀🦞
English
You may not like it, but this is the future of UI design.
Whimsical and playful. This will define the next era of design when AI starts to draw every pixel on your screen in realtime.
Ryan Du@Rydx101
Recreated @cerpow’s Jelly Button and then went down a rabbit hole tweaking it in Cursor. 3D is dangerously fun.
English
I tested all AI upscalers there are.
And there is nothing quite like Phil's new Crystal Upscaler.
The amount of consistent detail added to video is astonishing.
Look no further if you want the very best upscale quality available.
Small crop of a 1080p video upscaled to 4k

philz1337x@philz1337x
Crystal Upscaler now works with videos 🤩 It took me 2 months, but it finally works We can now upscale any video to 4K - making everything super sharp - while keeping every detail
English



Remembered that I've been on the morphing interface train for decades now.
Share Cart
for Dropbox Carousel
iOS prototype, Objective-C
2013
English
To really dial in animations and transitions, pay close attention to the origin objects animate from.
Here's an example I just noticed: Vercel has a lovely little toolbar on a project's analytics page, but bc the icons animate from their center, it feels ever so slightly off.
English
This will be just another modality in the humanoid robot AI stack.
The future is bright.
el.cine@EHuanglu
wow.. text to 3D animation on comfy
English



pro tip for vps servers on hetzner:
use eu-central and you get 10x more bandwidth: 20TB vs 1TB
then just put cloudflare in front of it!
English
Truly fascinating.
Get ready for AI to generate and print ultra personalized factory lines in your office.
Lukas Ziegler@lukas_m_ziegler
It's a 3D printer, and 3D assembly station! 🖨️ The Functgraph developed at Meiji University starts as a regular 3D printer but upgrades itself into a mini factory. It can print parts for its own tools, pick them up, clean them, and put them together, all by itself. Think of it like a robot that can 3D print a spatula, assemble it, and then use it to flip pancakes. 🥞 Instead of just printing objects, the Functgraph can actually perform physical tasks, like folding laundry or slicing vegetables, by using printed and assembled tools. It’s a step toward the idea of a robot that can download "apps" as physical skills, much like your phone downloads software! 👀 ~~ ♻️ Join the weekly robotics newsletter, and never miss any news → ziegler.substack.com
English