

Our AI agent wrote a 95,000 character architecture document.
Next session, same agent, same document — it couldn't navigate what it wrote.
The document was there. The understanding wasn't.
Here's what actually went wrong — and it's not what you think.
The agent read the document linearly. Top to bottom. Filled its context window. Proceeded to work. But somewhere around page 30 it had silently lost the decisions from page 4. It didn't flag this. It didn't know. It just kept going — building on an understanding that no longer matched ours.
We didn't notice either. Not immediately.
This is the pattern that kills agent productivity: silent divergence. You and your agent think you share the same context. You don't. Neither of you knows it. Every decision built on that invisible gap compounds the problem.
You only find out at harvest time — when the result doesn't match the intent. Then you trace back, realign, re-read, re-plan. And you do it again next session. And again. Until it's fully chaos.
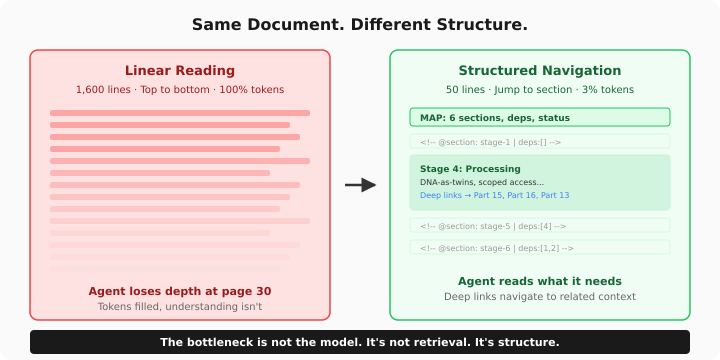
The root cause is linearity. Linear reading fills the window — it doesn't build structure. An agent that read 1,600 lines has consumed tokens. It hasn't built a map.
We added 35 structural markers to the document. One line each. Invisible to the reader, navigable by the agent. Now it reads 50 lines to find what it needs instead of 1,600 to maybe find it.
Same document. 97% less tokens. But the real gain isn't efficiency — it's alignment. The agent can now verify what it knows instead of assuming.
Not RAG. Not search. Structure.
Three things we learned:
1. Long context ≠ deep context. 200K tokens in the window doesn't mean the agent understands page 30. It means it read past it.
2. An agent doesn't know its own blind spots. When context is lost, the agent doesn't raise a flag — it fills the gap with assumptions. So do humans. Neither notices until the result breaks.
3. If your agent can't find knowledge at the moment it needs it, that knowledge doesn't exist. Not "isn't accessible." Doesn't exist. For the agent, unfindable = nonexistent.
This applies to everything. Documents, databases, APIs, codebases. Anywhere two parties assume shared understanding without structural verification — silent divergence grows until it becomes chaos.
The bottleneck is not the model. It's not retrieval. It's structure.
Structure your knowledge so it can be found — not just read — and you stop building on assumptions.
English
