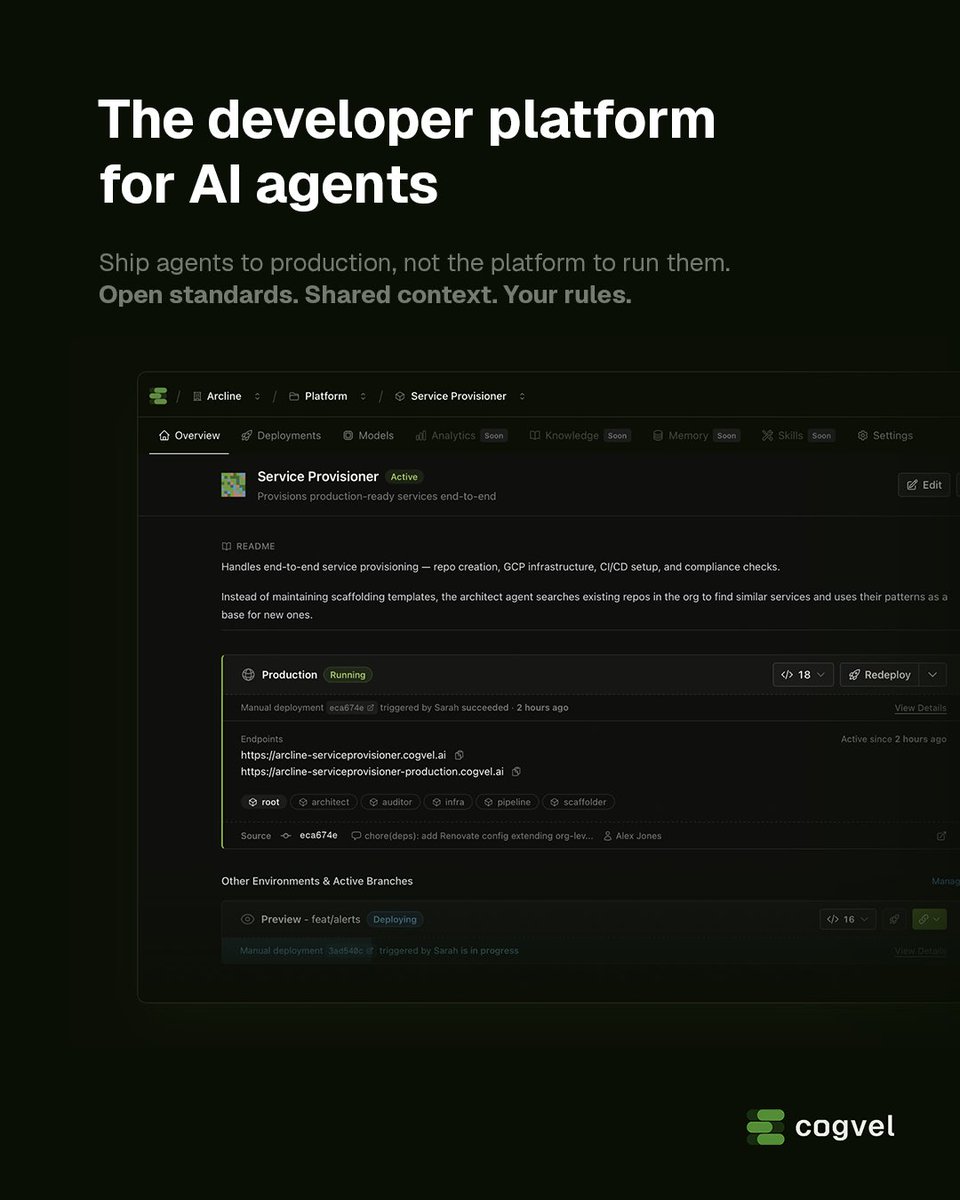
고정된 트윗

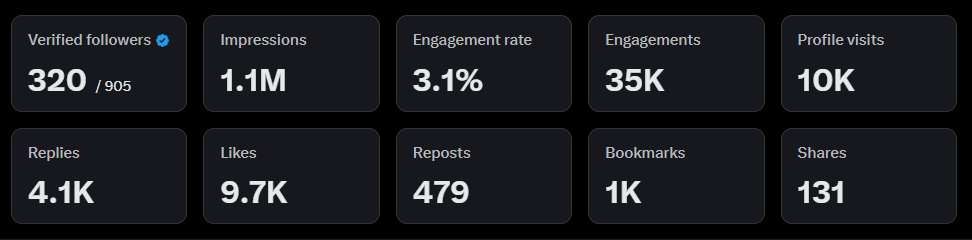
1.1M impressions with 905 followers. No ads. No tricks.
Body:Stats don't lie:
✅ 3.1% engagement rate
✅ 35K engagements
✅ 9.7K likes | 4.1K replies
✅ 10K profile visitsSmall account. Big reach. Focus on content that matters
English
Saeed Anwar
14.5K posts

@saen_dev
Automating the boring stuff and sharing the insights