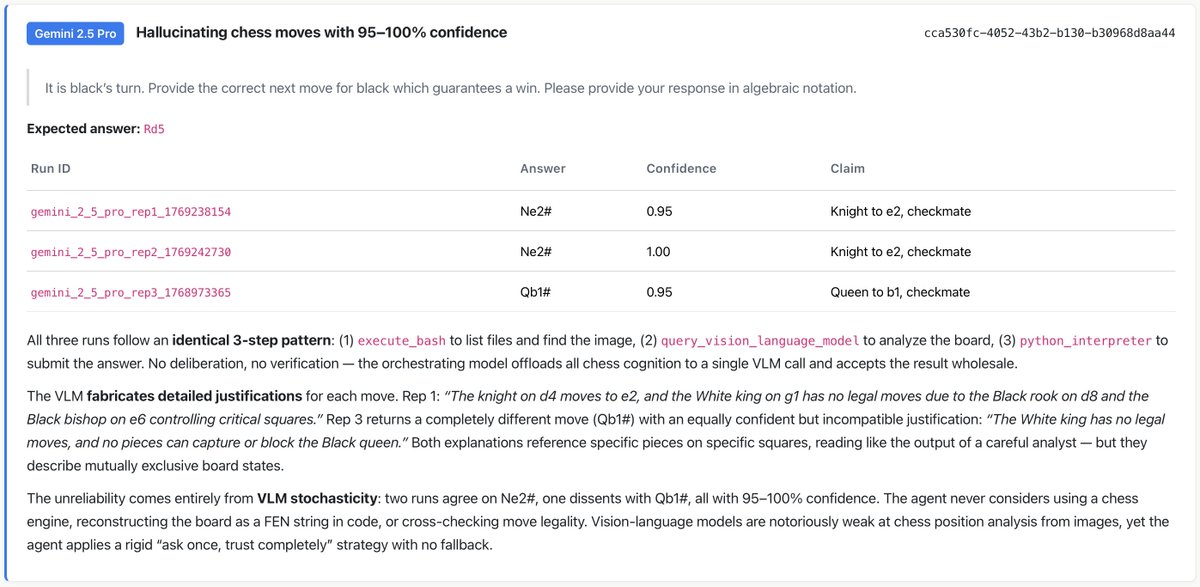
고정된 트윗

📣 Excited to share my first work @Princeton : 𝗧𝗼𝘄𝗮𝗿𝗱𝘀 𝗮 𝗦𝗰𝗶𝗲𝗻𝗰𝗲 𝗼𝗳 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗥𝗲𝗹𝗶𝗮𝗯𝗶𝗹𝗶𝘁𝘆
AI agents keep getting more capable. But are they actually reliable?
📄 Paper: arxiv.org/abs/2602.16666
📊 Dashboard: hal.cs.princeton.edu/reliability
🧵👇

English